Hi, I hope I’m posting in the right channel (if not please let me know: it’s for an open science/open data cause!).
We are happy to host the COVEO DATA CHALLENGE @ SIGIR 2021 - you can test your ML skills on a huge, new, rich eCommerce dataset that we just released to the AI community, and you’ll get a chance to write a research paper and present it at the conference!
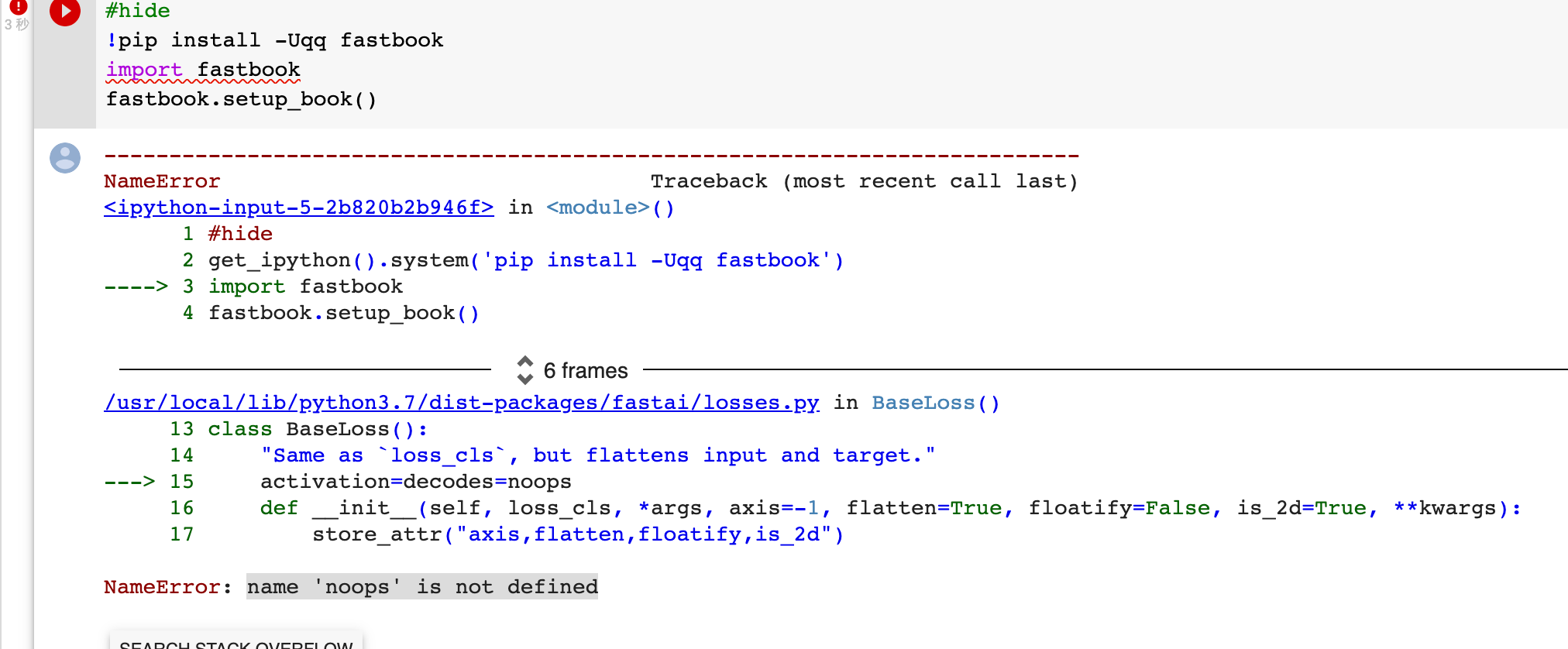
Second stab at completing the course - ran into some troubles with the cloud setup the first time and gave up almost immediately. Taking Jeremy’s suggestion to write a blog this time around and it definitely forces you to think about things!
You can see in the book that it took them ~3 minutes per epoch. So about 15 minutes total. On my not as fast GPU it takes longer. If you spend much longer than that, you should check that the GPU is actually used (so not CPU)
@Matsemann Thanks so much for your reply. If I run this on a colab notebook with a GPU enabled it takes around 1 hour to run. What is the GPU config you are using ? Also if we train a keras model using IMDB it takes only a couple of minutes.
Hi Jessica
AI recruitment is nothing new. It was used in the 1980’s. Anybody can be a salesman so they believe and hundreds apply for the job. We had a system run by a US University for which all the candidates completed a questionnaire and the computer selected the most suitable candidates for human interviews.
Regards Conwyn
Unfortunately the course will require many different skills. So each user will have different needs. For somebody with a day job I would say about 12 months.