Piotr,
Thank your for these helpful pointers! I am definitely looking forward to seeing The Model Zoo populated!
Can’t wait to check out the QRNN pretrained LMs you generously pointed to, not sure yet if I know how to surmount the CUDA obstacles you are indicating, but will try (I have a GCP account as well).
There is a chance it will work out of the box on Collab, the issue is caused by Cuda 9 not supporting the newest gcc. To fix it I had to install gcc version 5.
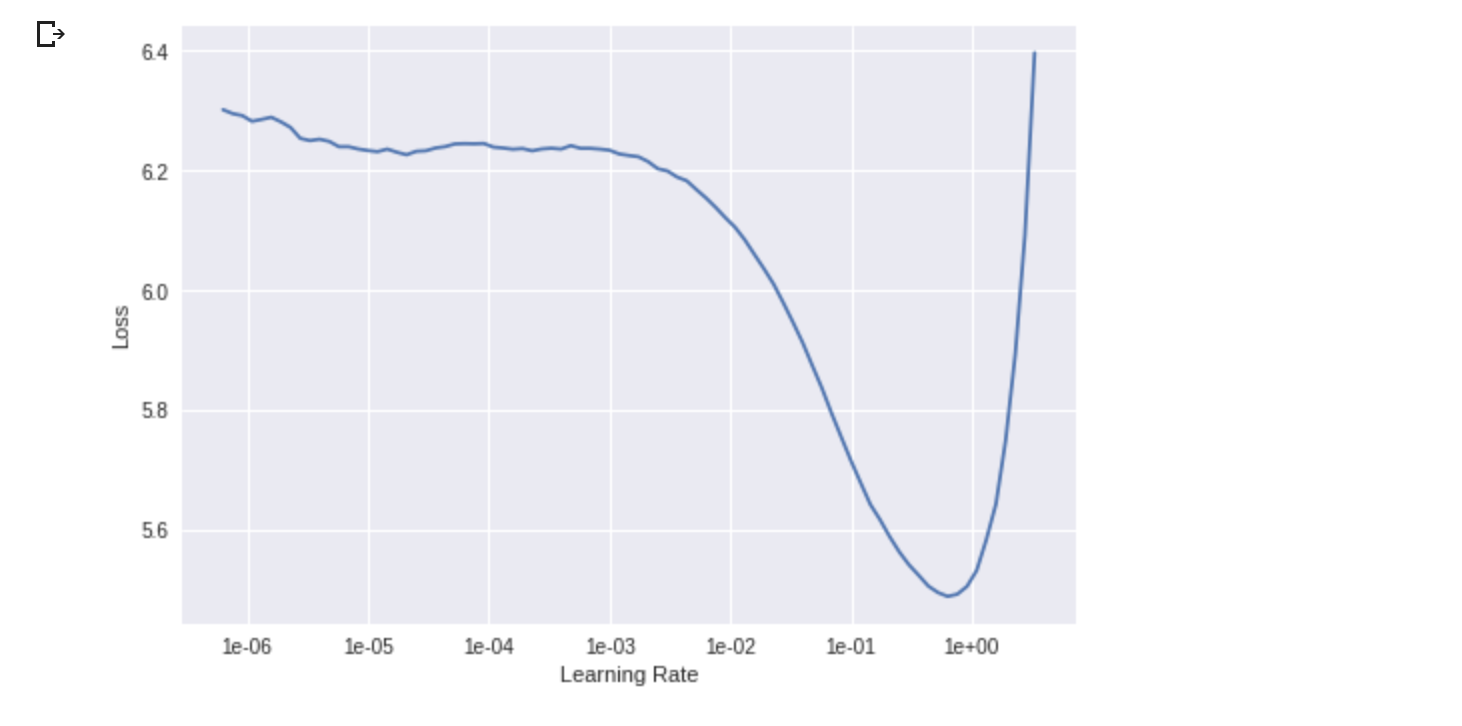
Yes, of course, I will, as soon as I have something more to show. Colab just finished the first learning rate search (which is further than I got with the other pretrained models, thank you @jyr1).
Quick sanity check Piotr. I’m currently rebuilding my old model and it takes a lot longer than previously. How long did it take you to train 1 epoch for the German LM with fast.ai v1 (and on what hardware)?
