
I have not had time to look into the ‘dimension shuffle’ question, but will do as soon as I can.
From my side I’ve been briefly testing the transfer learning approach, but performance is also around 76%.
It won’t be easy to beat the sota but there are still many things to try.
By the way, when you are comfortable with your LSTM-FCN implementation, I have an idea to try an see if we can improve performance. We can chat about it if you are interested.
I’m running the author’s code to reproduce the 83.5% and the training started with the following bad omen:

I don’t want to be presumptuous, but it looks like the authors may have inverted the train and test datasets.
What’s confirming my doubts is that
- the “all 0” strategy for the training dataset is around 82% accuracy, meaning their result is essentially equivalent to our 76%
- the training loss/validation loss profile when I run their training code is exactly similar to what happens when I train using my pytorch model: massive overfitting, and oscillations around the “all 0” accuracy for the validation
[EDIT]: looks like they also “cherry-pick” the best epoch out of their (2000!) training epochs based on the validation set - several other ppl commenting negatively on that in this closed Github Issue on their repo. Oh academia.
5 Likes
Wow, extremely interesting finds! I was just at a talk this week where they mentioned the bad science and “reproducibility crisis” in deep learning… Maybe you just found another example of that…
1 Like
Yes, this is truly amazing! Thanks a lot for sharing @henripal!
So if your run the code in the correct way, the result is basically the baseline, isn’t it? If so, their solution is totally useless.
If we are learning something important with this competition is the importance of reproducibility!
2 Likes
Thanks for these. By following citations I stumbled on this very recent review (september 2018) of DL for Time Series Classification.
It’s 50 pages, tests many methods and compares them on all the UCR datasets. It’s also a great review of the SotA non-DL techniques.
TL;DR: ResNet & FCN are the best “Single Model” Classifiers they tested. They are outpeformed by COTE which is an ensemble of techniques.
ResNet and FCN outperform other DL techniques (although they didn’t test any Recurrent approaches like the Dilated RNN paper you linked):
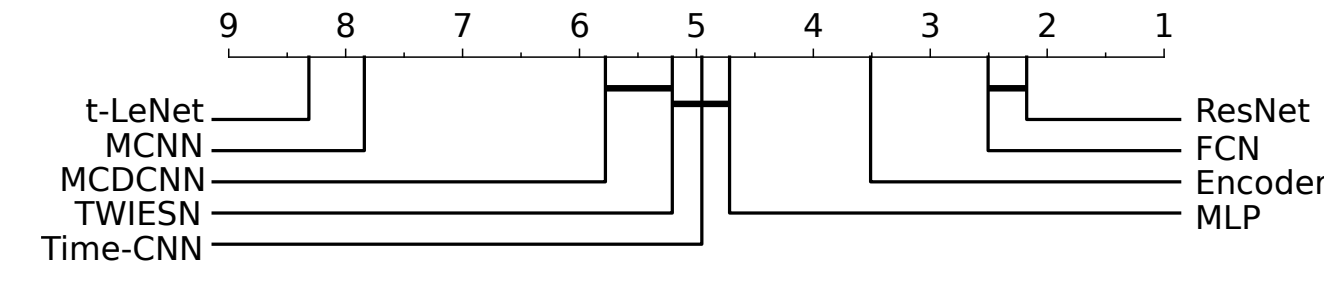
(right side/lower number is better performance)
COTE is the only non-DL outperforming ResNet:

(right side/lower number is better performance)
4 Likes
so, this may be a dumb question, but how would you ensure that you only use previous datapoints in your time series? especially if our mini batches are picked at random?
This is very interesting @henripal. Thanks for sharing!
Iv’ve scanned through the article and its super useful. And it comes with code (Keras). They claim their results are reproducible (https://github.com/hfawaz/dl-4-tsc). The show the performance they got for all UCR univariate datasets.
So I guess we should try to reproduce their results on the earthquake dataset as a starting point. I would propose we also discuss & agree what alternative approaches we’d like to test that have not been included in the paper, or ideas on how to improve their models. What do you think?
1 Like
There are no dumb questions here!
