I’m trying to use the text classifier that is based on the text_classifier_learner and mostly copying Jeremy’s Jupyter NB from the IMDB exercise.
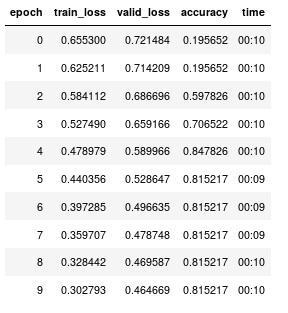
The training starts off weird (detailed steps are below). The accuracy early on is intentionally wrong, as this is a binary classification and I would expect an untrained model to be 50% accurate at first. Then after a bit of training the accuracy jumps from 19.6% to 84.8%.
At this point I expect that if I select some text from the training corpus I should get an accurate classification. Even if I’m overfitting at least the predict should show good performance on the training dataset. However, predict can receive training set text that is classified as either 0 or 1 and this distinction doesn’t appear to have any relevance on the result.
Questions:
- How can I interrogate the training process to see if it is doing what I expect? Any callbacks I should know about? I am only using the SaveModelCallback.
- Any ideas on what is going on with either
predictor my training process that is making this go off the rails? I checked the vocab, but I’ll check this again. Could changing the batch size while saving and reloading various data sets create this type of issue?
I tried to find similar issues in the forums; I think these two links are describing the same thing I’m facing, but I don’t see a solution to their issues:
Example 1
Example 2
Here are the steps I’ve followed, which again are closely following Jeremy’s IMDB NB:
- Load AWD_LSTM into a
language_model_learner(start of ULMFit/transfer learning). Note that lm_TextList below is a set of review texts that I have prepared.
learner = language_model_learner(lm_TextList, AWD_LSTM,drop_mult=0.3)
- Run lr_find, then fit_one_cycle for 1 epoch
- Unfreeze LM using
learner.unfreeze()andfit_one_cyclefor 10 epochs, saving each epoch usingSaveModelCallbackso I can go back/early-stop to whatever model had a good balance of over/underfitting (the 8th in my case). - At this point the LM, via the
predictfunction starts talking like a reviewer, so I know that the LM was trained in the way I expected. I saved the encoder from this 8th epoch output. - LM training is done at this point, and now I move on to the classifier.
- I have manually classified a few reviews and I loaded these into a DF, which I then applied a
train_test_splitstratified by the column that contained my classifications. So far almost exactly what is in the IMDB notebook (above). - The only slight deviation from a simple classification training exercise is the way I declare the TextClasDataBunch:
new_clasif = TextClasDataBunch.from_df(path = "", train_df = df_train, valid_df = df_test,vocab=lm_TextList.train_ds.vocab, bs=128, text_cols=0, label_cols=2)
- Create the
text_classifier_learnerbased on AWD_LSTM architecture and then load the encoder from the LM in.
learnClas = text_classifier_learner(new_clasif, AWD_LSTM, drop_mult=0.5)
learnClas.load_encoder('fine_tuned_encoder_FullSet_091619')
- At this point I use lr_find to obtain LR (2e-2), perform
fit_one_cycle:

- Then I unfreeze the last two layers and
fit_one_cycleon the supervised/classified reviews.
learnClas.freeze_to(-2)
learnClas.fit_one_cycle(10, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))