It currently takes me 15h and previously it was 2-3h. Would appreciate a quick “nope, we trained one epoch quite quickly” so that I know I can keep searching for the cause
~1h for qrnn and 2h lstm, all 4layers on 1080 TI. You can check the logs here, some of them have the training time as Sylvain added that to the progress bar.
Most of the training was done either on 1080ti or v100
I have used the pre-trained model from @jyr1 on the datasets from here GermEval-2018-Data.
The dataset contains 5009 tweets as train-set and ~3300 as test set.
The model achieved between 66-70% which is random as the labels are in the ratio 2:1(OTHER:OFFENSE).
Could any of you post something If your model achieved better result?
As written earlier by @jyr1 that his model achieved 93% accuracy on Amazon Review dataset. Could you(@jyr1) apply your model on the dataset link given above and tell us if the model has achieve such a high accuracy even on Twitter dataset?
It will be great then!!
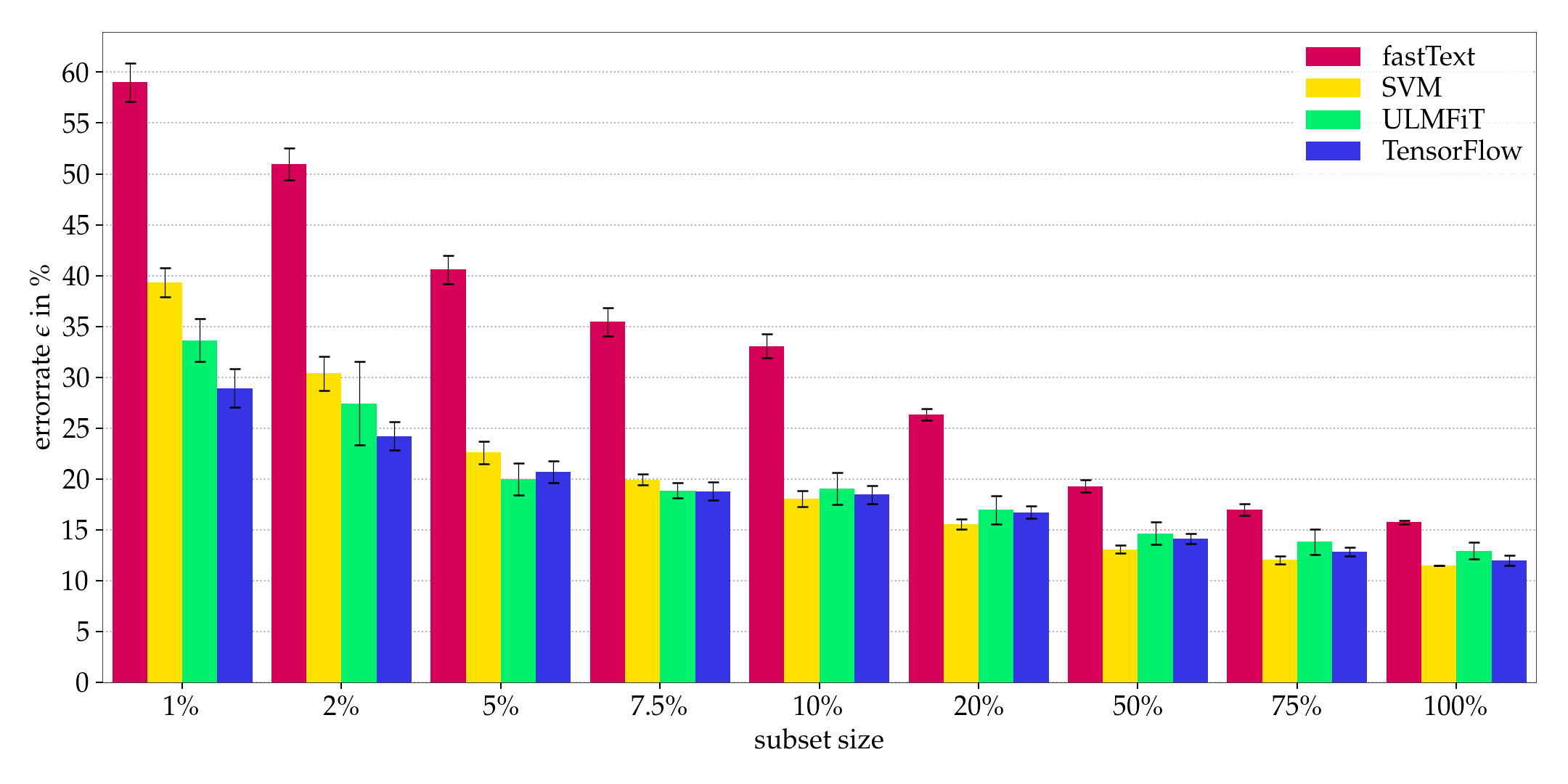
I quicky summarize the results. The goal was to compare the ULMFiT sample efficiency to other methods. Howard and Ruder call the ULMFiT method “extremly” sample-efficient in their paper. I’ve got different results for the 10kGNAD.
