Hi,
I wanted to train a model with fastai for a somehow long time, and I have two options Nvidia V100 and RTX A6000. I wanted to use RTX A6000 because it has higher memory, and I wanted to train my model with a larger batch size. Also, RTX A6000 is much cheaper. But I was worried about performance and supporting FP16 training.
I am no hardware expert, so I wanted the opinion of you guys.
Thank you so much for this post @ilovescience
Sorry if this is somehow a newbie question, but I wanted to use 1A6000.10V instance, and I had some worries about installing packages like fastai and transformer since it uses AMD cpus. Do you think that would be a problem or not.
Also, does A6000 support FP16 for training because As I went through your post, I didn’t notice that.
I found a benchmark that shows fp16 training performance as well:
Using AMD CPUs shouldn’t be a challenge, many people do use AMD CPUs actually. Using AMD GPUs is there more challenging situation since it’s not using CUDA (which is NVIDIA-specific).
The latest cards like A100 works well with AMD CPUs as they are the only ones currently supporting the PCIE-4 bus. Intel was also working on something, but it is not publicly available.
For anyone trying datacrunch servers with fastai it is worth checking out the real performance of their hardware / fastai on a particular GPU server.
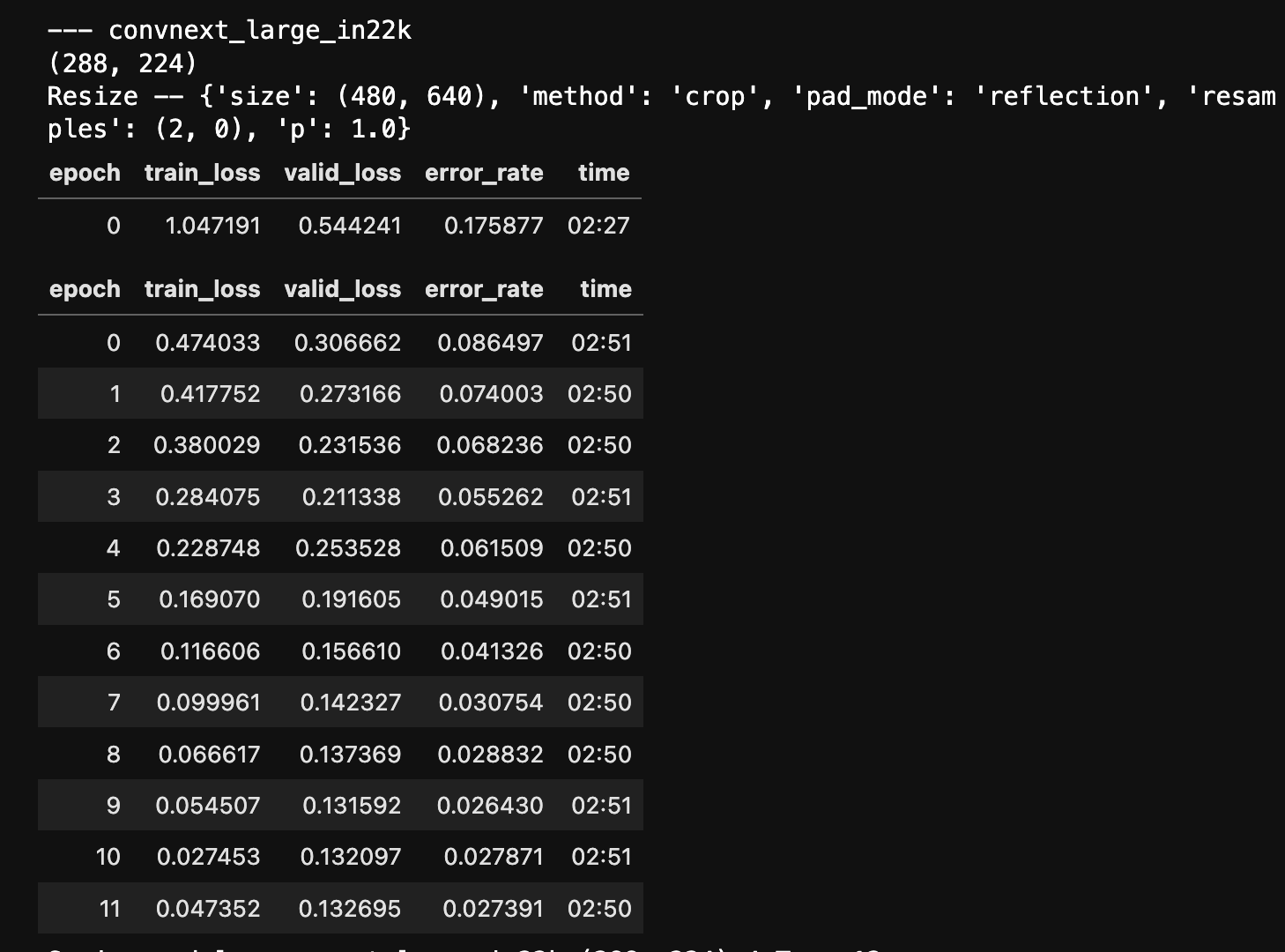
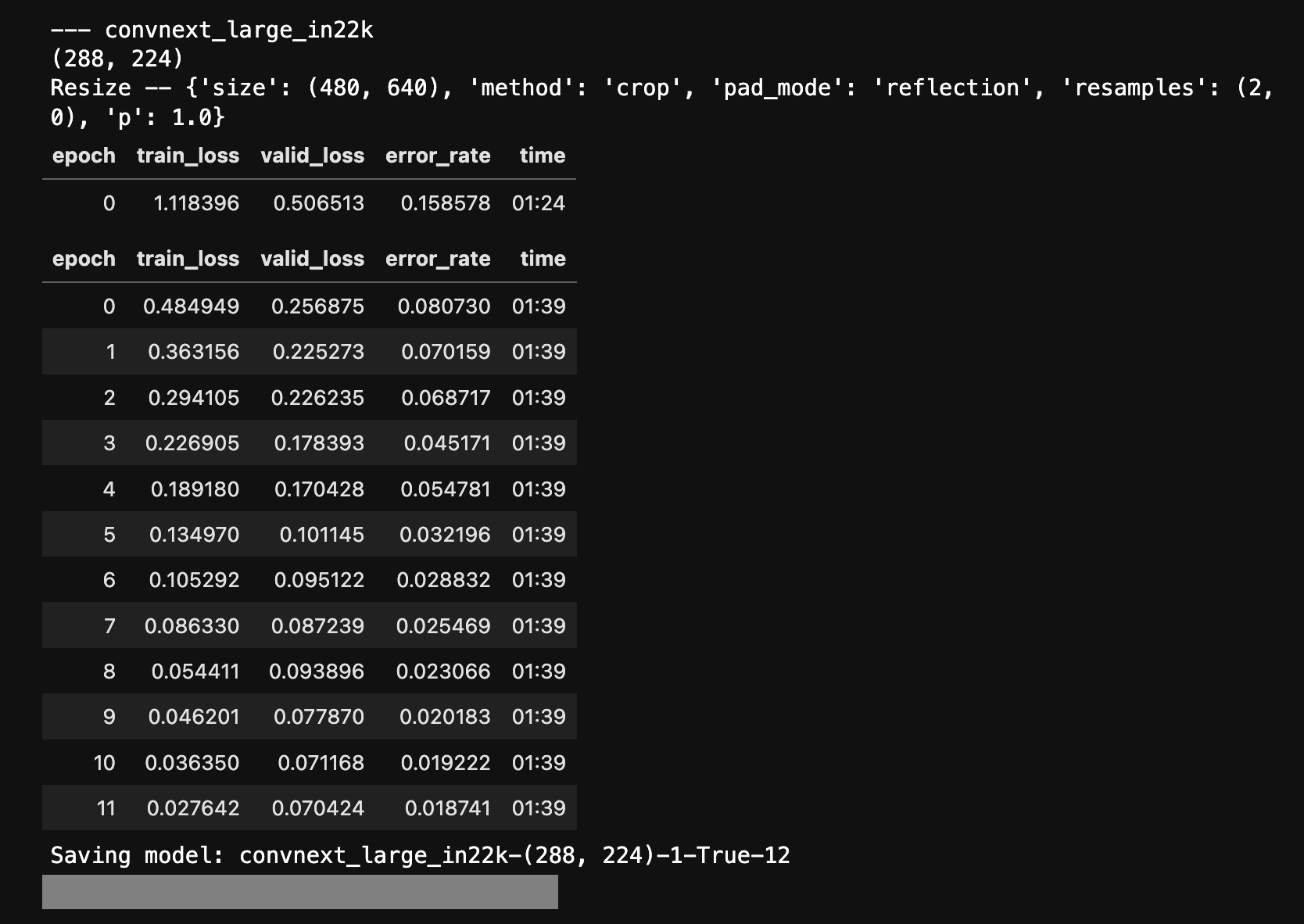
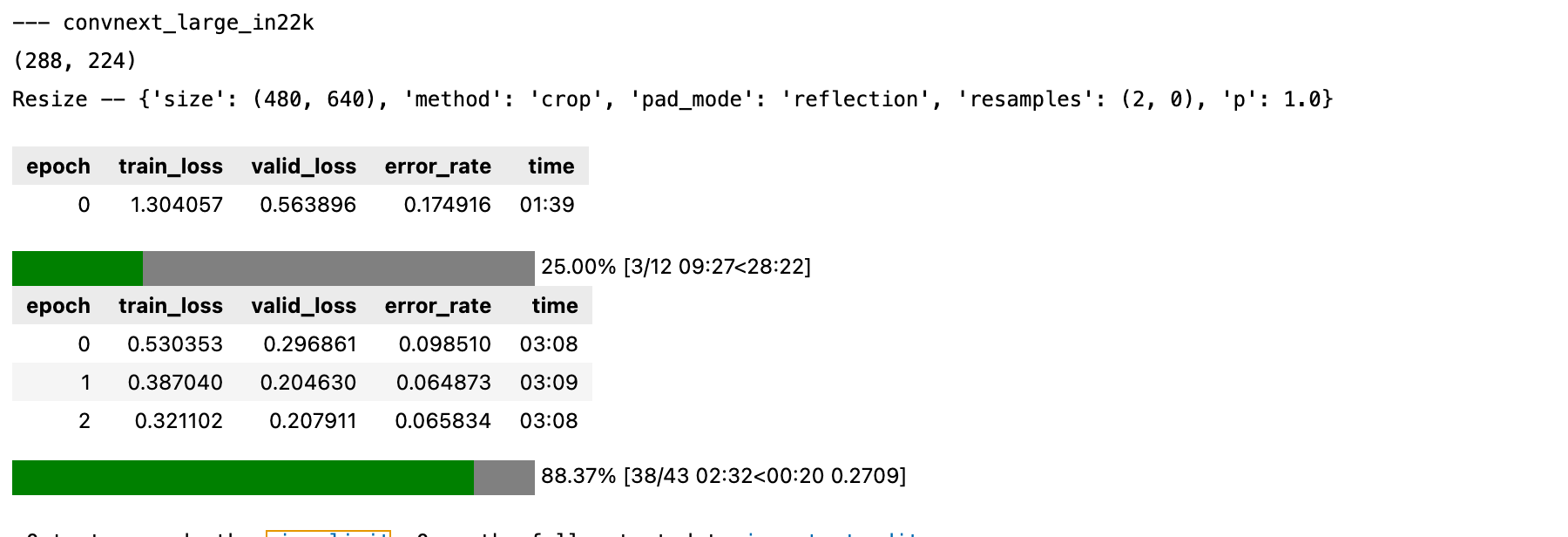
I’m playing with Kaggle Patty competition and A6000 is ~2x times faster than v100 / a100 on datacrunch.
