Hello stefan,
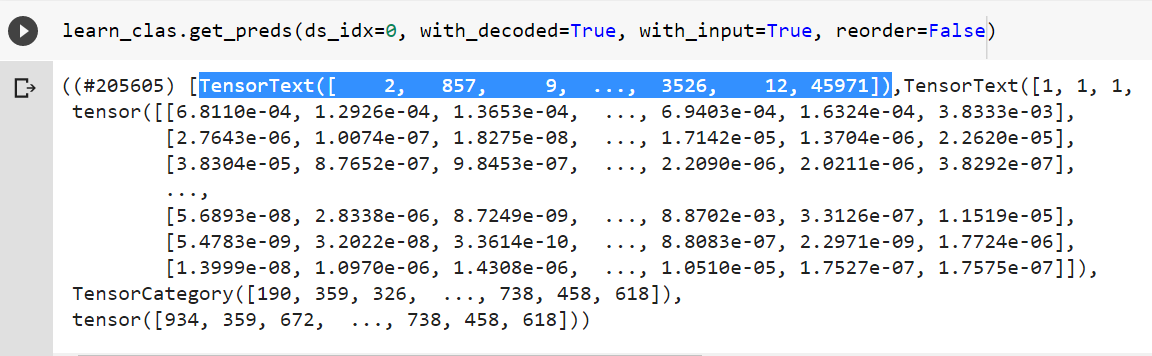
I did use the code for validation and it worked. However, if I use it for fetching predictions on my train using the code below, I get this error. Any idea what could be the issue
probs_train, targets_train, preds_train = learn_clas.get_preds(ds_idx=0, with_decoded=True)
Error stack trace:
RuntimeError Traceback (most recent call last)
in ()
----> 1 probs_train, targets_train, preds_train = learn_clas.get_preds(ds_idx=0, with_decoded=True)
1 frames
/usr/local/lib/python3.6/dist-packages/fastai/learner.py in get_preds(self, ds_idx, dl, with_input, with_decoded, with_loss, act, inner, reorder, cbs, **kwargs)
240 res[pred_i] = act(res[pred_i])
241 if with_decoded: res.insert(pred_i+2, getattr(self.loss_func, ‘decodes’, noop)(res[pred_i]))
–> 242 if reorder and hasattr(dl, ‘get_idxs’): res = nested_reorder(res, tensor(idxs).argsort())
243 return tuple(res)
244 self._end_cleanup()
/usr/local/lib/python3.6/dist-packages/fastai/torch_core.py in tensor(x, *rest, **kwargs)
125 else _array2tensor(x) if isinstance(x, ndarray)
126 else as_tensor(x.values, **kwargs) if isinstance(x, (pd.Series, pd.DataFrame))
–> 127 else as_tensor(x, **kwargs) if hasattr(x, ‘array’) or is_iter(x)
128 else _array2tensor(array(x), **kwargs))
129 if res.dtype is torch.float64: return res.float()
RuntimeError: Could not infer dtype of iterator
Regards,
Chaitanya Kanth.

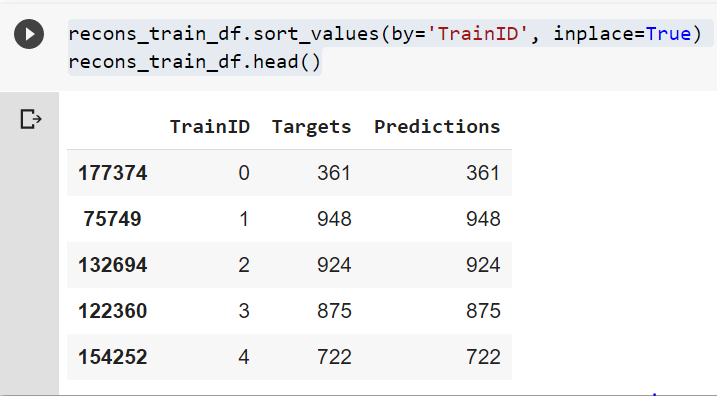
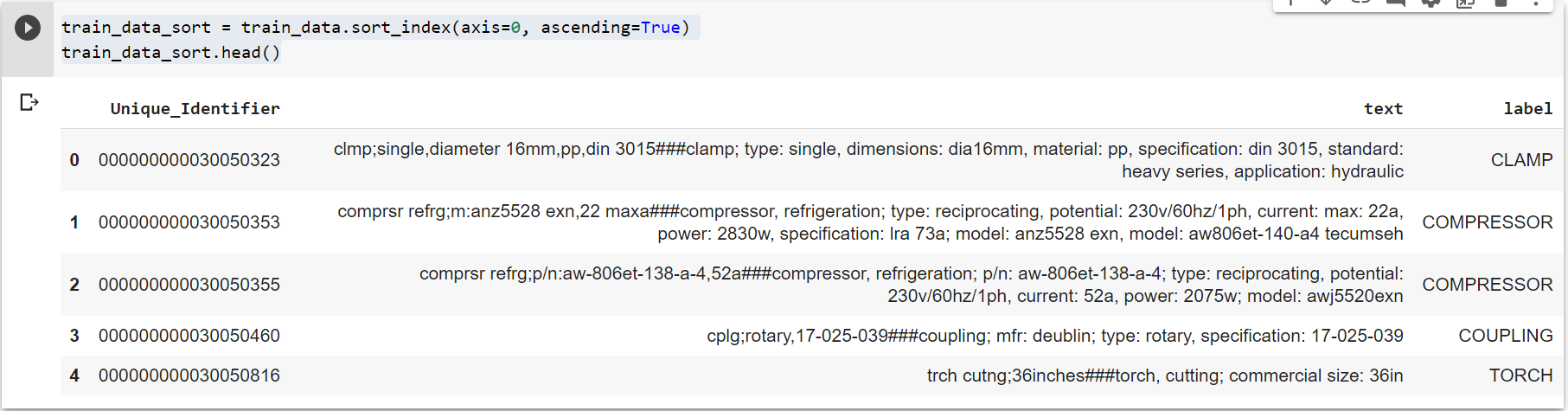
 The procedure I described is a bit of an unforunate workaround but it always worked for me.
The procedure I described is a bit of an unforunate workaround but it always worked for me.