The idea is to use such dictionary such as (https://emojipedia.org/) translate the emoji description to german and replace the emojis with this translations.
So this " " would be translated to "<e>Lächeln</e>".
That way model will be able to use it knowledge about words to interpret emojis and we might get better results.
I’m more for testing multiple vocab sizes. in Poleval lager, vocab did not correspond to better accuracy. In fact we decided to go with 25k vocab size as it was better performing than 50k.
That changes a lot, thank you for explanation!
We haven’t tested the vanilla ulmfit, that much. with Sentence Piece the vocab size 20k-25k worked the best. Attached is our experiments (up_low means that we haven’t normalized for the case, most_low means that we lowercased all first letters of words and left other letters untouched )
Wouldn’t it be possibly better to process the emojis simply as emojis, because the weight of their meaning can be stronger than the usage of a similar word. Or shouldn’t they at least be somehow tagged by a token to mark that it is an emoji transferred to a word?
3k emoji doesn’t sound like a lot I’ve found a few lists with names in German, if you speak German well you can select one (or find a better list) that is most appropriate for our task:
Could you already get the first list with jQuery?
(The approx 2,7k emoji are so much because they have every type of emoji, like different color versions, as well in their list. With that it is not so much. )
I am playing around with beautifulsoup and python more or less successfully to get the list from the last link.
If you have the first list already in python I would guess we wouldn’t need other lists on top and check this one more in detail?
I can have a look at the lists (german is my mother tongue), and then upload it somewhere.
thanks for verifying the lists and implementing an import script. The jQuery code was broken, because I formatted it here using a block quote instead of a code block and as a result apostrophes were changed into unicode qutoes ‘’. It’s now edited and works (you can paste it into a web console), but the great thing is that we don’t need it. After your message I’ve started checking a license of the first list and found the source on https://unicode.org/repos/cldr/trunk/common/annotations with much more languages And it’s all in xml. I’m going to test if it helps with classification and I’ll keep you informed.
Good to know that your a native German speaker. Have you already played with ULMFiT, i.e., predicting an end of sentence based on the beginning (Language model text generation giving weird results in a consistent manner)? I was fiddling with Polish language model and I’m surprised how well it is in declension and conjugation, maintaining even long distance dependencies.
that XML-file is great!
If you have results let us/me know.
So far I just played around with the ULMFiT RNN with non-language sequence data.
But I am still trying to get a setup which trains in a reasonable time.
I have to see how I will proceed with this, as I will need more GPU power than I have currently available.
Remove double+ occurrences (for eg. !!! ---- …) or substitute with single occurence.
URLs are coded as <url> and Emails with <email>
Any @mentions of Deutsche Bahn are coded as <dbahn> and all other @mentions are - coded as @mention
Emojis and emoticons are coded as <e> Description </e> as recommended by @mkardas
^GE '18 data pre-processing steps
Clean dirty characters
Remove double+ occurrences (for eg. !!! ---- …) or substitute with single occurence.
@mentions are chosen based on a frequency count. All @mentions below frequency 10 are simply coded as @mention.
Emojis were kept as they were because no visible improvements were seen from using the encodings in GE '17. Moreover, the tokenization method should very well be able to characterize emojis as a separate unicode entity and the language model should be able to model the occurence of emojis just as well as any other word/character. One possible thing that could be done here is to either space pad continuous emojis such as with and susbtitute double+ occurences such as with .
Performance on downstream task
GermEval '17 sentiment classification task: (SPACY 80K on Wikipedia corpus) Accuracy on validation: 77.89%
These are my numbers so far. EDIT:I will upload my language model, fine-tuned model and the datasets The language model can be downloaded from here, and the pre-processing scripts can be found here and here* for others to experiment with.
Key observation: In terms of LM performance the vanilla spacy tokenization method seems to work better in practice than the sentence-piece implementation. I have not been able to train the SPM based classifier, but I’ll try to get those numbers by tomorrow as well – my guess is that it will not be better than the vanilla implementation.
*@piotr.czapla: sorry for committing directly into your repository, I wanted to commit to my fork but only later did I remember that I had write access to n-waves/ulmfit4de. Please let me know if you would like for me to revert the commit.
Thank you for commiting the notebooks, nice preprocessing. I’m now working on GermEval '18 and use similar preprocessing, the biggest difference is that I encode all mentions, frequent or not. Great idea to left the popular ones untouched. I didn’t encode emails (and it seems neither did you (ulmfit4de/kernels/germeval17-prep.ipynb at master · n-waves/ulmfit4de · GitHub should be _re3?))
It’s hard to tell whether encoding emoji as text helps. In my experiments on GE18 it resulted in test macro F1 increase of 1pp., but the results of experiments vary a lot (training set is almost 20x smaller than in GE17).
Interesting observation, how do you measure LM performance?
It should be _re3, thanks for pointing it out. It must have happened at some later point because all my per-processed data is already encoded correctly.
By “performance” here, I meant the perplexity score on the fine-tuned data – which would naturally affect whatever downstream task we choose to do with the LM.
If you’ll see in the table, the sentencepiece trained model (SENTP GE17)'s perplexity actually dropped after fine-tuning which leads me to conclude that the learned sentencepiece tokens actually failed to capture important “language characteristics” of the secondary (in this case the GermEval '17) dataset.
This could also be a flaw in my implementation: The sentencepieces are trained on the GE '17 corpus and then the pre-training is carried out on the Wikipedia dataset with the GE '17 learned tokens. A second way of sentencepiecing could be as in SENTP DEWIKI experiment where the sentencepieces are learned from the Wikipedia dataset.
