Thank you for sharing this! Reading your blog post re: training another model with more data - Are you considering training a German GPT-2 (345M)? That could take Natural language generation in German (which seems hard/unfeasible with BERT and is generally lagging behind English NLG) to a new level.
Our priority for now is training more BERT models on larger datasets (incl. domain specific ones) and simplify the usage for standard downstream tasks like document classification, NER, QA …
But maybe we afterwards move on to GPT-2 (or whatever NLG model is out there by then).
1 Like
Have you considered getting the model exposed through pytorch.hub either through fastai repo or huggingface?
It would be nice if someone could simply state:
tokenizer = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'bertTokenizer', 'bert-de-deepset-base', do_basic_tokenize=True, do_lower_case=False)
1 Like
From my understanding there is no pretrained german language model for ULMFiT working for the current fastai v1.0.54?
Even @jyr1’s model gives me an error when I try to load it:
weights='30k-pre-ger'
vocs='30k-pre-ger-itos'
learn = language_model_learner(data_lm, AWD_LSTM, pretrained=False, drop_mult=0.5, pretrained_fnames=[weights, vocs])
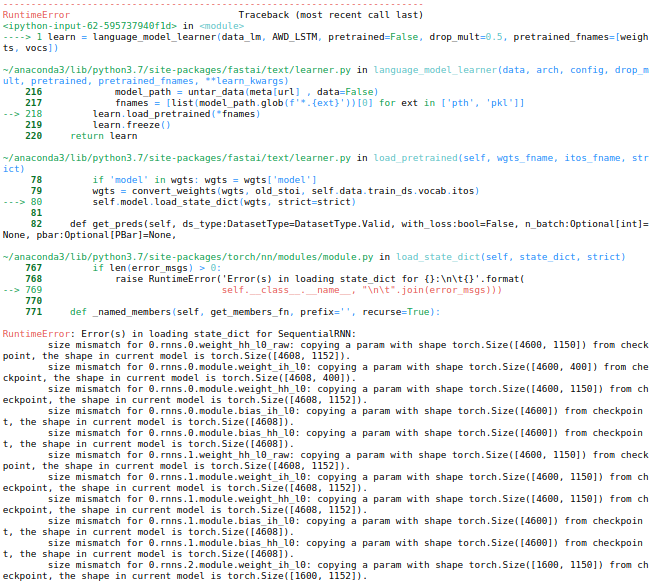
That’s due to all language model shapes being divisible by 8 as of fastai 1.0.53 by default (reason: half precision training is much faster this way). Thankfully, Sylvain Gugger posted a workaround here:
2 Likes
I was completely unaware of that. Will try today, thank you!
Hi
Is there a trained German model in the meantime that can be downloaded somewhere or will the ‘official’ German model come out soon (in the official model zoo)?
Regards, Felix
Hi @felixsmueller. @jyr1 trained a language model a while back that works well for me:
If using a recent fastai version (1.0.53 and later), you will have to read in the weights according to Sylvain Gugger’s workaround (see post a bit further up).
Thanks a lot.
Just some more descriptions for newbies like me:
Download the language model files (from ULMFit - Google Drive) and store them into your Google drive account.
#Then the following code allows to access your Google drive:
from google.colab import drive
drive.mount(‘/content/gdrive’, force_remount=True)
root_dir = “/content/gdrive/My Drive/”
base_dir = root_dir + ‘Colab Notebooks/FastAIGermanModel’ #Adapt path
#The following code then reads in the model:
FILE_LM_ENCODER = base_dir + ‘/30k-pre-ger’
FILE_ITOS = base_dir + ‘/30k-pre-ger-itos’
config = awd_lstm_lm_config.copy()
config[‘n_hid’] = 1150
learn = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=[FILE_LM_ENCODER, FILE_ITOS], drop_mult=0.3)
1 Like