Hi @tblock,
I am also doing similar works and I am using the dataset from your repo.
Unfortunately, the dataset has more than one delimiters for certain rows.
Is “;” the delimiter, if yes then there are more than one for certain rows.
Is my understanding is right or?
Hey there,
I’m quite new to this field and I’m wondering if there are already language models for German that I could use? So If I’m considering doing a new project on text classification, what would you recomment?
Going through the UMLfit Steps myself?
Thanks in advance!
Dear @tblock,
Thanks a lot for your reply.
Regards,
Pappu Prasad
Dear @LisaN,
There are number of approcahes that achieved state-of-the-art(SOTA) scores.
Its a evolving field where an approach which published few months ago became a “classical” approach and something new takes over. See openAI GPT-2 for example.
Since you are new to this field, I would recommend you to go through some baseline models such as RandomForest, SVM, …etc.
See their approach and build you basics.
Then go for ULMfiT.
Other models to look for after mastering ULMfIT: Google BERT, ELMo, openAI, tranformer XL(please check in internet for correct names).
I hope these tips will be useful to you 
Regards,
Pappu
Dear @Skeptic,
Thanks for the advice. I did some basic Neural Network and SGD models in Scikit Learn and Tensorflow, but I’m trying a little project on german language now - of course I could do it without using a pretrained model, but I’m wondering if anyone of you already used a pretrained model on German language and if so, would you only “trust” your own or would you reuse others?
And if you reuse others, which ones? I found one here in this Thread - thanks by the way, (https://lernapparat.de/german-lm/) but it didn’t work on the first try. So do you think I should invest time on making that one run or should I create my own?
Being state of the art is not that important to me, I just want to do good 
Hello @LisaN ,
That language model (generously provided by @t-v, thank you!) didn’t work for me either on my first attempt. I tried:
learn = language_model_learner(data_lm, arch = AWD_LSTM, pretrained = False, drop_mult=0.3)
learn.load_pretrained(wgts_fname=“German-LM/DE_model_dropout_0.1_1cycle_10epochs.pt”, itos_fname=“German-LM/DE_spacy_itos.pkl”)
… but I got this error message:

I’m not sure, it might have something to do with the fastai library developing/changing fast? Thomas’ model was from last summer, I believe.
What problems did you have while trying to import the language model?
If we don’t find an easy fix we might ask Thomas for inspiration&enlightenment.
I am very interested in using the same model as a basis for further fine tuning my pet project (text regression on German fiction).
All the best,
Johannes
1 Like
Hey @jolackner,
wow, cool (for me) that you are encountering the same problem! So your code looks as if you want an empty Learner first and then load the pretrained in, right? That was also one of my attempts. I downloaded them into the working directory - but also renamed them (DE_model.pt and DE_itos.pkl) because I considered two dots in a Filename might not be good.
The second attempt was going in the pytorch direction as described here. This one can load the Model weights via
DE_model = torch.load(’/kaggle/working/DE_model.pt’, map_location=lambda storage, loc: storage)
