ML-Lecture5.1
Goals
Anything you watched me code in class, i expect you to be able to do. Why we are doing it, and then , working on the random forest
Partial random forest and complete it
%load_ext autoreload
%autoreload 2
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
%matplotlib inline
import sys
# or wherever you have saved the repo
sys.path.append('/Users/tlee010/Desktop/github_repos/fastai/')
from fastai.imports import *
from fastai.structured import *
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from IPython.display import display
from sklearn import metrics
PATH = "data/bulldozers/"
%time df_raw = feather.read_dataframe('/Users/tlee010/kaggle/bulldozers/bulldozers-raw')
Why do we do machine learning? What’s the point?
Examples
- Applications of machine learning
- LTV
- Churn
- Upselling
- Discount Targeting
- …
Churn
The predictive modeling isn’t great. It will identify who is going to leave. To understand why you would do churn modeling, we consider the following:
How to design data products:
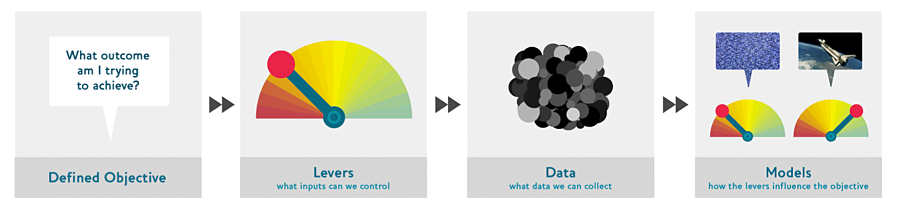
Objective - is the thing that the company actually wants. The most important thing.
Levers - is a thing the organization can do to drive or control the objective. Examples: outreach, price control, fees, or better customer experience. What are the actual things we can do to make these things happen.
Data - What data does the organization have (or could collect) that could possibly have that would help design that lever or target a specific objective. Customer call frequency, or addresses, customer profiles. History of past incentives.
Models - model in the sense of a simulation model. If a company changes their prices, how does this change their profitability. This is based on probability, such as % of claim, % of new customer. Combining all these factors, what is the over approximate bottom line going forward in the market?
You are going to care more about the simulation (compared to the data science model that we are talking about). If you read all of douglas adams books, and Amazon recommends the collected works. While in the realm of machine learning this is correct, its wasted. You would have already liked the book, and aware of all of these.
Instead, models should try and alter customer behavior by recommending things not seen but similar.
Simulation Model - in world with a new book on the homepage, what will happen? So of all the possible products to be placed on the homepage, we want the most maximized option.
Back to Churn - if Jeremy is going to leave Verizon. If the company calls him, most people hate that. Whats the probability that Jeremy will stay if you call him? Alternatively if you gave him a mail that offered a 100k a day for staying? Great choice, but the profit would tank.
** There’s always a practical consideration in modeling data **
We care about the interpretation more the predictive problem.
- if you can’t change the feature thing - no use
- if the feature/ aspect is not that interesting - also not useful
- use random forest model at the intersection to answer some of these questions
- are we making the compelling story to sell the results and lead to insights?
Consider the context when making the machine learning models
- Understand the clients
- Understand the stake
- Understand the strategic context
- Move beyond the predictive models to bring it all together
Vertical Applications
Healthcare - readmission risk - Whats the % chance a patient will come back. What do you do about it? Doing a tree interpreter will help identify the different items and key features.
Confidence in Tree Prediction Variance (for a row)
Looking at the variance of the predictions. We hold one row, and we look through the different trees to see which has the highest variance. If we are putting out a big algorithm, we dont care about the average prediction, but we care about the standard deviation of the predictions. Maybe there’s a whole group of people that we are not confidence about.
Feature Importance
Which features are important in the model. We freeze everything else and randomly sample the feature to see how much the end prediction changes. If the validation score changes a lot, that is an “important feature”. We take the difference in R^2 to give us the feature importance.
key thing dont want to retrain the model. Using the existing model, and randomly shuffle the whole column, the mean and the distribution are teh same, but the row connection is different. We use that new version and run it through the existing model (no re-training) then re-score. Then we can do this for each feature and see how the RMSE changes. The difference in RMSE will become the feature importance. The absolute difference doesn’t matter, the relative difference is what is important.
Partial Dependence
Vast majority of the time, someone will show a univariate chart. This is a problem is that real world has a lot of interactions between different fields. In our illustration, whats the interaction between sales price + year made. Pulling them appart with partial dependence we can find the true relationship. We will take our data, freeze all other features, replace every single value with the same thing, in this example year with 1960, and we will get a set of predictions (all for 1960) The median of all the rows is the yellow line, and all of them will give a spread.