For example, one epoch of training convnext_large_in22k takes 02:50 on V100 (32 batch size) and 3:08 on A100 (128 batch size), while it takes only 01:39 on A6000 (96 batch size).
I’m running modified scripts posted by Jeremy on kaggle:
Why is a JarvisLabs A100 being faster than their A6000 is "expected’?. Sorry if this is an obvious thing, I thought they should be within a reasonable ballpark regardless of the cloud provider? Do JL and DC configure the backplanes differently (enough) such that the performance is essentially reversed?
I’ve seen some comparison charts of training on A6000 and A100, here is one
it shows A100 being 2x as fast as A6000 on fp32. I was using fp16 but they should be comparable.
I’m not sure why A100 on DC is so slow, but I’ve tried it for the second time and I’ve got the same results. A6000 being much faster than A100 all the time.
Aah! oK! now the statement “A100 on JarvisLabs is faster than A6000 as expected” makes sense! It is faster based on those benchmarks. I thought there was something intrinsic about the JL setup which made it faster. Thanks!
A beast indeed! I was getting 9 min / epoch on Kaggle and fired up a Jarvislab A100 instance and with bs=64 , I’m getting about a minute and change an epoch.
Which btw, makes me really appreciate @VishnuSubramanian work on Jarvislabs in making it so easy to start up. For the small amount of money I’m going to spend (about 1-2 dollars for fully runnning this notebook) I’m going to save about 6 hours of runtime that I’d have to babysit this over on Kaggle’s free GPU.
Personally I find JL instance much easier to fire up and get to work faster than paperspace (in my personal experience)
The 3rd Paddy notebook ran in 1/10th the time on a Jarvislabs A100 instance and it submitted just fine to Kaggle to boot!. Can’t take credit for the leaderboard though because aside from my trying out minor tweaks it’s all Jeremy’s work
Yeah Jeremy did the hard work, if you run the code twice (once with label smoothing) then do ensemble of both runs you get my result :). But Jeremy have some ideas in the direction of clever improvements that I think he intentionally is holding off , so we can try them out first.
Welcome to the competition btw :).
I’ve tried mixup and cutmix but they aren’t working, I think due to the fact that the competition has “Normal” as one of the classes. The cutmix especially will deteriorate performance. But it can be fixed by switching to Binary cross entropy. and removing Normal. Then things should work better. I will try that and post a notebook if I managed to get something working that isn’t ensembling of an ever larger number of models
I never saw my GPU mem% go over 16GB … seems such a waste when paying for a 40GB A100 with 250GB of RAM, I was thinking of setting the batch size to 256 and accum=2 (for effective bs=128) and letting it rip. Not sure what the proper way to use the BS would be in the accumulation context.
In one of the lectures Jeremy mentioned that using reflection actually confused the models. Maybe it only works with certain types of models? because I see it being used in this notebook.
I’ve used batch size 96 and it was working fine using up to 30 - 40 GB of memory. For some models it was not enough and I had to use gradientacumm (VIT large with large patch size). But I can’t start my DC instance anymore as there is no A6000 available so I can’t give you a screenshot.
I’ll need to run some experiments with higher BS. I don’t think JarvisLabs has 80GB version of A100s in their inventory, but looking at the memory bandwidth on the card, I can see how it can perform better than A6000 (almost double the throughput) so if it is kept well fed, it’ll probably do better, so maybe DC has a bottleneck in their architecture somewhere.
Ruben here from DataCrunch. Thanks for bringing this potential issue to our attention, our A100’s should outperform regular A100’s with about 30%, as they are the higher powered SXM4 version with 80GB which has an even higher memory bandwidth.
We’ll try to replicate and analyze where it goes wrong.
Cool! I used Jeremy’s Kaggle notebook below. On JL I had to import latest version of fastai and “timm>=0.6.2.dev0” separately even though setup_comp() is supposed to do it as well.
I’m really curious now as to how long it takes on an A100/80GB card