I agree, this is something that still needs to be ascertained. Maybe @MicPie will be able to give us some insights.
You mean 52.45 → 82.27? I see that Piotrek had similar increase (WikiDE - sp30k - nl4 · Issue #4 · n-waves/ulmfit4de · GitHub), but in these experiments the sentencepiece model was trained on wiki and there was no preprocessing, so LM had to predict links, user names, etc. The spacy result (75.19 → 58.55) is promising, but for the complete picture we would need out-of-vocabulary rate (i.e., number of unknown tokens / all tokens) for both wiki and GE17 datasets.
The score for the model corresponds to the SENTP GE17 experiment in the table I posted. The perplexity is 52.45 and the accuracy is 0.33*. I haven’t fine-tuned on the GE '18 dataset as yet, mainly because the results weren’t very good on GE '17.
* I’m considering the perplexity score on the validation set.
@tblock let me know how it is going? Btw. Are you sure you can include the scraped text in the csv format? It might be better to include just the links and the code to fetch them from websites, otherwise your repo should have a license: noncomercial research only.

 " would be translated to
" would be translated to 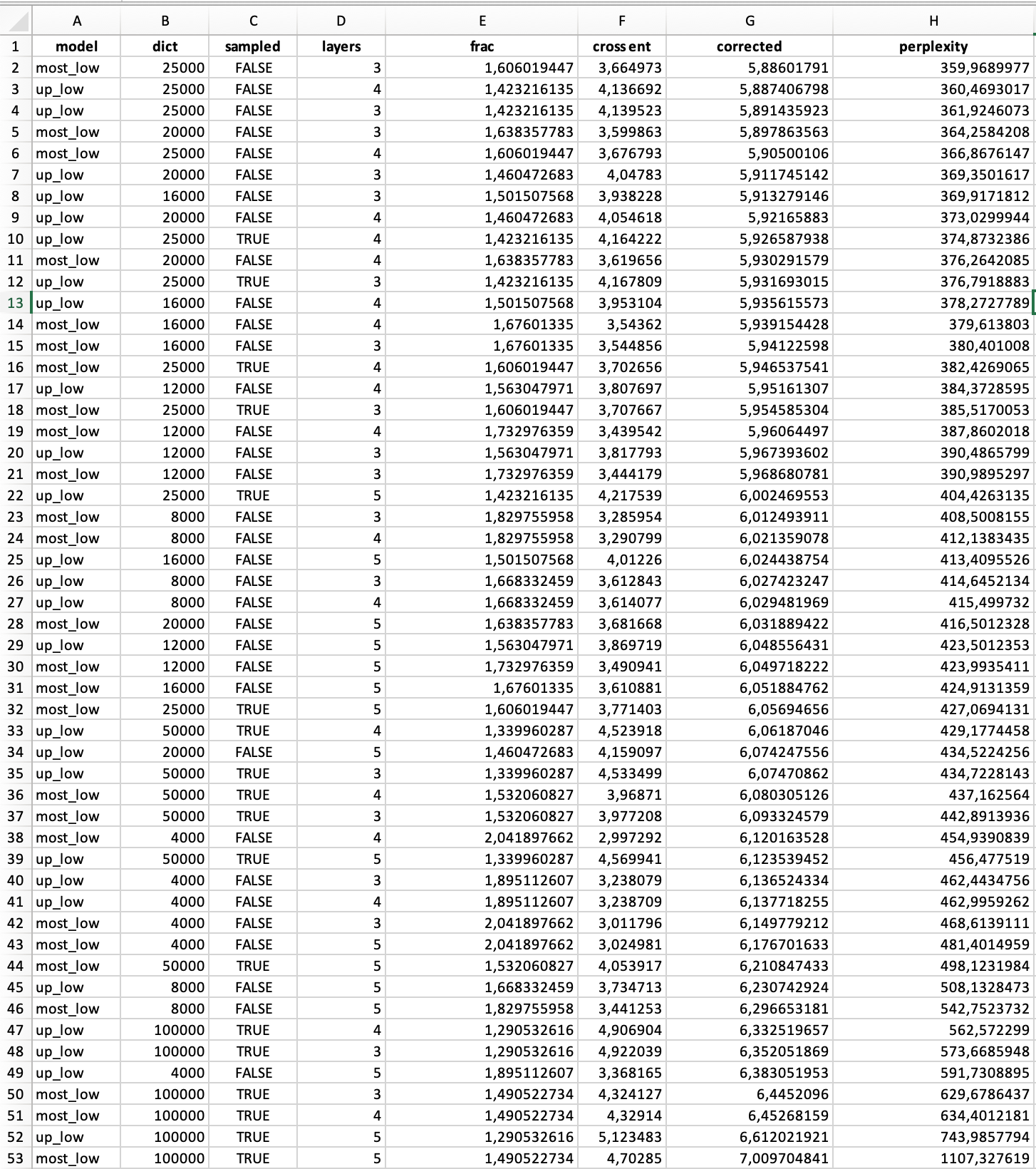
 I’ve found a few lists with names in German, if you speak German well you can select one (or find a better list) that is most appropriate for our task:
I’ve found a few lists with names in German, if you speak German well you can select one (or find a better list) that is most appropriate for our task: And it’s all in xml. I’m going to test if it helps with classification and I’ll keep you informed.
And it’s all in xml. I’m going to test if it helps with classification and I’ll keep you informed.
 with
with 