and the pickle goes like this:
DE_itos = pickle.load((Path(’/kaggle/working/DE_itos.pkl’)).open(‘rb’))
So I was able to load the weights and the Pickle but didn’t know how to build the Architecture from there…
I tried
learn = language_model_learner(data_lm, arch=DE_model, model_dir=path vocab=DE_itos)
Which gives me this error:
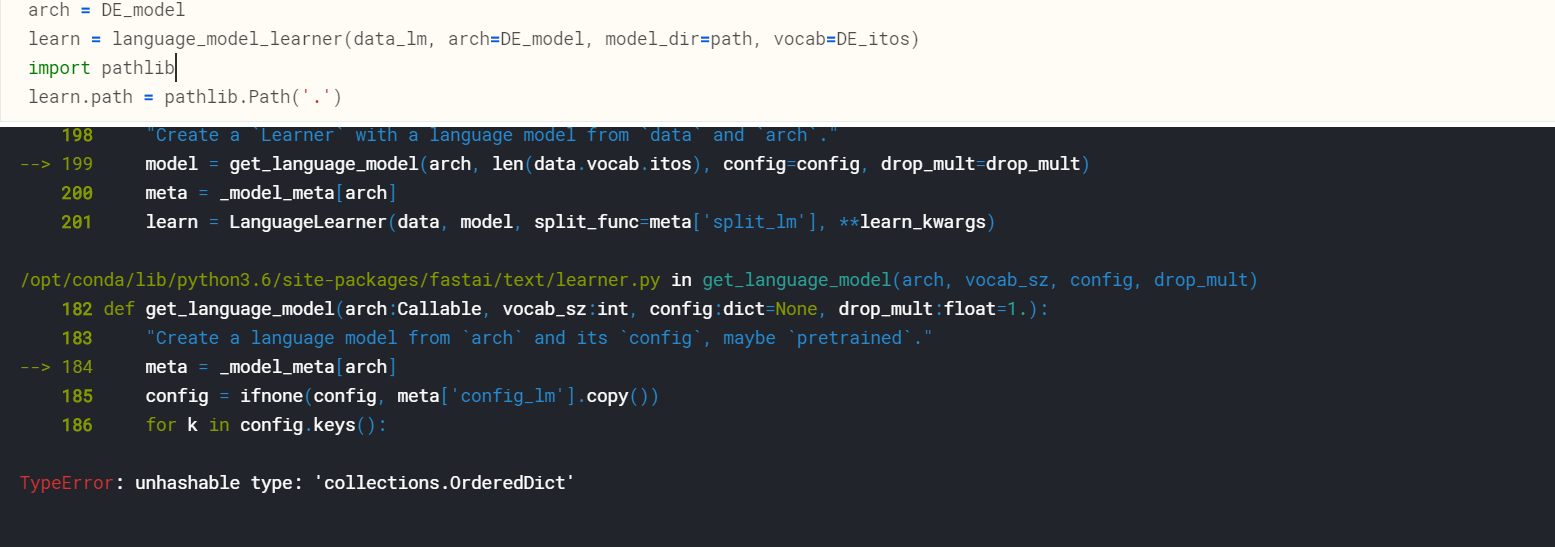
TypeError: unhashable type: ‘collections.OrderedDict’
I must admit - I don’t know what I’m doing, sometimes I copy and run…
1 Like
I think there’s only three predefined architectures you can load for the time being, see the fastai docs here:
https://docs.fast.ai/text.learner.html#language_model_learner
Trying to do arch=DE_model wouldn’t work, according to the docs. I guess you’ll need arch= AWD_LSTM . And then you would load your custom DE_model via
load_pretrained (https://docs.fast.ai/text.learner.html#RNNLearner.load_pretrained)
This just for now, I’ll provide updates if I can get the pretrained language model to work.
I pretrained on german wikipedia data and scraped about 60k~ german amazon reviews to ultimately create a sentiment classifier. It achieves about 93% accuracy on training, validation as well as an independent test set so I’m happy about that.
If it’s helpful for anyone I’ll upload my pretrained model here.
2 Likes
Hi,
that would be wonderful! How long did it take you to train?
Hi @jyr1,
It will be a great help to me or to the community.
Please do provide a link of your work.
The pretrained model discussed here is neither working for me.
Thanks in advance
Regards Pappu
About 12 hours on a Tesla P100 (Google Cloud). To be honest I don’t have much other details as I was merely interested in sentiment classification and not the preliminary steps.
Anyways, here’s the link, the vocab is 30k. You can load the model directly in language_model_learner using the pretrained_fnames argument.
https://drive.google.com/open?id=1gkuY3Tz6LBmcehAnZ95jssV80CBQh7L1
3 Likes
Hi @jyr1,
Thanks a lot for sharing and highly appreciate your work.
Could you also give the link to the Amazon Reviews, if I can check against that data-set?
Regards,
Pappu
We have 3 pre-trained models for German and we are working on incorporating them to the fast.ai library. Two of them are using SentencePiece and one is using vocabulary. The only issue with our models that they are using QRNN which is faster than LSTM but you need a functional CUDA compiler in your path so that Fastai can build the necessary modules for you.
The issues you are experiencing with previous models are most likely caused by changes to the fastai library. If you can’t wait, go to the GitHub - n-waves/multifit: The code to reproduce results from paper "MultiFiT: Efficient Multi-lingual Language Model Fine-tuning" https://arxiv.org/abs/1909.04761 there is a version of ULMFiT extended with setence piece and we have pretrained models here: https://drive.google.com/drive/u/0/folders/1t3DqH0ZJC2gDMKEq9vTa5jqxBiVAnClR
We are working to address, stay tuned ![]()
Apparently BERT and Facebooks LASER have worse performance than ULMFiT for classsification task we checked. Have a look here on the results: https://github.com/n-waves/ulmfit-multilingual/blob/master/results/MLDoc.md
Really cool. Why have you used only 30k words?
