Thanks for these. By following citations I stumbled on this very recent review (september 2018) of DL for Time Series Classification.
It’s 50 pages, tests many methods and compares them on all the UCR datasets. It’s also a great review of the SotA non-DL techniques.
TL;DR: ResNet & FCN are the best “Single Model” Classifiers they tested. They are outpeformed by COTE which is an ensemble of techniques.
ResNet and FCN outperform other DL techniques (although they didn’t test any Recurrent approaches like the Dilated RNN paper you linked):
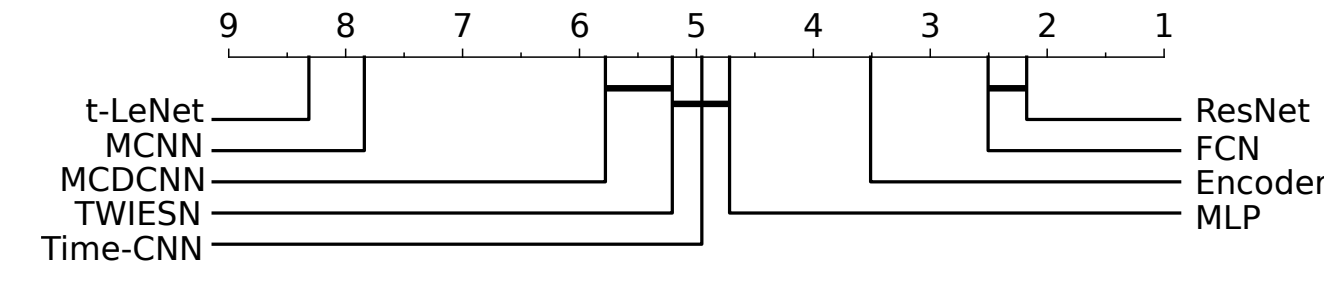
(right side/lower number is better performance)
COTE is the only non-DL outperforming ResNet:

(right side/lower number is better performance)