I have a question regarding shifting the word vectors by 1 while creating the batches for the text classification problem. When the word matrix of 75*64 was created after the text corpus was broken down into 64 batches and then bptt of 75 was used then why did we move the vector by one sentence before flattening the array. Shouldn’t first row be missed always this way ?
I noticed Jeremy mentions in this lecture that he will not go too deep into text generation problem. Is there a future lesson or forum posts which show how to use fastai on some of the text generation problems?
Thanks!
For those that cannot easily run the python -m spacy download en command. I was able to use en_core_web_sm, as follows:
import en_core_web_sm
spacy.tok = en_core_web_sm.load()
later make sure to use:
TEXT = data.Field(lower=True, tokenize=“en_core_web_sm”)
and modify utils.py to include the “en_core_web_sm” in the if-elif section (something very similar to the spacy section of code will do)
I really want to know how to apply it to random forest too.
I have extracted the weights correspond to that categorical variable.
but I am not sure how to feed it into a sklearn regressor.
Concat a list of weights and feed it in gives error about sequence and shape.
I attempted my own custom nn module and inserted into the lesson3 notebook but the results are much worse with the same network parameters. What am I doing wrong?
class net2 (torch.nn.Module):
def __init__(self,dftrain,dfvalid,trainY,actual,contin_vars,cat_vars):
super(net2,self).__init__()
self.n,self.nv,self.contin_vars,self.cat_vars=dftrain.shape[0],dfvalid.shape[0],contin_vars,cat_vars
y=trainY[:,None]
yv=actual[:,None]
x_c,xv_c=self.normalize_inputs(dftrain,dfvalid,contin_vars)
x_cat,xv_cat=dftrain[cat_vars].values,dfvalid[cat_vars].values
self.contin_vars,self.cat_vars=contin_vars,cat_vars
self.x_c,self.x_cat,self.xv_c,self.xv_cat=x_c,x_cat,xv_c,xv_cat
self.x_c=torch.FloatTensor(self.x_c)
self.x_cat=torch.LongTensor(self.x_cat)
self.xv_c=torch.FloatTensor(self.xv_c)
self.xv_cat=torch.LongTensor(self.xv_cat)
self.y=torch.FloatTensor(y)
self.yv=torch.FloatTensor(yv)
# Embedding Layer for categorical
emb_dims=[]
num_weights=0
for i,myNm in enumerate(self.cat_vars):
num_codes=len(torch.unique(self.x_cat[:,i]))+1
cats=min(50,num_codes//2)
emb_dims.append((num_codes,cats))
num_weights+=cats
print (myNm, num_codes, cats)
self.emb_dims,self.num_weights=emb_dims,num_weights
self.define_architecture()
self.initialize_parameters()
if 1==0:
self.calculate_loss()
self.backward()
def initialize_parameters(self):
for i,emb_layer in enumerate(self.emb_layers):
emb_layer.weight.data.uniform_(0,0.05)
torch.nn.init.normal_(self.linear_3.weight,0,0.05)
torch.nn.init.normal_(self.linear_3.weight,0,0.05)
torch.nn.init.normal_(self.linear_4.weight,0,0.05)
def forward(self,cats,conts):
# Embedded layer followed by Dropout
x = [emb_layer(cats[:,i]) for i,emb_layer in enumerate(self.emb_layers)]
