I haven’t been able to find any documentation on the layer parameter in get_tabular_learner function
i.e
learn = get_tabular_learner(data, layers=[500,100], metrics=accuracy)
does anyone know what layers is and what it does
I haven’t been able to find any documentation on the layer parameter in get_tabular_learner function
i.e
learn = get_tabular_learner(data, layers=[500,100], metrics=accuracy)
does anyone know what layers is and what it does
It refers to the sizes of the hidden fully connected layers between the input (after embedding) and before the classification layer. The number of hidden layers is determined by the length of the list. So in your case you’ll have two hidden fully connected layers of size 500 and 100 respectively.
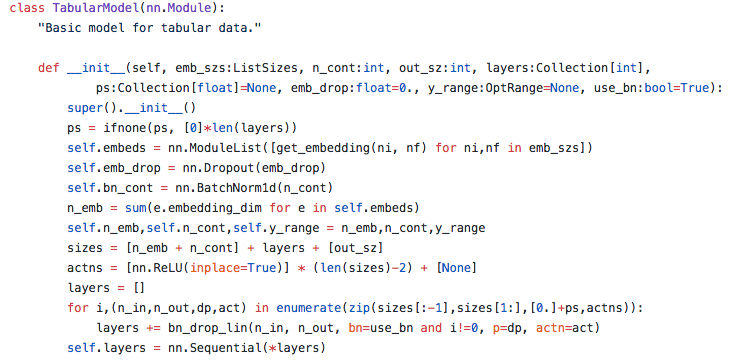
Edit: This snippet from tabular/models.py should make it clearer …
@Jan I think you answered what it is but still remains what it does.
I n reference to the list of layers that @tbass134 used below, is there any rule of thumb for how many layers one should have or how large the layers should be for a given problem? I think this would help me to understand what it does better.
I am also looking for tips on this.
Bump. Also looking for advice on rules of thumb for how many layers to use
Same issue. Documentation and courses even completely gloss over it. I’m working with tabular data.
Also curious to know whether there’s a general heuristic to determine size of layers
Same issue.
I’ve been using tabular learner for a few kaggle competitions and one thing I will always do is try to overfit the data in 1 epochs (or sometimes, 1 single batch) to make sure the model is good enough, and then apply regularization techniques. It really depends on the dataset you are working on and how much data you have, but I would start with [500,200] or even [1000,500] for bigger dataset and adjust the model from there.
@quan.tran Still overfitting is really hard. I was using [10000,500] with a small dataset with wd=0.0001 and the model still didn’t overfit 
Also if I remember correctly, Jeremy mentioned that small datasets are easier to overfit.
Sometimes a small enough loss is good enough instead of having train loss >> val loss. Adding more hidden layers ‘might’ help. Or at least in tabular we can still do some feature engineering to ease up the model.
Have you done any experiments with the number of layers in your model?
How do we know how many layers are in the model? Like the architecture is input, matrix multiply, non-linearity, output as stated in the course but according to this code, how many and which layers do we have in this model?
Did any of you guys make progress on this? I’m trying to learn more about this subject as I tackle Kaggle’s House Prices dataset. Thanks
You can find an attempt to it here:
https://forums.fast.ai/t/an-attempt-to-find-the-right-hidden-layer-size-for-your-tabular-learner/45714