Thank you for posting this @rkishore
I adapted your solution to download the data needed to set up for the lesson6-rossmann jupyter notebook which you access by running rossman_data_clean. rossman_data_clean states that you should simply untar the data and go from there. Unfortunately, the data provided (http://files.fast.ai/part2/lesson14/rossmann.tgz) was throwing an error that it wasn’t a gzip file when I was trying to run untar_data. Your solution worked perfectly and I am able to finally run this step as a result!
PATH=Config().data_path()/Path('rossmann/')
table_names = ['train', 'store', 'store_states', 'state_names', 'googletrend', 'weather', 'test']
tables = [pd.read_csv(PATH/f'{fname}.csv', low_memory=False) for fname in table_names]
train, store, store_states, state_names, googletrend, weather, test = tables
len(train),len(test)
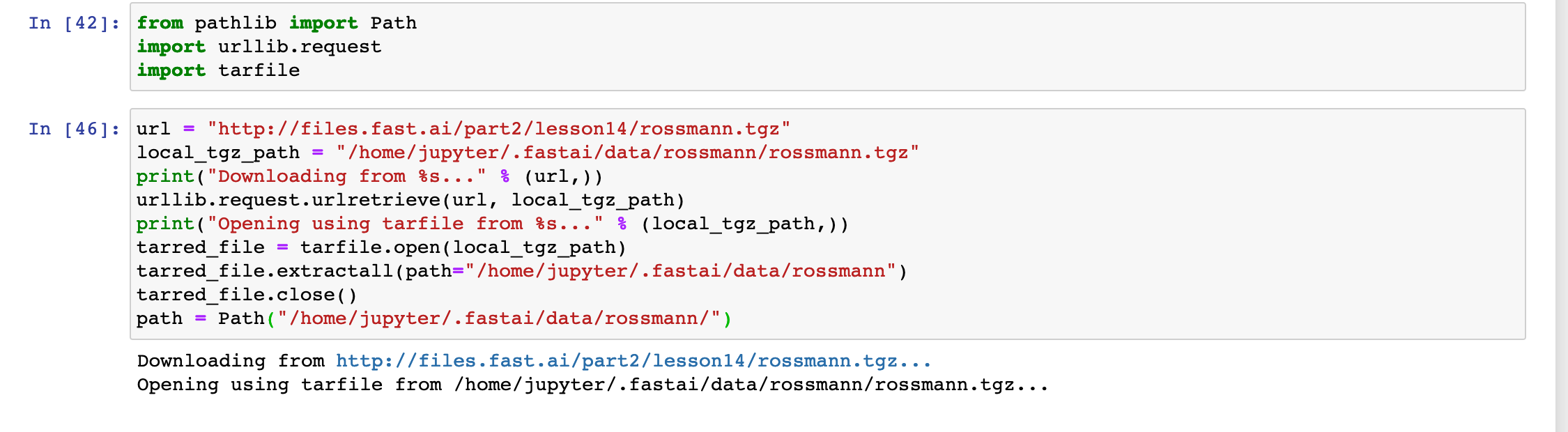
The code that I ended up running at the start of the notebook to download & unzip the file successfully was as follows:
PATH=Config().data_path()/Path('rossmann/')
table_names = ['train', 'store', 'store_states', 'state_names', 'googletrend', 'weather', 'test']
tables = [pd.read_csv(PATH/f'{fname}.csv', low_memory=False) for fname in table_names]
train, store, store_states, state_names, googletrend, weather, test = tables
len(train),len(test)
url = "http://files.fast.ai/part2/lesson14/rossmann.tgz"
local_tgz_path = "/home/jupyter/.fastai/data/rossmann/rossmann.tgz"
print("Downloading from %s..." % (url,))
urllib.request.urlretrieve(url, local_tgz_path)
print("Opening using tarfile from %s..." % (local_tgz_path,))
tarred_file = tarfile.open(local_tgz_path)
tarred_file.extractall(path="/home/jupyter/.fastai/data/rossmann")
tarred_file.close()
path = Path("/home/jupyter/.fastai/data/rossmann/")
For anyone wondering, I’m running my cloud entirely in the cloud on GCP.