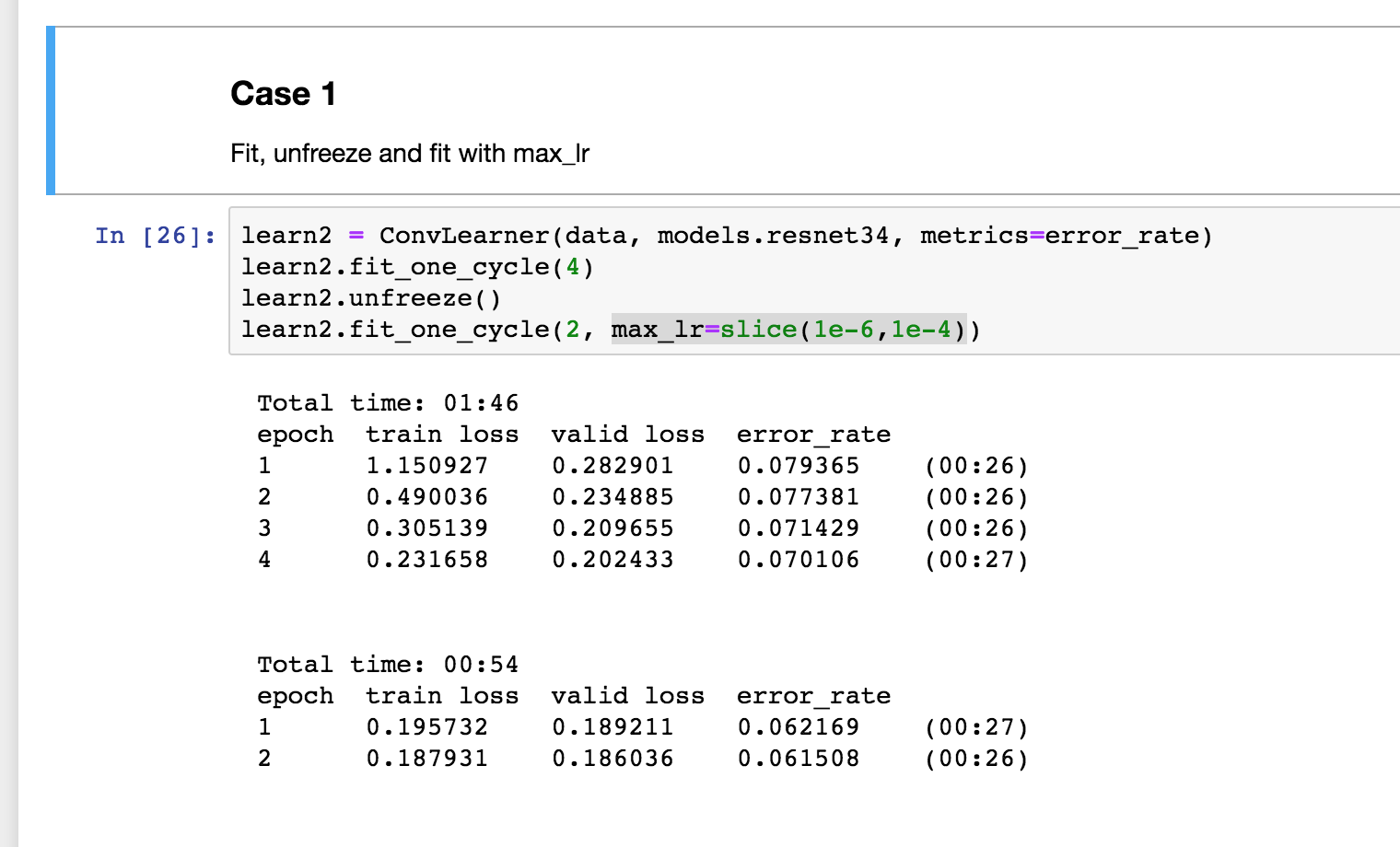
It is the ideal way of training model. When you initialize the Conv learner, the last layers have randomly assigned weights and the initial layers have weights pretrained on Imagenet. By default layers that are already trained are freezed ( won’t be trained until you unfreeze them ). So when you fit first you are training only the last layers. Then you unfreeze all the layers, now when you fit all layers get trained. And what max_lr does is, instead of apply the same learning rate to all the layers, it applies different LR across the layers. So for initial layers it is low and high for the last layers.