x=torch.cat(x,1)
x=self.dropout_1(x)
# Batch norm for Continuous
#x_c=self.batchnorm_1(conts)
x=torch.cat([x,conts],1)
# Linear followed by Dropout
lin2=self.linear_2(x)
#dropout2=self.dropout_2(lin2)
relu2=self.relu_2(lin2)
# Linear followed by Dropout
#lin3=self.linear_3(dropout2)
lin3=self.linear_3(relu2)
#dropout3=self.dropout_3(lin3)
relu3=self.relu_3(lin3)
# Linear
lin4=self.linear_4(relu3)
#lin4=self.sigmoid(relu3)
return lin4
def define_architecture(self):
# Embedding layer followed by dropout
self.emb_layers = torch.nn.ModuleList([torch.nn.Embedding(x, y)
for x, y in self.emb_dims])
self.dropout_1=torch.nn.Dropout(0.04)
# Continuous Layer followed by batch norm
self.batchnorm_1=torch.nn.BatchNorm1d(len(self.contin_vars))
self.linear_2=torch.nn.Linear(self.num_weights+len(self.contin_vars),1000)
self.relu_2=torch.nn.Dropout(0.001)
#self.relu_2=torch.nn.ReLU()
self.linear_3=torch.nn.Linear(1000,500)
self.relu_3=torch.nn.Dropout(0.01)
#self.relu_3=torch.nn.ReLU()
self.linear_4=torch.nn.Linear(500,1)
def normalize_inputs(self,dftrain,dfvalid,contin_vars):
self.mymeans = dftrain[contin_vars].apply(np.mean,axis=0)
self.mysds = dftrain[contin_vars].apply(np.std,axis=0)
mymeans_np=self.mymeans[None,:]
mysds_np=self.mysds[None,:]
x_c=dftrain[contin_vars].values
xv_c=dfvalid[contin_vars].values
if 1==0:
x_c=x_c-mymeans_np
x_c/=mysds_np
xv_c=xv_c-mymeans_np
xv_c/=mysds_np
return x_c,xv_c
followed by:
net=net2(dftrain,dftrain,trainY,trainY,contin_vars,cat_vars)
optimizer=torch.optim.SGD(net.parameters(),lr=1e-3)
bs=128
num_batches=np.int(dftrain.shape[0]/bs)
last_batch_size=dftrain.shape[0]-num_batches*bs
for epoch in range(1):
start=0
for t in range(num_batches+1):
start=t*bs
if t==num_batches:
end=start+last_batch_size
else:
end=(t+1)*bs
y_pred=net.forward(net.x_cat[start:end,:],net.x_c[start:end,:])
loss=loss_fn(y_pred,net.y[start:end])
if (t%1000==0):
print (t,loss.item())
loss.backward()
optimizer.step()
optimizer.zero_grad()
y_pred=net.forward(net.x_cat,net.x_c)
#yv_pred=net.forward(net.xv_cat,net.xv_c)
print (epoch, exp_rmspe(y_pred,net.y).item())#, exp_rmspe(yv_pred,net.yv).item())
I’m from China and I can’t watch the video. what can I do?
@ayushchd For the first part, please refer to this brilliant notes from hiromi and search for ‘What is the advantage of using embedding matrices over one-hot-encoding?’.
And to the second part, yes embedding can be used in RF or Logistic regression but not directly. First these embedding need to generated/learned using a NN and then these can be used as features in RF or LR.
Number of features used for representing each categorical variable will be equal to the dimension of the embedding.
Hope this answers your questions 
Hi, guys, there’s also a thread here Lesson 4 IMDB Test Part Fails. I think this is related to pytorch 0.4, seems like unsqueeze behavior changed
Hi there.
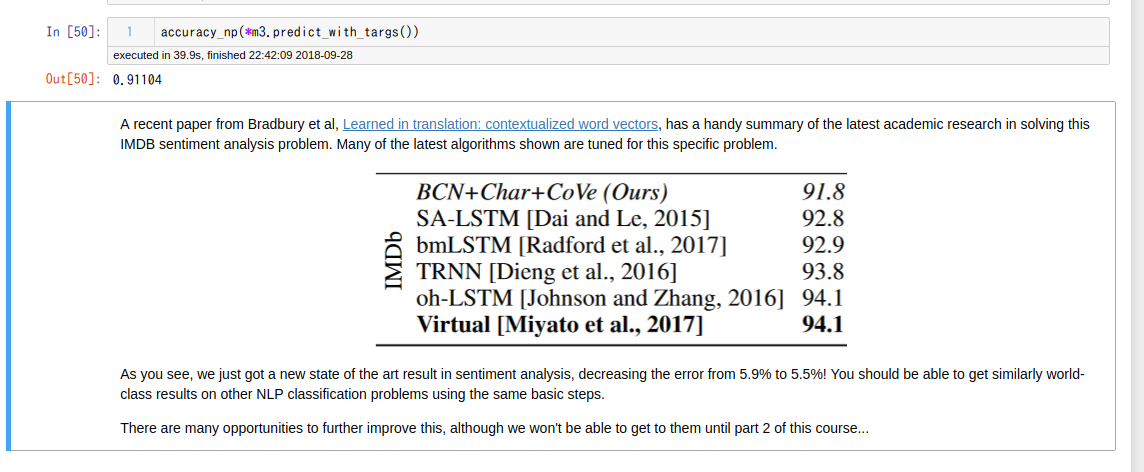
I recaped Lesson 4 and ran all the cells in notebook.