To evaluate the sample sample-efficiency I trained ten models for nine subset sizes raging from 1% to 100%. I report the average error rate for the fastText library, a Support Vector Machine (SVM), a TensorFlow NN and the ULMFiT method using sub-word tokeniziation.
For the smaller subsets the TensorFlow NN has the highest sample-efficiency, for the larger subsets starting from 10% the SVM outperforms. The ULMFiT method has a higher sample-efficiency only on the 5% subset. I can’t say that the ULMFiT method is “extremly” sample-efficient on the 10kGNAD.
Keep in mind that I was quite limited in terms of GPU power, so someone might be able to find better hyperparameters than I did. Additionally experiments on one dataset are hardly representative for the german language or other languages.
I didn’t share a classifier, only a pretrained model. You’d still have to finetune it and actually create the classifier. Or did you do this? Not entirely clear to me. Applying the classifier I trained on Amazon data doesn’t make sense, as it would distinguish negative from positive, but not offense from no offense (you can be very negative but not offensive, for instance).
I can’t check your notebook as the github viewer isn’t working but I have a feeling what can be the issue.
Have you finetune the ulmfit on the entire dataset? I think the point with “extreme sample-efficiency” is that you use all your unspervised text that can be very large. And then only use few labeled examples. The reasoning behind this is that the raw text is cheep, labels are expensive.
I’m currently working with your pretrained weights and it works great!
Thank you very much for your work.
Can you please priovide additional information about the weights?
Why did you “only” choose a vocab-size of 30k?
How many wikipedia articles have you used in total?
And how many words do the articles contain in total?
I as well trained a German language model with sub-word tokenization. You can download it on GitHub and I also give more background information there: https://github.com/jfilter/ulmfit-for-german
I experimented on 10kGNAD and achieved an accuracy on the validation set (1k samples from the training set) and test set of 91% and 88.3%, respectively. Check out the notebook for the details.
I trained a German Language Model on TransformerXL, just slightly adapting your Spanish LM code, (Thank you for your work and for @kaspar’s hyperparameter experiments !)
on a dataset of ≈ 100 million words from German Wikipedia (10% of all articles with > 1000 chrs)
with a 60k vocabulary size, mem_len=50 (to increase training speed)
reaching a perplexity of best validation loss of 18.9, but:
the OOV/out of vocabulary percentage is quite high: 6.5%-6.9% (train and valid set respectively), making the low validation error & perplexity less meaningful (as @piotr.czapla explained further up)
EDIT: it seems that under fastai 1.0.52 Transformer.py isn’t fully functional - the fastai wizards already repaired the problem, we should either wait for the next fastai release or stay with 1.0.51, if using Transformer, Sylvain Gugger suggests.
Hello, I am trying to clone the multilingual ULMFiT from GitHub in Google Colab. However, I keep running into the error below. I tried the various suggestions on StackExchange to no avail. I’m quite new to fast.ai so I have no idea what’s going on. Any help would be appreciated.
ERROR: Command “python setup.py egg_info” failed with error code 1 in /tmp/pip-req-build-rrjon9hs/
As an alternative: We have just decided to share our German BERT model with the community. It outperforms the multilingual BERT in 4 out of 5 tasks. You can find model and evaluation details here. Hope this helps some of you working on German NLP downstream tasks!