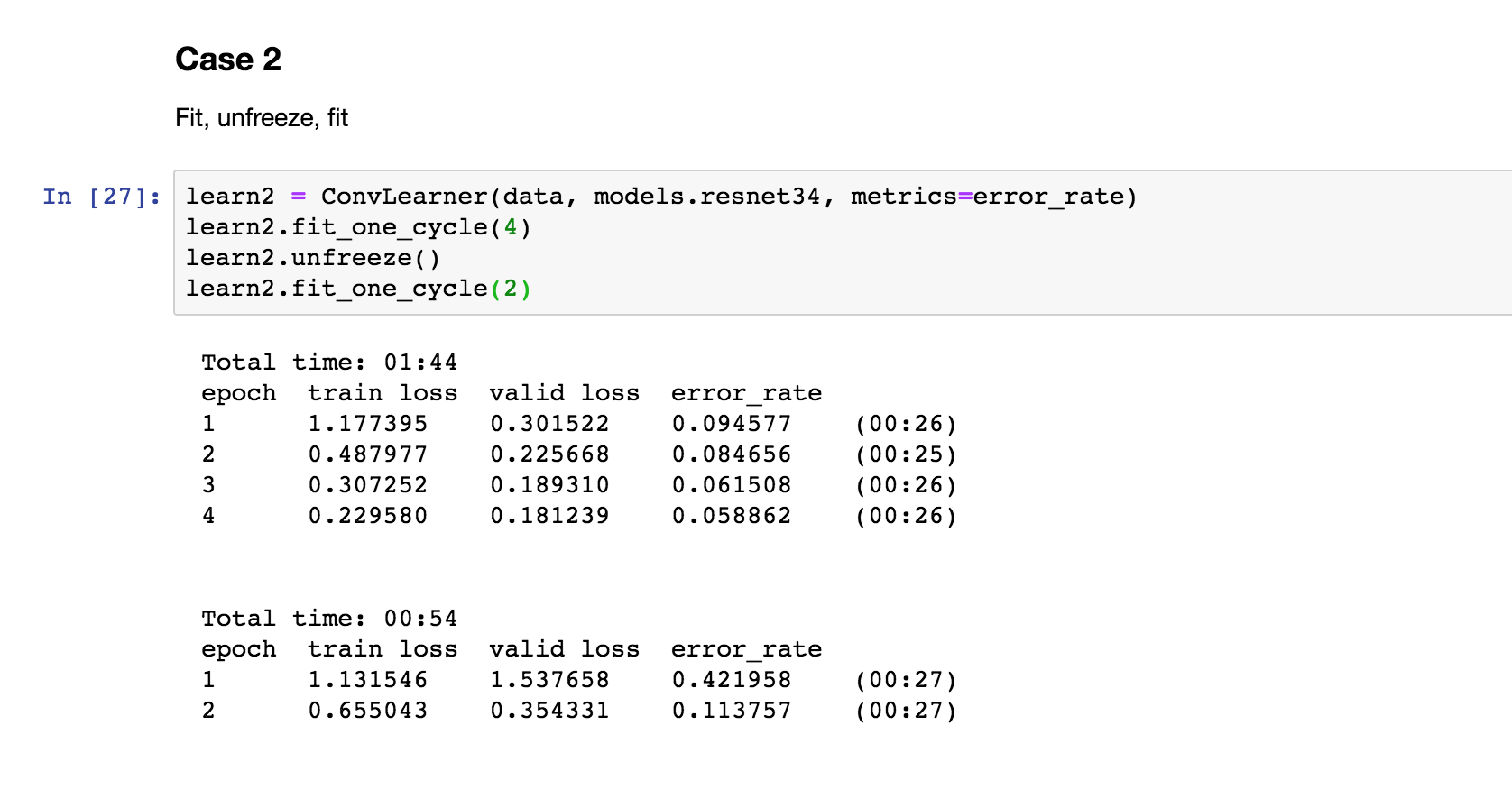
Case 2
Almost same as the above. But without max_lr you are applying same LR across all the layers. That is why error rate is high. Ideally initial layers are already trained, therefore LR is too high for them.
