I wonder why, after engineering all these ‘Before’ and ‘After’ features, only the '‘AfterStateHoliday’, ‘BeforeStateHoliday’ features are used in training – they are listed among the “contin_vars”. But nowhere can I see the '‘AfterSchoolHoliday’, ‘BeforeSchoolHoliday’ and '‘AfterPromo’, ‘BeforePromo’ features. Am I missing something? Also, why are ‘StateHoliday_fw’, ‘StateHoliday_bw’ listed among “cat_vars”, but '‘AfterStateHoliday’, ‘BeforeStateHoliday’ listed among “contin_vars”? Anyone has any thoughts about this?
I think, to use RMSE as loss function Jeremy took log of y’s. Because of property of log(a/b) = log(a)-log(b). RMSE of log(y) will be same as RMSPE of y.
Please let me know if I am wrong.
Hello @KarlH,
I was playing around with the notebook from lesson 4 and got some test output with this code (I used n1 for the unsequeezing to get a 2D input):
print(ss,"\n")
for i in range(50):
n1 = res[-1].topk(2)[1]
n2 = n1[1] if n1.data[0]==0 else n1[0]
print(TEXT.vocab.itos[n2.data[0]], end=' ')
res,*_ = m(n1.unsqueeze(0))
print('...')
The output looks similar to this:
. So, it wasn't quite was I was expecting, but I really liked it anyway! The best
movie a worst movie i i me movie worth good . but i is not shame of <eos> do not that 's a a worst movie ever 've ever in but i 's n't good see see . anyone of people of <eos> 'm recommend recommend recommend to it movie ...
(The output includes this error message: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number.)
I’m not sure if this is correct because it looks reasonable to a very small degree and the spaces are placed incorrectly after the punctuation symbols.
Maybe the line with unsqueezing needs to be adapted that it takes 1D data?
Maybe I’ll try that later…
Best regards
Michael
Hi, I have a question regarding the dropout rate. For example if we set dropout rate to 0.5, and we have 100 nodes. Is the number of randomly chosen dropped out nodes is exactly 50 for each batch/iteration, or the probability of dropout is applied to each node separately, which means the dropped out nodes are sometimes more than and sometimes less than 50. If the latter is the case, is the activation multiplied by 2.0 exactly during training regardless of the actual number of dropout?
By nodes I believe you are referring to the number of activation units in each layer. By dropout = 0.5 and the if the number of activation units in that layer is 100 , during training roughly around 50 of the activation units output is used. Since information is lost because of this dropout, the PyTorch library
internally does scaling (if dropout = 0.5, scaling = double )of the outputs of the remaining activation units to preserve the average from the outputs of the activation units. The dropout is different for every layer, and every epoch…
1 Like
Suppose by chance 60 out of 100 units are dropped out (the probability calculated from binomial distribution is about 1% when dropout = 0.5), and only 40 are used in a given iteration, why is the scaling factor set to 2.0 = 1/0.5 rather than 2.5 = 100/40?
So when we first predict with our language model, we run the following:
# Set batch size to 1
m[0].bs=1
# Turn off dropout
m.eval()
# Reset hidden state
m.reset()
# Get predictions from model
res,*_ = m(t)
# Put the batch size back to what it was
m[0].bs=bs
We set the batch size to 1, set the model to eval, reset the hidden state, get a prediction, then set the batch size back to what it was.
Later on we run:
print(ss,"\n")
for i in range(500):
n=res[-1].topk(2)[1]
n = n[1] if n.data[0]==0 else n[0]
print(TEXT.vocab.itos[n.data[0]], end=' ')
res,*_ = m(n[0].unsqueeze(0))
print('...')
In this cell we don’t do anything with the batch size or reset the hidden state. When is it necessary to do these things? How does resetting the hidden state or changing the batch size affect prediction?
Also in the same section, we tokenize and predict on the sentence:
ss=""". So, it wasn't quite was I was expecting, but I really liked it anyway! The best"""
When tokenized, this sentence has 21 tokens. When we run that through our model, the output res is 21xvocab size matrix. To look at the next predicted word, we take res[-1], the last row, corresponding to the final word in the input sentence. Are the values in res[-1] affected by the previous rows? Or to put it another way, how does predicting on the entire sentence and taking the last row compare to just predicting on the last word?
