Hi, I have been experimenting with ULMFiT for the Greek language using the standard fastai v1 features from lesson 3 without any bespoke processing.
Language Model
The Greek language model was pre-trained on a wikipedia dump of 57,956,630 tokens with a vocab of 26,952 words and resulting perplexity was 14.56 (notebook).
Classification Task
I could only find one recent SOTA NLP paper containing results on the Greek language - Building and evaluating resources for sentiment analysis in the Greek language . This has data and results for both sentiment and sarcasm analysis on tweets from around 2015 Elections. Unfortunately both data sets are small and unbalanced
Sentiment
| Class | Count | % |
|—|—|—|—|
| Neutral | 979 | 60 |
| Negative | 582 | 35|
| Positive | 79 | 5 |
Sarcasm
| Class | Count | % |
|—|—|—|—|
| OK | 1988 | 79 |
| Sarcastic | 518 | 21 |
with the SOTA result produced using 10 fold cross-validation, without any details of the folds used. As a result I used random folds, training each fold with a fixed number of epochs, choosing the model with the highest f1 score on the validation set in each fold. I am not sure if it is fair to compare my results from this to the results in the paper or not?
Results
The results are below where I tried similar approaches to the ULMFiT paper
- base (from scratch) - text_classifier_learner without a pre-trained language model
- ULM (No LM fine-tuning) - text_classifier_learner with the pre-trained language model without fine-tuning
- ULMFiT
The results averaged over each of the 10 folds are shown below along with the current SOTA from the paper.
| Task | Model | Metric | Value |
|—|—|—|—|—|—|
| Sentiment | LR (SOTA) | F1-weighted | 0.8066 |
| | base | F1-weighted | 0.8159 |
| | ULM | F1-weighted | 0.8409 |
| | ULMFiT | F1-weighted | 0.8334 |
| Sarcasm | SVM (SOTA) | F1-macro | 0.8330 |
| | base | F1-macro | 0.8275 |
| | ULM | F1-macro | 0.8466 |
| | ULMFiT | F1-macro | 0.8479 |
The results show that using pre-trained language model “significantly” improves the average f1 score, even if the size of the data set means that fine-tuning the language model does not offer any additional improvement. I think this agrees with the results in the ULMFit paper, please correct me if I am wrong.