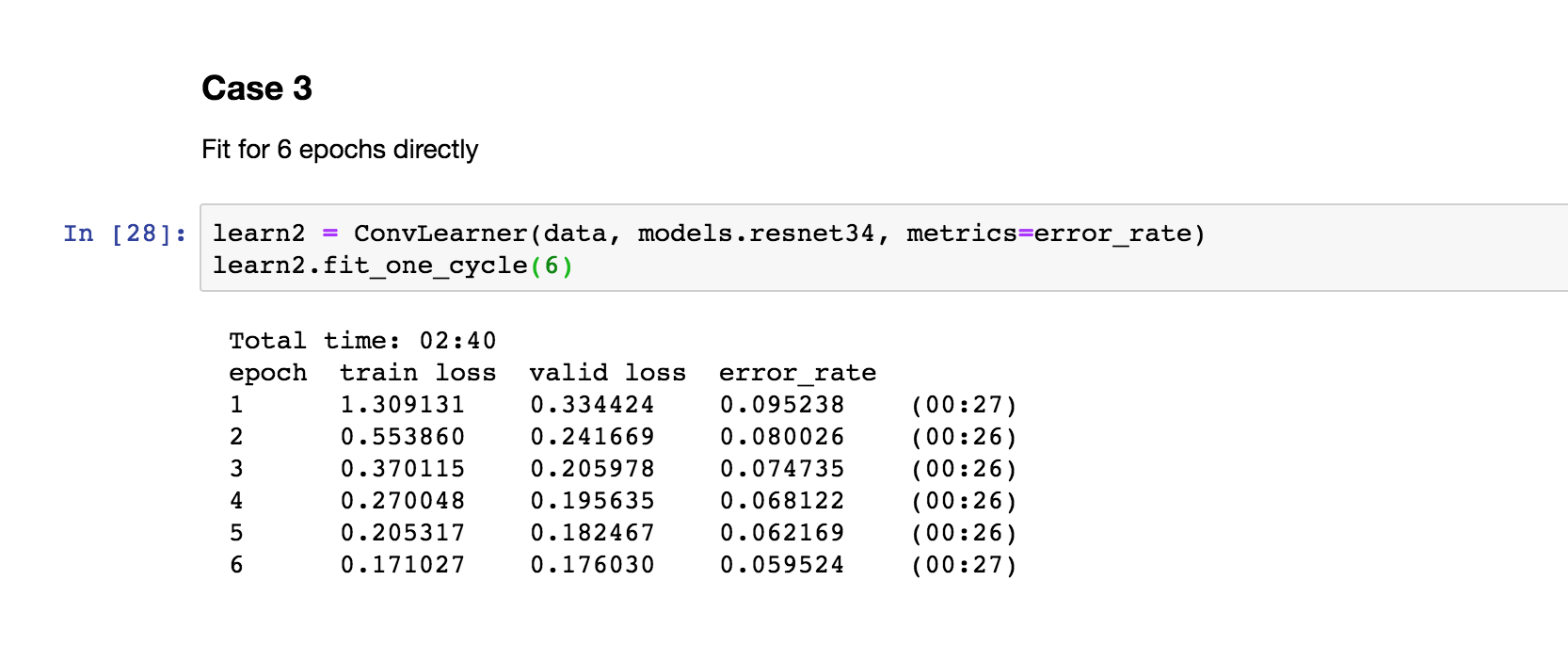
Case 3
Training only happens in the last layers as other layers are fixed. You should avoid training for long as it may overfit your model.
