I’m trying to make sentence vectors to encode semantic similarity. The basic idea being that sentences with the same meaning should have the vectors that are close together.
Verified that it trained properly by inspecting the sentences that it produces. New sentences sound like ones from the corpus. Training achieved a perplexity of 14.80.
Added a new head the to model to average the hidden states
Here is the new head class, based on the PoolingLinearClassifier:
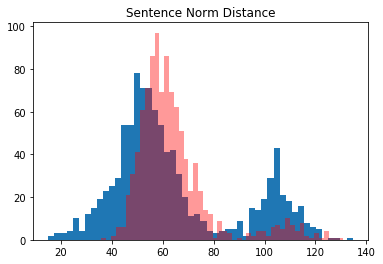
I’ve decided to continue with my plan of using the TripletMarginLoss loss function, even though the vectors aren’t very well separated in the original LM.
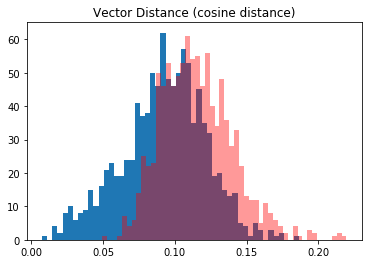
After training, the histogram looks much nicer, but the results are only marginally better. I’m only getting 65% accuracy on the SNLI corpus. I need to get in the 80+% range for this to be a useful technique.
I’ve switched to trying to just do sentence pair entailment classification using a siamese architecture.
I’ve made my notebooks for this available on GitHub at SiameseULMFiT.
What I did was:
Take the lesson 10 network and retrain it on the SNLI corpus
Use the new ULMFiT network as a sentence encoder for a siamese model
Run the each sentence through the encoder and concatenate the 2 vectors
Pass the new vector to and FC linear classifier network
Unfortunately I’m only getting about 40% accuracy (33.3 would be random). It seems like it should be able to much better than that.
I don’t know what I’m doing wrong here. Anyone have some insight to share?
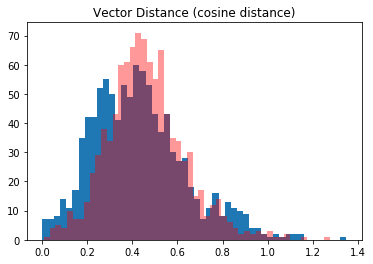
As an interesting point of reference, I took the sentence encodings from InfraSent and did the same comparison of vector distance. It resulted in a very similar amount of overlap.
This is a very interesting piece of work, and I’m looking to do something similar. I’m using InferSent at the moment for somewhat similar work.
I’ve never done more than use sentence embeddings, so I don’t know what a good metric is. I have heard the AllenAI people being quite critical of the idea that they can work well at all. Their work on ELMO was intended to make them more contextual, which I guess what a LM-based model should do too.
I don’t have any specific suggestions, but if you are willing to share your work somewhere I’d like to try it too.
Hi Nick,
I haven’t looked at ELMO in detail yet, but I will.
You can see my latest attempts at using ULMFiT to with a siamese network topology here: https://github.com/briandw/SiameseULMFiT
I don’t have the embedding analysis in that repo yet because the vectors aren’t very good.
I’m not entirely sure how this works, but wouldn’t it make sense to try to get the weights from the final LSTM layer (or maybe concat all three) rather than pooling?
There’s probably something I’m missing here though.
Good question about pooling. My intuition is that pooling will allow the network to more effectively pull features from the entire sentence. Pooling is what was used in the ULMFiT That said, I have tried to use just the final hidden state and the results were much the same.
The results claimed by ELMO are quite good, 88% on SNLI. I’m going to dig into that and see what they are doing.
This paper has a seemly comprehensive look at the latest sentence embedding techniques. https://arxiv.org/pdf/1806.06259.pdf
ELMO and InferSent are the top performers.
One thing I noticed is that InferSent is using Bi-LSTM layers. I’m not sure why ULMFiT doesn’t use bi-directional LSTM.
Any more thoughts on SiameseULMFiT ? Would you recommend anyone to use or build off of this approach, or should we give up? Any thoughts on why it why it worked or didn’t work?
I haven’t really worked on this for recently. I got into the 80’s with my SNLI test but I was really more interested in sentence vectors and that wasn’t successful.
If I were to take this up again, I’d start by using sha-rnn and adapting the simCLR paper for NLP tasks.