I was hoping that just brute-force of gpu will help me get up in the leaderboard. ![]() But apparently that wasn’t the case :D.
But apparently that wasn’t the case :D.
1 Like
A100 on JV is 40GB, but I wrote to DC as well as the A6000 runned out, and they claim to resolve the issue. I will give it a try and let you know.
2 Likes
This is my plan too ![]() … just to see if it works, maybe add a few more models in the ensemble and tweak the sizes a bit, maybe get a few tenths of a percent more out …
… just to see if it works, maybe add a few more models in the ensemble and tweak the sizes a bit, maybe get a few tenths of a percent more out …
1 Like
I am sure brute-force approach of gpu is working and burning compute is way to be on top of leaderboard atleast the public leaderboard ![]() . TBH that is exactly what I have also done also. I have shared my approach here:
. TBH that is exactly what I have also done also. I have shared my approach here:
From burning few GPU hours, I don’t think training transformers architectures like Swin, VIT for large epochs doesn’t give great results. That’s why I personally ask to trust the results of Jeremy study on the best vision models for fine tuning, as my it was a late night experiment with Convnext which took me to the top ![]()
2 Likes
We can help at Q Blocks with a lot of GPU options to choose from.
We pool computing from a lot of compute providers to offer GPU capacity at best rates possible.
Cheers!
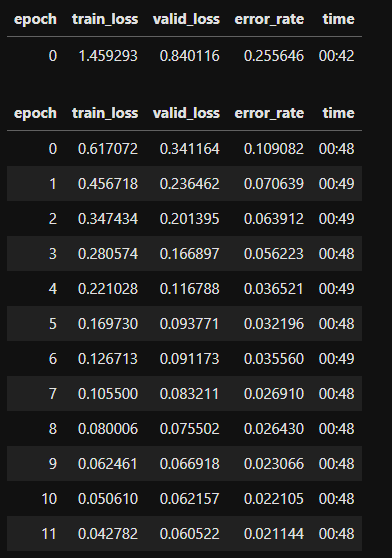
On A100 80GB, I ended up with 0:48 per epoch, memory usage of 77GB at a batch size of 128.
A batch size of 64 was 0:49 so only marginal improvements with a large batch size.
GPU utilization is not ideal but fairly good.
I can share my image to anyone interested or dependency list. Running on Cuda 11.3 with Pytorch 1.11.0.
1 Like
Thanks for sharing Ruben! I think @piotr.czapla might be interested ![]()
It seems the timings have improved (almost 3x improvement IINM,) is it a special image or some tweaks that were done to bring down the time/epoch from the ones originally mentioned by Piotr above?
1 Like
Our FastAI image is outdated (working on it ![]() ) so I started with a clean slate.
) so I started with a clean slate.
I took our Ubuntu 20.04 image and installed Fastai with this env.yml:
name: fastai
channels:
- fastchan
- fastai
- pytorch
- defaults
dependencies:
- cudatoolkit=11.3
- fastai>=2.7.4
- jupyterlab
- python>=3.10.4
- pytorch=1.11
- torchvision=0.12
- pip
- pip:
- -r requirements.txt
requirements.txt:
graphviz
ipywidgets
matplotlib>=3.5.4
pandas>=1.4.3
scikit_learn
sentencepiece
I had to pip install “timm>=0.6.2.dev0” as well as mentioned above.
We’ll be rolling out an updated fastai image which will run this out of the box.
1 Like
Thanks, @mike.moloch ![]() We have also updated to the latest
We have also updated to the latest fastai and timm versions.
2 Likes
I still see fastai version as 2.6.3 when latest version v2.7.4 in JL
Fixed now. It was not reflected in the UI ![]() earlier.
earlier.
2 Likes
@Ruben, thank you for taking care of the issue. I was running the latest version of fastai and timm so the fix is coming from other dependencies (cudatoolkit perhaps?). Let us know once the image is fixed.