However, the resulting model performed worse marginally (got 91.8% accuracy) in sentiment (last section).
Could anyone give me a piece of advice?
concat_csvs(‘googletrend’)
concat_csvs(‘weather’)
I don’t quite understand but when i run these two codes, the csv files got pretty huge and didn’t stop until when i force it.(more than 130 gb) There is some kind of recursive problem probably. it killed my first google cloud instance. Just a reminder, i think they are not supposed to be run.
Currently testing the entity embedding technique to solve a multi time series problem (similar to rossman) at work. Below is the outcome.
epoch trn_loss val_loss exp_rmspe
0 0.119941 0.024493 0.16583
1 0.029851 0.022852 0.156527
2 0.021698 0.018423 0.137473
...
...
17 0.005967 0.009974 0.096476
18 0.00735 0.010214 0.096689
19 0.005758 0.00952 0.093819
[array([0.00952]), 0.09381856993043287]
It looks good (i think), so I’m planning to put the model in production.
Is there any reference/guide on doing this? In particular:
- Do i need to save the embeddings separately, or is it stored along with the model in the h5 file (after running m.save() ) ?

2. Once I load the model will I need to use fastai library for preprocessing (I’m currently using fastai 0.7. Do I need to use proc_df? Can I just use pytorch ?) ?
3. And lastly, how does one actually do prediction (where do i insert the input data) after loading the model?
Thanks.
2 Likes
Hi, I’m getting this error when I try to run the notebook in kaggle or google colab, 'ModuleNotFoundError: No module named ‘fastai.learner’.
And you can’t install a custom package in kaggle kernel w/ GPU mode on, so How can I install the custom package of fastai in google colab ?.
Hey, can anyone explain to me why he is using logarithms in the rossman example?
He turns y into yl using np.log(y), but then whenever the metric function (exp_rmspe) is called he just reverts y to its original value with np.exp(a).
What is the point of turning y into log values?
2 Likes
Hi,
I am using the fastai v1 installed on the Google cloud “Deep learning VM”. (followed this guide)
The notebook is a bit more updated than the one on the lecture, and pretrained language model is used.
However, I want to train my own language model on a bunch (~7 Gigs) of text files.
As far as I understand, language model require no label (since they predict the next word), yet when I try to run the IMDB example - I get an assertion error:
I replaced
data_lm = text_data_from_csv(Path(IMDB_PATH), data_func=lm_data)
with
data_lm = text_data_from_folder(Path(MY_PATH), data_func=lm_data)
And I get an assertion error on this line :assert(len(classes)>0)
What am I missing ? why is there a number of classes invloved when training a lang model ?
1 Like
Hi, good one.
But i have one question when we use this technique for forecasting let say we take year also as categorical variable and now if i have to forecast for 2019 even though we don’t have embedding vector for it. How we will do that
The notebook is working for me on google colab. Use:
!pip install fastai==0.7.0
!pip install torchtext==0.2.3
Hi, I am new to pytorch and fastai library, watching dl-1 videos.I did not get one thing, when we are training the model to understand english by predicting the next word in a sentance where did we tell the model about what are the outputs for a given input sentence(traning dataset)?
1 Like
Thanks, it works now
Hi everyone, i was trying to apply the modification of the code for structured data in a different dataset. However when i run m.predict(TRUE) it gives me an error that running_mean should contain 6 elements not 4. I cant figure out what is the problem. I am working on kaggle kernel with 10% of the dataset since it contains 4 million rows. Please help anyone. @jeremy
P.S. : It requires around 20 mins to run one epoch on 20% of the dataset and batch size :128.
Should i increase the batch size to reduce the time required because i have seen in the fastai videos that it takes couple of minutes or so to run the codes.
Please help.
FWIW, I just stepped through the Lesson 4 notebook as well, and got an accuracy of 91.3%. It would be interesting to hear if others are seeing results closer to what Jeremy showed in the video. 