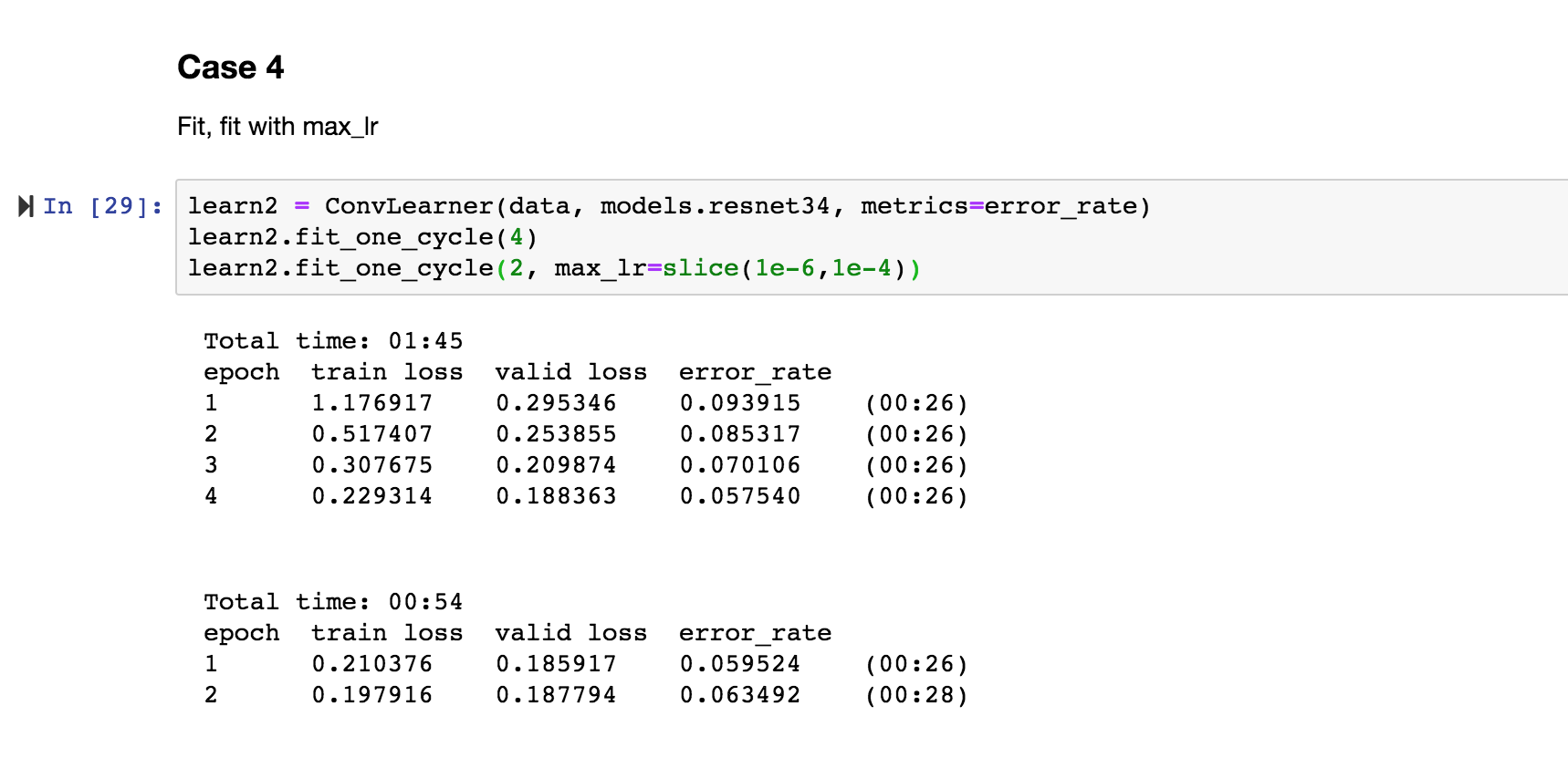
Case 4
As the initial layers are fixed. So only the last layers are training but not sure what max_lr is doing in this case.
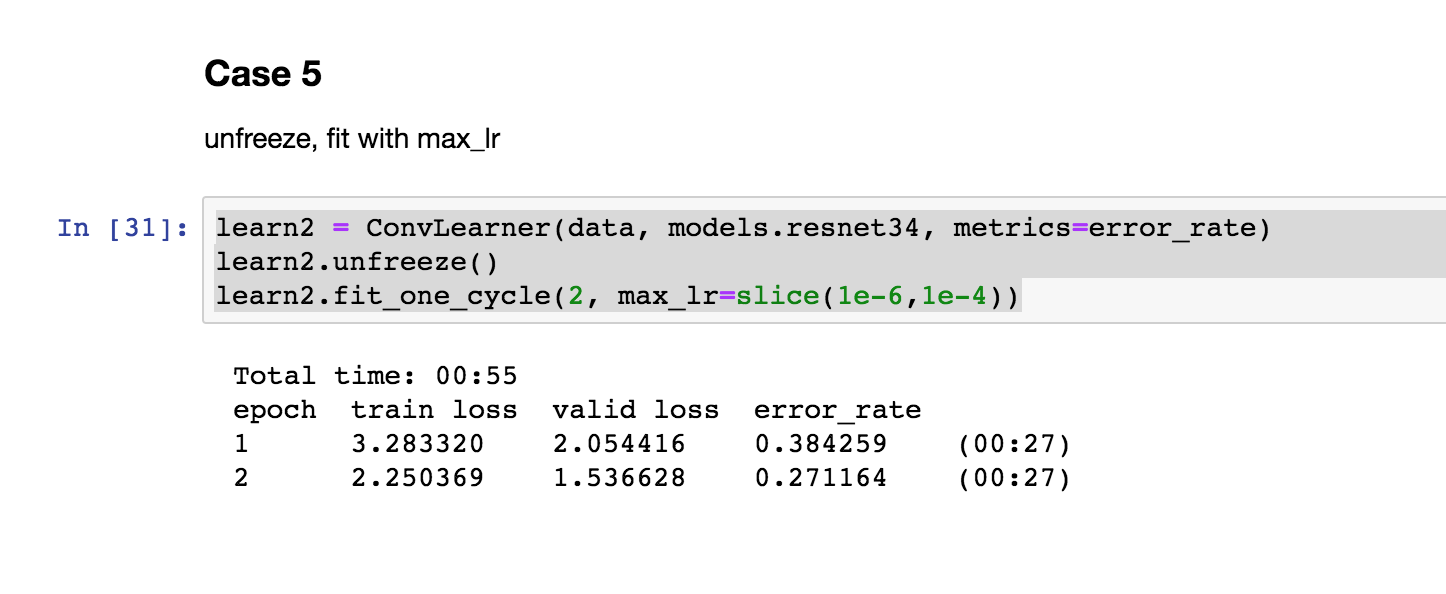
Case 5
Training all the layers from the starting. It will work, but because the last layers are randomly assigned, it will give high error in the beginning
