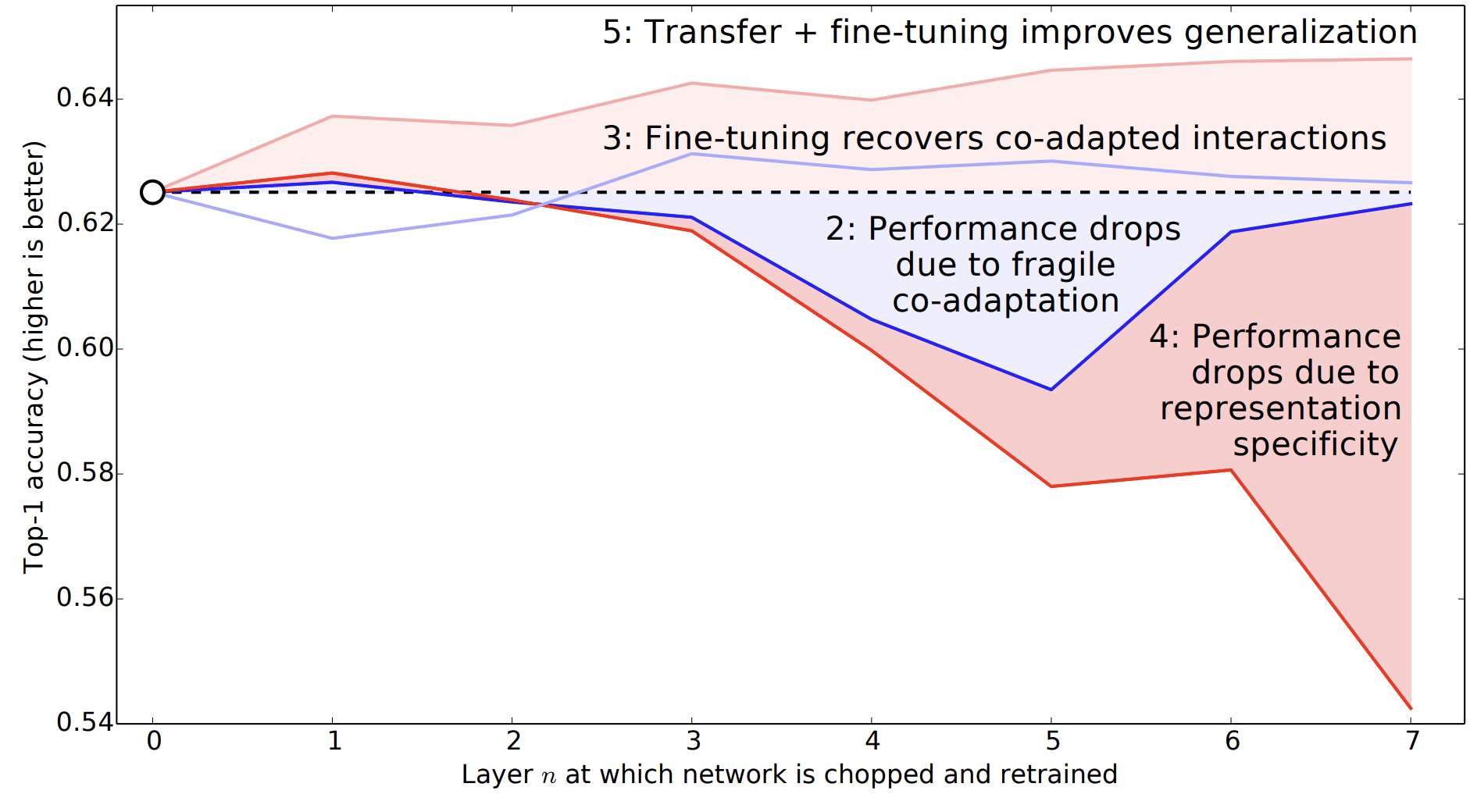
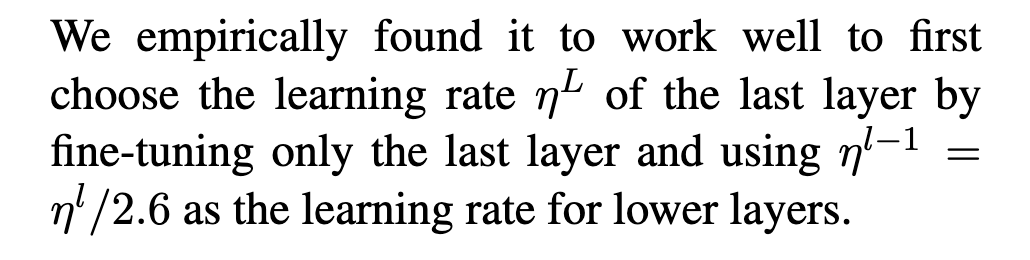Following are the steps to train a good model.
1. Load the model.
By default when you load the model from fastai library, it will have all the layers frozen i.e pre-trained weights, say resnet (or any other preatrained model) won’t get modified.
If you print
learn.summary()
you will find most of the starting layers are set to trainable=False.( (i.e. requires_grad=False ).)
So you don’t need to explicitly say
learn.freeze()
you can directly start training using
‘’‘python
learn.fit_one_cycle()
‘’’
 Note: This is the case with fastai library only.
Note: This is the case with fastai library only.
If you use plain Pytorch, you need to freeze the initial layers before training.
2. Freeze the initial layers
What freezing does?
learn.freeze()
not required if using fastai library.
Freezing basically prevents well-trained weights from being modified, that’s called transfer learning. (i.e. requires_grad=False ).
Gradients are not calculated for those layers.
There are layer groups in any model architecture
you can see that by
learn.model
The initial layers are mostly used for understanding low-level features like curves, lines, shapes, patterns. When we use pre-trained models they are trained for identifying these features on a large dataset of images like Imagenet(1000 categories).
the later layers are mainly for capturing high-level features on current dataset like pets.
These are fully connected layers which identify features like the shape of a dog or cat in its entirety.
These layers hold composite or aggregated information from previous layers related to our current data.
We improve information captured by these layers by training the model and optimizing loss based on target labels.( (i.e. requires_grad=True ).)
Read this paper.
Check here for more info
3. training model
learn.fit_one_cycle(2)
Train only the last layer group i.e fully connected layers. don’t train longer because you might overfit.
a) use lr_find() before fit_one_cycle() to get best suited learning rate for underlying data.
4. Unfreeze the layers
learn.unfreeze()
All of the layers are trainable =True now.
It sets every layer group to trainable (i.e. requires_grad=True ).
Model is getting retrained from scratch.
All weights from frozen layers of the model now can get updated from their pre-trained state according to loss function. (Thanks for suggesting better edit @Daniel )
you can change this behavior by instead using freeze_to() method which allows you to keep some layers frozen.
5. training model
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))
Make sure to use discriminative learning rates here(parameter max_lr), which maintains a low learning rate for initial layers as they need lesser tuning and gradually increase learning rate for later layers which need higher tuning especially fully connected ones.
a) use lr_find() before fit_one_cycle() to get best suited learning rate for underlying data.
6. Saving model parameters
learn.save()
Starting from layer 1 to layer n all the weights are saved.
Architecture is not saved so you have to define the same architecture in order to use these weights again.(freeze/ unfreeze details are not saved.)
Read more here -
- Understanding freeze()
- Recently @Daniel ran a kernel with experiments for freeze() function
Hope this helps  .
.