** Why does this work? ** - whats the average option? Average sale date, common machine, most popular location. A single row will often represent the single option. That would give us a version of the relationship between year made and sale price. What if tractors overall increased in price, and what if backhoe loaders decreased? On average the amounts would level out, but it would be lost in the average.
We can then do a cluster analysis to find the different shapes.
Is this the shape that I expect?
Tree Interpretation ( for a row)
For one particular row and trace it through the random forest. Starting with the mean and then note how much each feature affects the target variable piece by piece. This is the point that we looked at waterfall charts.
Reminder about Nans in Fields (in categorical variables)
Pandas - changes it to -1, FastAI adds one, and changes it to 0. Often times missing values are a strong signal for a predictor, but could also show data leakage (no data defaults, or poorly collected data)
Interaction Importance <- pulled from feature importance
Another way to do tree interpretter for everyrow and adding up the contribution. Its another way of identifying feature importance, but over the entire dataset.
if we start
10 --> enclosure 9.5 --> year made --> 9.7 --meter -> 9.4
We could state that:
- enclosure + year made --> = -0.3 for this
- year + meter --> -0.1
- enclosure + year made + meter --> -0.6
import feather
df_raw = feather.read_dataframe('/Users/tlee010/kaggle/bulldozers/bulldozers-raw')
print('import complete')
import complete
%load_ext autoreload
%autoreload 2
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Live Coding
from fastai.imports import *
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline
Synthetic Data creation
Make a generic x dataset
x = np.linspace(0,1)
x
array([ 0. , 0.02041, 0.04082, 0.06122, 0.08163, 0.10204, 0.12245, 0.14286, 0.16327, 0.18367,
0.20408, 0.22449, 0.2449 , 0.26531, 0.28571, 0.30612, 0.32653, 0.34694, 0.36735, 0.38776,
0.40816, 0.42857, 0.44898, 0.46939, 0.4898 , 0.5102 , 0.53061, 0.55102, 0.57143, 0.59184,
0.61224, 0.63265, 0.65306, 0.67347, 0.69388, 0.71429, 0.73469, 0.7551 , 0.77551, 0.79592,
0.81633, 0.83673, 0.85714, 0.87755, 0.89796, 0.91837, 0.93878, 0.95918, 0.97959, 1. ])
Make a generic y with some error
y = 2 * x + np.random.uniform(-0.2,0.2, x.shape)
y
array([ 0.05514, -0.12812, -0.06351, 0.29371, 0.17055, 0.16269, 0.05526, 0.12152, 0.35499, 0.43337,
0.2385 , 0.50721, 0.36724, 0.40538, 0.57344, 0.79929, 0.67122, 0.8295 , 0.78024, 0.89374,
0.98582, 1.03438, 0.88132, 0.92705, 0.93262, 1.17425, 1.09959, 1.00443, 1.06237, 1.0425 ,
1.06355, 1.42616, 1.15585, 1.53326, 1.2411 , 1.58873, 1.65618, 1.67256, 1.50637, 1.53776,
1.57574, 1.82819, 1.69817, 1.92783, 1.88043, 1.68565, 2.0121 , 1.87214, 1.84544, 2.03121])
print(x.shape, y.shape)
(50,) (50,)
plt.scatter(x,y)
<matplotlib.collections.PathCollection at 0x1c0fc70128>
Build a random forest model, mocking up a time series
make our training and validation sets
x1 = x[...,None]
x_trn, x_val = x1[:40],x1[40:]
y_trn, y_val = y[:40],y[40:]
note that a matrix with one column is not the same thign as a vector
Use numpy’s .reshape() to change the vector into a 1 x n matrix
x[None,:].shape
(1, 50)
x[:,None].shape
(50, 1)
x[:,].shape
(50,)
x[...,None].shape
(50, 1)
Run our Basic Regressor
m = RandomForestRegressor().fit(x_trn,y_trn)
plt.scatter(y_trn, m.predict(x_trn))
<matplotlib.collections.PathCollection at 0x1c135cc9e8>
Run our Basic Regressor - Test dataset
This will not work, because this new data is beyond the range of what the tree has seen. This is because the previous tree can only give the overall average of the subdivisions. Since this data is new, it will be all put in one group (the largest one) and will be assigned a constant value
Alternatives : use Neural networks
De-trend the data and then use a Random Forest
plt.scatter(y_val, m.predict(x_val))
<matplotlib.collections.PathCollection at 0x1c13743f28>