The notebooks are on github for both the sentiment and sarcasm classification tasks. The language model and dictionary are also available.
Notes/Queries
-
The best average f1 score over the validation sets, for both classification tasks required a large number of epochs, 77 and 161 for the sentiment and sarcasm data sets respectively. This is significantly more than the 50 used in the paper. Could this be due to the size and imbalance in the data sets (the highly imbalanced sentiment data set takes 161 epochs whereas the more balanced sarcasm set takes only 77 which is nearer to the 50 used in the paper)?
-
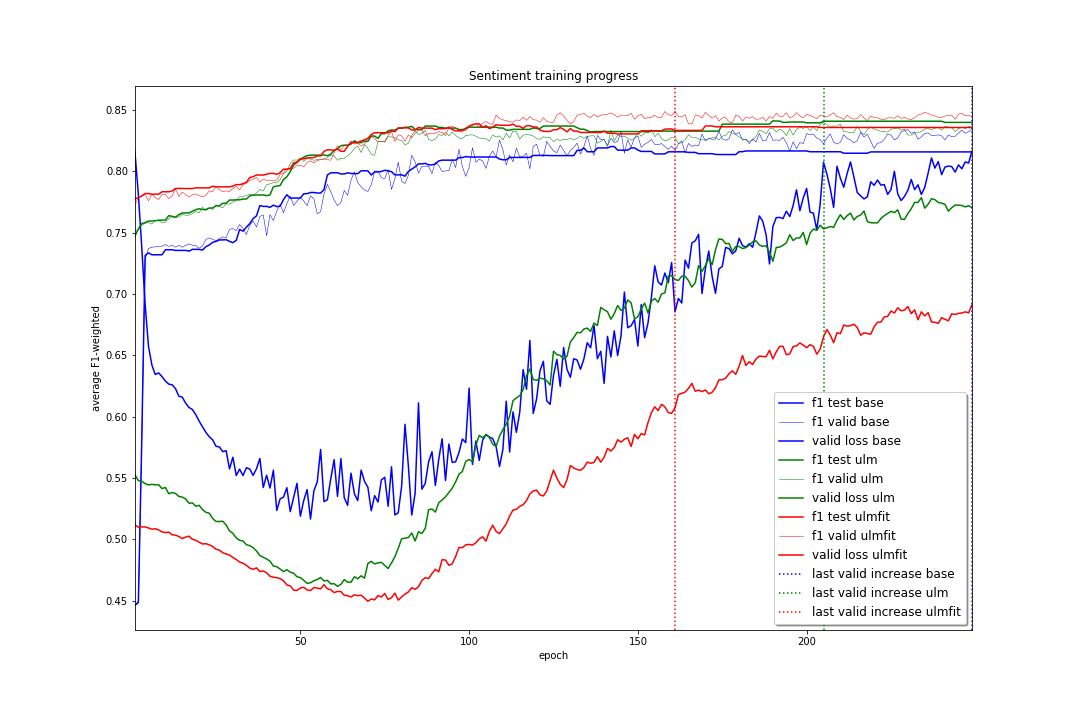
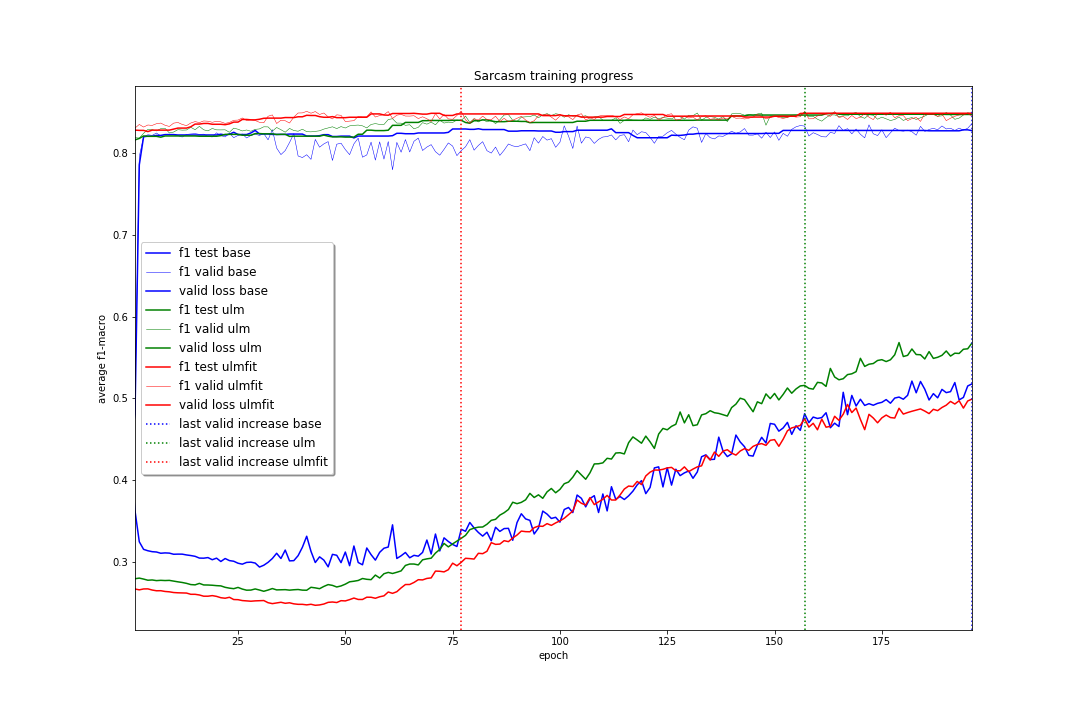
For both these classification tasks there did not appear to be “any” impact on the final f1 score from fine-tuning the pre-trained language model if a sufficient number of epochs were performed. To check to see if “everything looked ok” I examined the training progress produced by the text_classifier_learner() models in each case, shown below.
The training progress shown above agrees with what I would expect showing:- The validation loss for the ULMFiT approach is lowest over the majority of the training epochs.
- The average f1 score over the validation sets was lowest when training from scratch over the majority of the training epochs.
- The epoch where the lowest averaged f1 score over the validation sets was achieved followed a logical order
Sentiment: ULMFit (161) < ULM (205) < base (249)
Sarcasm: ULMFit (77) < ULM (157) < base (196)
which could imply some sort of convergence to the best model happens earlier for ULMFiT than for ULM which in turn converges before the base configuration.
Therefore it seems that even though the final f1 score for both ULM and ULMFiT are the “same” this is most likely down to the short length of tweets combined with the size and imbalance of the data sets.
My assumptions/implementation/approach may be wrong, so I welcome any and all feedback which can help to improve my understanding. I have tried to follow the approach laid out in