If your question is about this dataset, a sample is the entire time series that is classified as 0 or 1, so there’s no need to select any particular data points. Does this answer your question?
somewhat. If I had any time series dataset - for example if I had 2 columns - one of time stamps and the other of some continous value that I needed to predict. Would the correct technique be to convert this example dataset into a classification problem by taking the same approach that the dataset creators did?
To create a supervised (classification or regression) problem out of a time series, you can use a sliding window approach (this link may be useful).
If in addition to that you need to convert a continuous variable into a class you’ll need to apply some threshold.
2 Likes
I tried the different pyts visualizations GASF, GADF, MTF (this one I couldn’t get it working) and RecurrencePlots.
Then the 3 pyts classifiers BOSSVSClassifier, SAXVSMClassifier, KNNClassifier. Here is the confusion matrix for those classifiers:
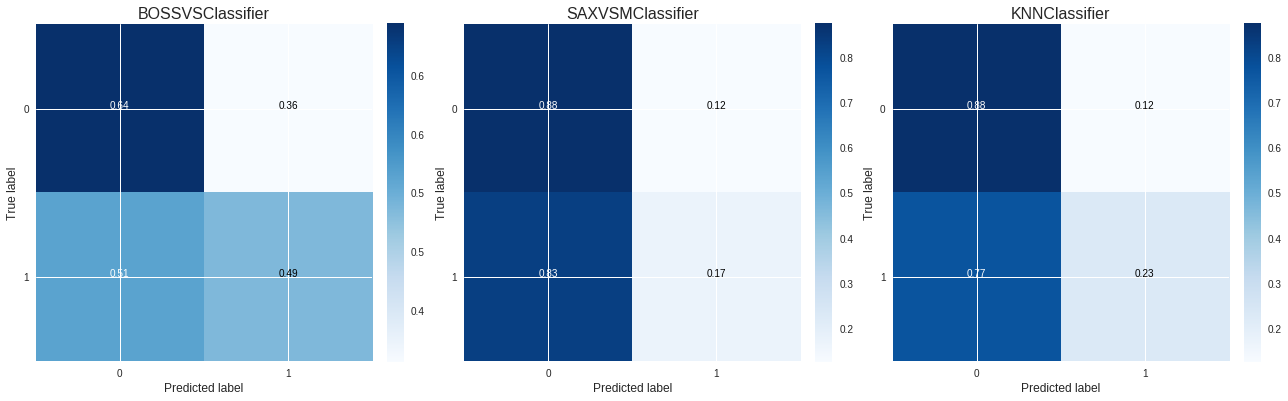
Here is the link to the notebook.
3 Likes
100% agree!
That is great article, thank you for sharing it!
Hi All,
So, I spent a little more time on this.
-
as for the training/test mistake, the mistake is at the source. The UCR_TS_Archive_2015 has some datasets with train and test sets reversed. Some authors (like the Weasel paper authors) fix this manually.
All the dataset TRAIN/TEST splits are correct in UCRArchive_2018.
It turns out the review paper uses the raw 2015 archive; so their result on the Earthquake dataset using FCN, 78% is actually worse than all false.
That said, contrary to the LSTM_FCN paper, they do not cherry pick the epoch with the lowest validation error! -
To still be able to check that I was still able to reproduce their results, I chose a dataset where traditional methods perform significantly worse than FCN (or ResNet), the Adiac dataset.
For this dataset, DTW methods give an accuracy of ~60% on 36 classes.
Using FCN, I was able to reproduce the author’s results of 80+% accuracy (by selecting on the lowest training loss) - otherwise the model’s generalizable accuracy is probably around 78%, which is still very impressive. See notebook here.
Some conclusions/observations/issues:
- evaluating on a single UCR TS dataset is going to be tough to gauge new architectures, and I would argue for evaluation of new methods on the entire set of datasets, but:
- training is long (over an hour for the Adiac dataset on my 1080Ti) and does not really stretch the memory of the GPUs
- I couldn’t get fit_one_cycle and the learning rate finder to work well for the Adiac dataset and went back to the old step function, decreasing the LR when training loss stopped decreasing, requiring some manual intervention…
5 Likes
Thanks again @henripal for the time and effort you are putting into this competition! These are, again, extremely usegul findings.
