Hi Everyone,
I have trained my model for many many times with 2900 images/class for 5 classes. I split data 80% for training and 20% for validation with shuffling.
All the times, I get zero test accuracy as shown in this figure, although the training accuracy is improving.
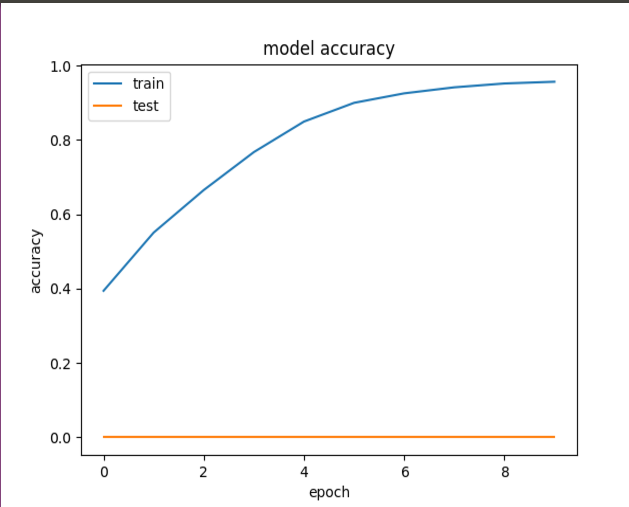
What do you think the problem is? In my opinion, I do not think this is an overfitting problem.
Here is my code:
import csv
import cv2
import numpy as np
import matplotlib.pyplot as plt
import glob
def plot_CNN(history): # summarize history for accuracy
fig1 = plt.figure()
plt.plot(history.history['acc'], figure = fig1)
plt.plot(history.history['val_acc'], figure = fig1)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
fig1.savefig('results/pipeline_accuracy.png')
fig2 = plt.figure() # summarize history for loss
plt.plot(history.history['loss'], figure = fig2)
plt.plot(history.history['val_loss'], figure = fig2)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
fig2.savefig('results/pipeline_loss.png')
print("************ Preparing DATA **************")
class1 = glob.glob('class1/*jpg') # use a.extend() for adding training folder
class2 = glob.glob('class2/*jpg')
class3 = glob.glob('class3/*jpg')
class4 = glob.glob('class4/*jpg')
class5 = glob.glob('class5/*jpg')
all_lists = [class1, class2, class3, class4, class5]
print("all_lists length: ", len(all_lists))
images = []
targets = [] # has lists of [0,1,2,3,4] based on the images lists
current_target = 0
for list in all_lists:
print("current_target ", current_target)
print("current_list ", len(list))
for i in range(len(list)):
# reading an image
image = cv2.imread(list[i],0) # image in grayscale with adding 0 argument
# converting color space
#image = cv2.cvtColor(srcBGR, cv2.COLOR_BGR2RGB)
# appending to images list
images.append(image)
targets.append(current_target)
# Pre-processing .. Flipping
flipped_image = cv2.flip(image, 1)
# appending the flipped image .. so data will be doubled
images.append(flipped_image)
targets.append(current_target)
current_target += 1
print("number of images: ", len(images))
print("number of targets: ", len(targets))
#X_train = np.array(images)
#Y_train = np.array(targets)
X_train = np.stack(images, axis=0)
Y_train = np.stack(targets, axis=0)
print('****** DATA IS READY *******')
classes_output = 5
nb_epochs = 10
scale = 1
print('X_train shape before: ',X_train.shape)
print('Y_train shape before: ',Y_train.shape)
if scale ==1:
X_train = X_train.reshape((X_train.shape[0], 256, 256, scale))
print('X_train reshape: ',X_train.shape)
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.layers import Activation, Dropout, Flatten, Dense, Lambda, Cropping2D
from keras.models import model_from_json
def Model():
print("******** RUNNING MY MODEL **********")
model = Sequential()
#model.add(Lambda(lambda x: x/255.0 - 0.5, input_shape=(256, 256, scale))) # normalizing by dividing each pixle by 255 ==> gives values in range (0,1), then shifted the mean from 0.5 to zero
#model.add(Cropping2D(cropping=((70,25),(0,0))))
#model.add(Convolution2D(32, 3, 3,activation='relu'))
#model.add(Convolution2D(32, 3, 3,activation='relu'))
model.add(Convolution2D(32, (3, 3), activation='relu', input_shape=(256, 256, scale)))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Convolution2D(64, 3, 3,activation='relu'))
#model.add(Convolution2D(64, 3, 3,activation='relu'))
model.add(Convolution2D(64, (3, 3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Convolution2D(128, 3, 3,activation='relu'))
#model.add(Convolution2D(128, 3, 3,activation='relu'))
model.add(Convolution2D(128, (3, 3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Convolution2D(64, 3, 3))
#model.add(Convolution2D(64, 3, 3))
# fully-connected layers
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(100))
model.add(Dropout(0.5))
#model.add(Dense(50))
#model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Dense(classes_output))
model.add(Activation('sigmoid'))
print("******** MODEL IS BUILT **********")
return model
X_normalized = X_train /255.0 - 0.5 # normalizing data
from sklearn.preprocessing import LabelBinarizer
label_binarizer = LabelBinarizer()
y_one_hot = label_binarizer.fit_transform(Y_train)
myModel = Model()
myModel.compile('adam', 'categorical_crossentropy', ['accuracy'])
history = myModel.fit(X_normalized, y_one_hot, batch_size=32, validation_split=0.2, shuffle=True, epochs=nb_epochs)#, verbose=2)
print("Model is compiled and fitted with ", nb_epochs , " epochs")
model_json = myModel.to_json()
with open("results/model.json", "w") as json_file:
json_file.write(model_json)
myModel.save_weights('results/model.h5')
print('******** MODEL IS SAVED *********')
print(history.history.keys())
print(myModel.count_params())
print(myModel.summary())
plot_CNN(history)
>