2 Likes
Thank you for sharing, that’s great! Running your model on Colab seems to be working without hiccups so far.
Have a great day & Tschüs
Johannes
Cool, can you share your notebooks so others can see how to run it?
Piotr,
Thank your for these helpful pointers! I am definitely looking forward to seeing
The Model Zoo populated! 
Can’t wait to check out the QRNN pretrained LMs you generously pointed to, not sure yet if I know how to surmount the CUDA obstacles you are indicating, but will try (I have a GCP account as well).
All the Best from Geneva, keep up the great work
There is a chance it will work out of the box on Collab, the issue is caused by Cuda 9 not supporting the newest gcc. To fix it I had to install gcc version 5.
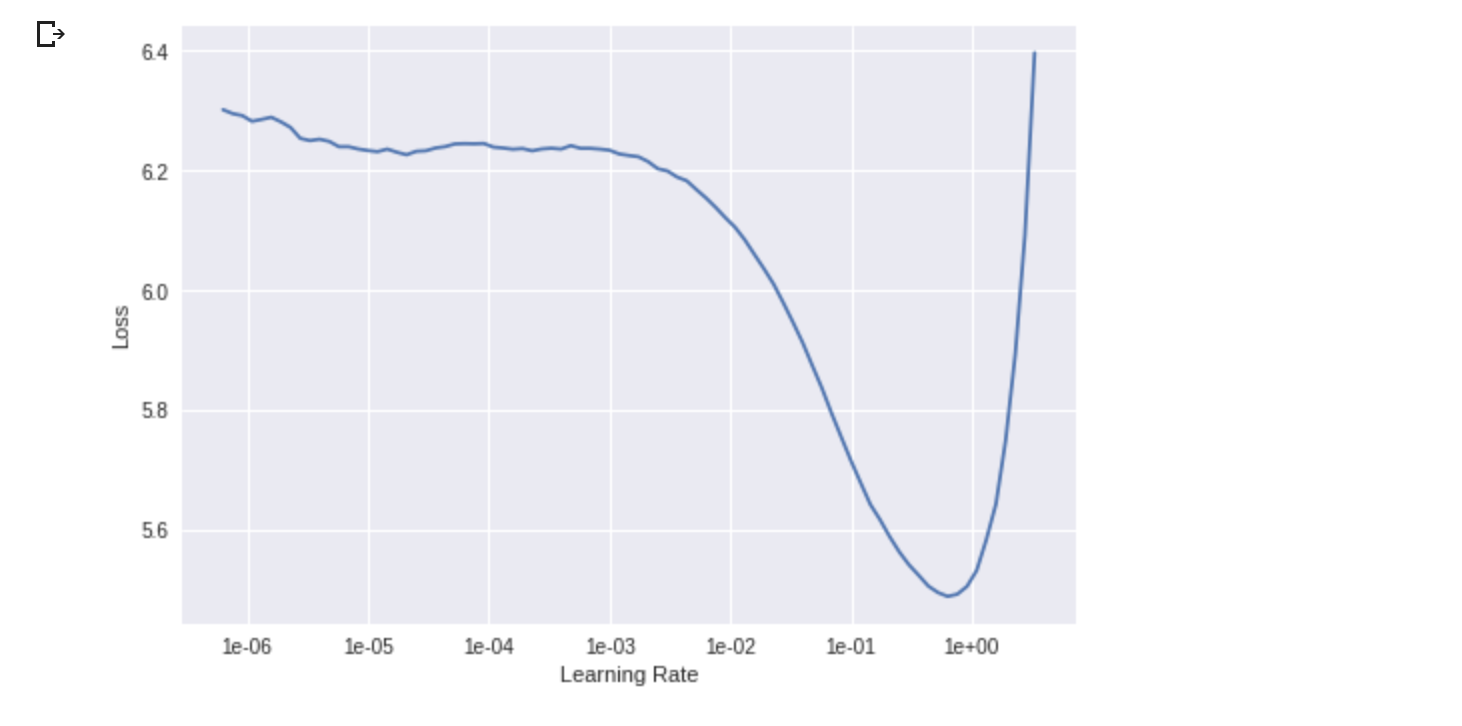
Yes, of course, I will, as soon as I have something more to show. Colab just finished the first learning rate search (which is further than I got with the other pretrained models, thank you @jyr1).