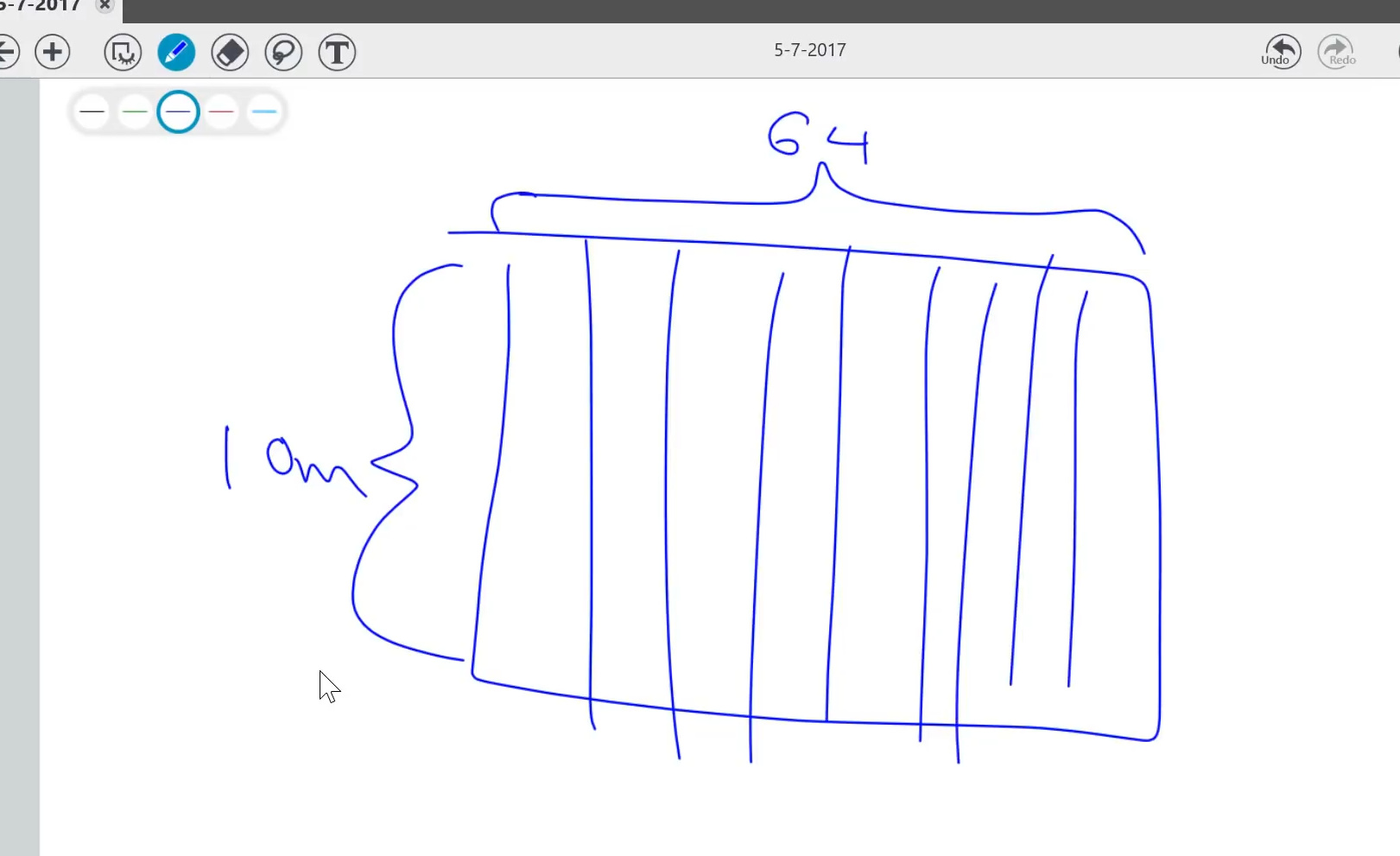
At mark 1:50:00 in the video there’s a matrix drawn for our “split” … What I don’t understand is how did we get 10million for the Y axis. I thought we’re just splitting it (from 64 mil.) so that would make it 1Mil… Or are we multiplying / augmenting everything x10 (640mil.)?
How to use ColumnarModelData for logistic regression?
1 Like
I think I figured this out. It’s not the model that’s the issue, it’s how the top prediction is chosen. You want to use torch.multinomial instead of torch.topk.
I just made a post about it here
I am not being able to understand the meaning of the three numbers appearing while training the model (Part 1 lesson 4). We are using exp_rmse as loss measurement. If the output is like this:
[0. 0.79985 0.71317 2.57642]
[1. 0.60837 0.68272 1.56165]
What is the meaning of these three numbers? What is the minimum and maximum values that these numbers can take? Is a negative value possible for these metrics? What are the other metrics available in fast.ai?
When you create one embedding matrix of 1 category, eventually a certain column of this matrix will be explaining some particular relationship between this category and the output.
