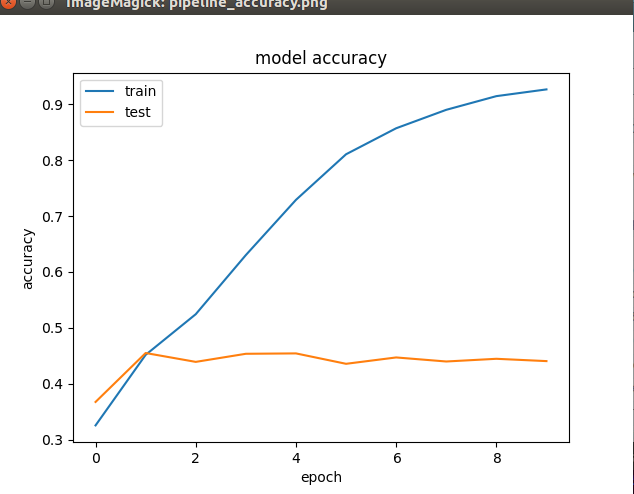
The hunch was that: X_normalized and y_one_hot are being created by appending classes 1 to 5. Hence it might be that the top 80% of data consists of classes 1 to 4, and the bottom 20% has class 5.
Since the validation_split was set to 20%, and since Keras extracts the last n% of your dataset for validation, our training set might contain classes 1 to 4, and validation set with just class 5.
Which means during training, the model would not have seen class 5 at all, hence the poor validation accuracy.
To check this out, solution was to shuffle the contents of X_normalized and y_one_hot so that classes are uniformly distributed.
–