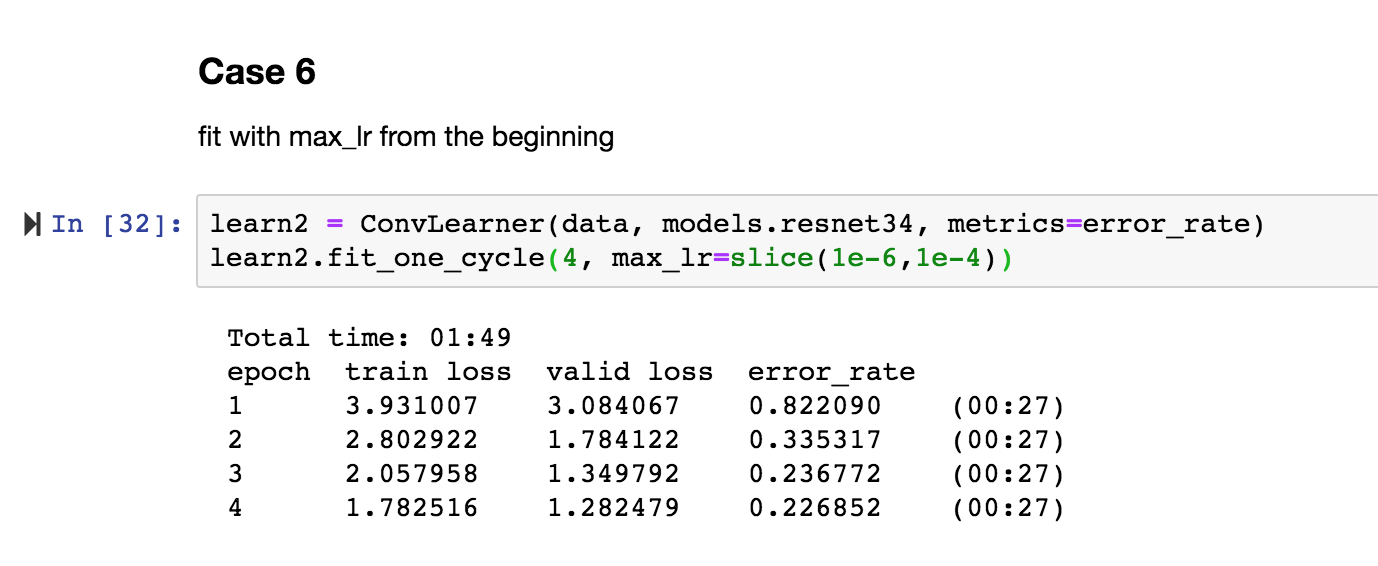
Case 6
Same as the case 4 , only last layers are getting trained.
@arunoda adding to the excellent reply from @isarth u can find the appropriate learning rate before every fit step using lr_find and use those value appropriately in the immediate fit/training step