I would propose the following:
- We need to make sure participants use the right Train/ Test split using the correct UCRArchive_2018.
- I think we should propose a new rule in competition (because it’s useful in real problems). To perform any hyperparameter search, we should use a validation set out of the training set, and then report the test set performance. That’s best practice.
To achieve both points we should update the notebook we created to prepare data. I cannot work on that until tomorrow. If anybody can do it before that’d be great. Otherwise I’ll do it tomorrow.
I’d propose we continue the discusion on how to proceed with the TS project in the TSSD study group since its beyond the scope of this competition. All those interested are welcome to participate.
@henripal I’m trying to implement the multivariate LSTM-FCN, as the softmax function return probablities for the classes (in case of Earthquackes dataset it’s 2) I hot encoded the labels. But looking into your code I see you are not using a softmax, is there a reason?
My current problem is with fastai accuracy function. If I create a Learner without accuracy, I get following when I unfreeze then I fit:
data = DataBunch(train_dl=train_dl, valid_dl=test_dl, path=path)
learner = Learner(data, model, loss_func=loss_func)
learner.fit(10, lr=5e-5)
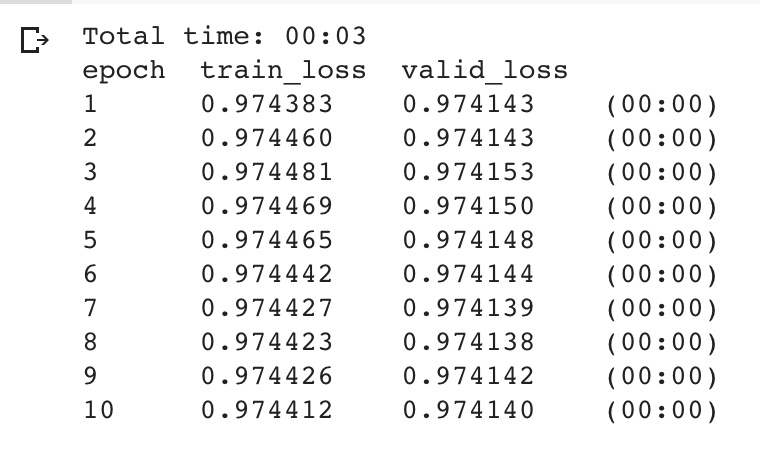
If I pass the
accuracy=accuracy to the learner I get this error
RuntimeError Traceback (most recent call last)
<ipython-input-196-b5d89f36ce92> in <module>()
----> 1 learner.fit(10, lr=5e-5)
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
160 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
161 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 162 callbacks=self.callbacks+callbacks)
163
164 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 except Exception as e:
93 exception = e
---> 94 raise e
95 finally: cb_handler.on_train_end(exception)
96
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
87 if hasattr(data,'valid_dl') and data.valid_dl is not None:
88 val_loss = validate(model, data.valid_dl, loss_func=loss_func,
---> 89 cb_handler=cb_handler, pbar=pbar)
90 else: val_loss=None
91 if cb_handler.on_epoch_end(val_loss): break
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
52 if not is_listy(yb): yb = [yb]
53 nums.append(yb[0].shape[0])
---> 54 if cb_handler and cb_handler.on_batch_end(val_losses[-1]): break
55 if n_batch and (len(nums)>=n_batch): break
56 nums = np.array(nums, dtype=np.float32)
/usr/local/lib/python3.6/dist-packages/fastai/callback.py in on_batch_end(self, loss)
236 "Handle end of processing one batch with `loss`."
237 self.state_dict['last_loss'] = loss
--> 238 stop = np.any(self('batch_end', not self.state_dict['train']))
239 if self.state_dict['train']:
240 self.state_dict['iteration'] += 1
/usr/local/lib/python3.6/dist-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
184 def __call__(self, cb_name, call_mets=True, **kwargs)->None:
185 "Call through to all of the `CallbakHandler` functions."
--> 186 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
187 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
188
/usr/local/lib/python3.6/dist-packages/fastai/callback.py in <listcomp>(.0)
184 def __call__(self, cb_name, call_mets=True, **kwargs)->None:
185 "Call through to all of the `CallbakHandler` functions."