If you mix multiple categories into 1 embedding matrix, you will have the same dimensionality for all categories and particular columns won’t be able to accurately capture relationships between specifically this category and the output.
He have this approach for preparind the dataframe for the model:
df_test, _, nas, mapper = proc_df(df_prepared, dependant, do_scale=True, mapper=mapper, na_dict=nas)
I wonder, why do_scale is not a part of the mapper? Isn’t it another piece of data transformation that should always be applied to all data going into the model?
Hi,
I have a question about md3 that is created in the end of imdb notebook.
I understand that we load pretrained model with m3.load_encoder(f'adam3_10_enc')
But I don’t understand what is the input and output for the model?
As far as I understand, language model is big embedding matrix, that learned connection between words and can predict next one. My question is “how random size review transforms into 1 value of prediction?”
Do we save two key words pos and neg to find that X words from review are close to one of them?
If this is true, how to use this approach for several categories? For example strong negative, negative, neutral, positive, strong positive? I assume that way to solve this is encode this categories into key-words. But is it possible to define that positive and strong positive categories are connected? They have more in common that negative ones
In order to fix the error
TypeError: sequence item 0: expected str instance, spacy.tokens.token.Token found
during prediction, replace the line
s = [spacy_tok(ss)]
with
s = [TEXT.preprocess(ss)]
That should make it work. I opened a pull-request to fix it for everyone: Fixes broken prediction in lesson 4 · Pull Request #698 · fastai/fastai · GitHub
1 Like
I personally find that the lesson 4 with entity embedding is hard to understand at the first time. It requires some data cleaning parts which is mentioned in Machine Learning lesson 1 and 2. So I suggest watching these 2 videos (about 3h) in parallel to deeper understand.
For practicing more, I am trying to work on the NYC taxi fare prediction on Kaggle, using the same approach in the lesson 4 notebook. The Kaggle’s kernel you can find here. NYC entity embeddings. If someone want to practice more this technique, you can fork it and continue to improve
It is at top 45% at the moment. I currently used very few rows (800000) while the total rows is 50M (my score didn’t improve much even when I used more rows). I will try to read others kernel to see how they create more features.
Hope to receive feedbacks  , thank you
, thank you
1 Like
Hello - If I wanted to repurpose the model illustrated on the Rossmann dataset for binary classification, how would I do that? I’m guessing there is a way to adjust the activation function in the last layer of the model, but how to code that is eluding me.
1 Like
I have a couple of questions about categorical variables.
-
What are the implications of using the index of the category as a numerical input? So if Monday through Sunday are assigned categories through 0 through 6, can we have a “dayOfWeek” continuous variable and have its value as 0 if its a Monday, 1 if its a Tuesday and so on. How would this approach compare vs one-hot encoding and vs embeddings?
-
Can the embedding of categorical variables approach also be applied to Random Forest or Logistic Regression models? (I assume not, because there’s no backprop that would update the embeddings since they are a part of the input, but I just want to make sure I’m thinking in the right direction)
After trying the other fixes here, I’m still having a problem with spacy.load('en') throwing an error on Paperspace:
…
OSError: [E050] Can’t find model ‘en’. It doesn’t seem to be a shortcut link, a Python package or a valid path to a data directory.
It looks like spaCy is looking for the path to tokenizer, which ‘en’ should be a symlink to. For whatever reason the /opt/conda/lib/python3.6/site-packages/spacy/data/en/en_core_web_sm-2.0.0 directory where tokenizer lives on my system is installed 1 directory too deep, even after uninstalling and reinstalling spaCy.
I got this line of the Jupyter notebook to work by changing
spacy_tok = spacy.load('en')
to the full explicit path:
spacy_tok = spacy.load('/opt/conda/lib/python3.6/site-packages/en_core_web_sm/en_core_web_sm-2.0.0')
This fixed the first instance of spacy.load('en'), but the notebook broke again on the
TEXT = data.Field(lower=True, tokenize="spacy")
line, where spacy.load('en') is called internally.
I tried unlinking the /opt/conda/lib/python3.6/site-packages/spacy/data/en and relinking it to the correct directory: /opt/conda/lib/python3.6/site-packages/en_core_web_sm/en_core_web_sm-2.0.0/ with
ln -s /opt/conda/lib/python3.6/site-packages/en_core_web_sm/en_core_web_sm-2.0.0 /opt/conda/lib/python3.6/site-packages/spacy/data/en
restarted the kernel, and went back to spacy.load('en'), but got the same error I initially saw.
Any suggestions?
Ah - I think I answered my own question. I forgot to do
. activate fastai
in a shell before doing
python -m spacy download en
Doing it in that order fixed the problem.