Hello everyone!
I’m following the “Practical Deep Learning for Coders, v3” course and as a part of the practice, I wanted to train a regression model to predict the prices of some paintings based on the painting itself. I’m using the standard cnn_learner model with resnet50 architecture. Although I experimented with different configurations, I couldn’t even get close to satisfying results. What could be the reason for it? Could it be that the area that I’ve chosen is maybe too abstract to make predictions, could I have too few data for it? I would be grateful for any hints.
Could you please share your code and your results? By the way, the cnn_learner returns a classification model. How did you create your model? And what kind of data do you have?
The model takes an image as an input and returns a predicted price of the painting. I tried training it afterwards after unfreezing as well.
#Tried both MSE and this custom one
class L1LossFlat(nn.SmoothL1Loss):
def forward(self, input:Tensor, target:Tensor) -> Rank0Tensor:
return super().forward(input.view(-1), target.view(-1))
# get_value function reads labels from txt files
# tried both regular and log=True values
reg_data = (ImageList.from_folder(path)
.split_by_rand_pct()
.label_from_func(get_value, label_cls=FloatList, log=True)
.transform(get_transforms(do_flip=False,max_rotate=0.,max_zoom=0., max_lighting=0., max_warp=0.), tfm_y=False, size=(128,128))
.databunch().normalize(imagenet_stats)
)
learn = cnn_learner(reg_data, models.resnet50)
learn.loss_func = L1LossFlat()
learn.lr_find()
learn.recorder.plot(suggestion = True)
learn.fit_one_cycle(5, lr)
learn.show_results()
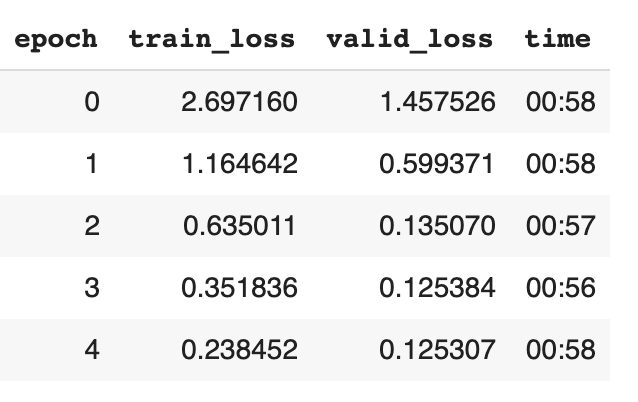

That does actually sound like a very hard task that requires a lot of expert knowledge. So the question is what performance you want to achieve for your model to be useful - if the goal is to surpass the average person’s ability to guess a price based on a picture (which shouldn’t be very hard) or achieve expert level performance which is much harder.
Anyway, I think for such a difficult task you would need quite a large dataset. How many labelled examples do you have in your training set?
I’m afraid it doesn’t really. A CNN is predicting the class of an image. You have a finite number of classes (representing prices) which your model understands, and it’s the prices from the training data. Your predictions will always be one of those classes/prices.
I think if you’re going to get this to work I would try and get as much data as possible and bin it, EG: paintings from $0-1000, $1001-2000, etc, although you’ll have to fiddle with bin sizes to see what works best.
You’ll have a model which can predict the price of a painting within a certain range (say 10K if that’s the bin width you end up with) which is about as good as an expert would manage.
Thanks for your reply! I have about 10 k images and the set is unbalanced because about 50% of the data is labeled as “unsold” which means there is no “sold_price”. I tried to remove those samples from dataset (resulting in having only ca. 5k samples) but this didn’t help either.
I think you are right, that first of all I should have decided what is the goal. I didn’t do that. I just trained some basic models using the data and wanted to see what results I could achieve.
By asking this question I wanted to make sure that I’ve actually chosen the correct way to training it. The other thing as you’ve said could be that I just need more data/set better goal.
I suppose that the dataset is rather small for that?
Thanks for taking your time to reply!
The thing you are describing was actually the first thing I did and after getting some results which wasn’t satisfying to me (unfortunately I discarded them already) I tried to approach the problem using regression. Do you know what would be the correct approach if I wanted to do the regression?
Regarding the bin approach: is there any specific metric/loss function (or should I write it by myself) to use in that kind of a situation? I think that in this case the correct answer could be not only predicting the exact bucket but depending on the width of it, some of the adjacent ones might be good as well.
You will need to make some modifications to the model’s head (which is a classification head in cnn_learner) so that you can train a regression model. Here is a thread that discusses image regression in fastai: Image Regression using fastai
That’s a good point. You could also train it as a regression problem and do any binning afterwards. If the predicted values of the regression model are not good enough by themselves, you can still split them into bins after training. Like this you can also adjust the bin size/width to optimize your metric.
1 Like
It’s quite an audacious problem to tackle, but as much as I like it, I doubt it will work.
Machine learning is not magic - there has to exist some function of the input that gives the prediction. A painting’s value AFAIK is not much related to its appearance. Rather it’s set by the art collection market, which responds to factors like the artist’s scarcity, the artist’s reputation, the period of the painting, the investment value, and art collection fashions that come and go. I’d be very surprised if a CNN could find a correlation with these factors from a photograph of a painting.
What it might do is learn to recognize paintings by particular artists, like van Gogh vs. Pollock, and correlate the artist with the price. That could even be your baseline: train an artist->price model and see if painting->price can do any better. painting->artist might even be a more educational and successful project.
As an analogy, you could train a photo-of-vegetable->price model, but it would not tell you anything intrinsic to vegetables. It would merely learn to recognize vegetables and that mushrooms cost more than potatoes.
All that said, I would certainly love for you to discover that there’s some intrinsic visible quality to art that determines the artist’s reputation and price collectors will pay for their work. That discovery would revolutionize several fields - art history, psychology, auctioneering, economics - all at once!
A few notes…
-
You are already using regression by specifying FloatList for the data. Fastai automagically uses a regression head and MSELoss when the label is FloatList. To my mind, this is clearly a regression task. I suggest sticking with the defaults.
-
It seems essential that you remove all the samples with unsold as their label. I can’t even guess how FloatList interprets “unsold”. You might want to print a sample batch to see what fastai actually doing.
-
Watch out for overfitting, where resnet only memorizes a painting and its price.
HTH, Malcolm
1 Like