--> 186 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
187 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
188
/usr/local/lib/python3.6/dist-packages/fastai/callback.py in on_batch_end(self, last_output, last_target, train, **kwargs)
269 if not is_listy(last_target): last_target=[last_target]
270 self.count += last_target[0].size(0)
--> 271 self.val += last_target[0].size(0) * self.func(last_output, *last_target).detach().cpu()
272
273 def on_epoch_end(self, **kwargs):
/usr/local/lib/python3.6/dist-packages/fastai/metrics.py in accuracy(input, targs)
37 input = input.argmax(dim=-1).view(n,-1)
38 targs = targs.view(n,-1)
---> 39 return (input==targs).float().mean()
40
41 def error_rate(input:Tensor, targs:Tensor)->Rank0Tensor:
RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'other'
Here is current implementation - notebook
2 Likes
+1! I have the same problem everytime I deviate from the exact lesson notebooks (which is basically always ![]() ). Training works but the metrics don’t. I have also never gotten the f1 metric to work, so I seem to lack a fundamental understanding here. It would be extremely helpful if someone who fully understands the reasons for these errors and the mechanics of the metrics callbacks could explain this. I think other people struggle with this as well. (Examples mentioned here:
). Training works but the metrics don’t. I have also never gotten the f1 metric to work, so I seem to lack a fundamental understanding here. It would be extremely helpful if someone who fully understands the reasons for these errors and the mechanics of the metrics callbacks could explain this. I think other people struggle with this as well. (Examples mentioned here:
and
here:
2 Likes
What about trying metrics=[accuracy_thresh]?
In case of multi-class problem, the prediction is single integer, in case of multi-label problem - multiple floats. Therefore the accuracy is calculated using different algorithm.
Based on the error Expected object of scalar type Long but got scalar type Float for argument #2 'other' I guess that one-hot encoding the labels calls a multi-label settings.
2 Likes
Hi, I didn’t rerun your code but looked briefly through it; hope the following will help:
Most of the models Jeremy ran during the course went like this:
- model outputs scores (unbounded floats directly from your final, dense layer)
- loss is computed using cross entropy
- accuracy is ran automagically by computing the index (
argmax) of your model’s output and comparing that to your label (see code here). Note that this requires integer labels, not one-hot encoded!
If you look at the documentation for cross entropy on the pytorch docs, you see that it is a combination of "nn.LogSoftmax() and nn.NLLLoss() in one single class" - so the cross entropy loss requires your model to also output scores, and not softmax (if not, you’re softmaxing twice).
As to the question why I had BCEWithLogits instead of softmax: it is because the Earthquakes dataset only had two classes, so instead of outputting a size 2 score vector, you can output a size 1 score and predict class 0 when the score is negative and 1 when the score is positive. The BCEWithLogits loss takes care of running that score through a sigmoid, the through the Binary Cross Entropy loss. This also causes the accuracy to fail as there’s no point in calling argmax on a size 1 vector!
3 Likes
Thanks all your input helped fixing/understanding the problem. I ended up using the a Linear layer with n output (2) then a LogSoftmax and using a NLLLoss loss function. this way I can reapply same architecture on another problem just by passing the right class number.
Training the model with for 100 epochs, but after only 7 it reached 100% something odd 
Total time: 00:38
epoch train_loss valid_loss accuracy
1 0.437780 0.483696 0.819876 (00:00)
2 0.365820 0.430517 0.819876 (00:00)
3 0.309986 0.299840 0.875776 (00:00)
4 0.252181 0.139254 0.956522 (00:00)
5 0.207332 0.055020 0.984472 (00:00)
6 0.169240 0.021992 0.996894 (00:00)
7 0.140646 0.010572 1.000000 (00:00)
. . .
96 0.000043 0.000005 1.000000 (00:00)
97 0.000040 0.000004 1.000000 (00:00)
98 0.000038 0.000004 1.000000 (00:00)
99 0.000037 0.000004 1.000000 (00:00)
100 0.000037 0.000004 1.000000 (00:00)
I used the test set as a validation set, probably I need to go back and change this.
Here is the link to the notebook