My thought on that (how can it be that train/valid loss goes down while accuracy goes a little bit up, if that was your question  ) is the following:
) is the following:
Loss is a function that has to be smooth, so every step you take © you can calculate how closer you get to right answer. Accuracy, in contrast, is some kind of threshold-ish function, often it just tell you did you get this answer right or not, it doesn’t care how sure you are in your suggestion.
So let’s look at artificial (and intentionally extreme) example. Imagine you have 5 MNIST digits to examine. So it happens, all the right answers is symbol “7” (foe simplicity).
N-1 steps tells you that for all 5 examples’ probabilities for every class (0-9) are the following: [0.09, 0.09, 0.09, 0.09, 0.09, 0.09, 0.09, 0.19, 0.09, 0.09]. So accuracy is 100% (the biggest probability is for symbol “7” in every case)
Nth step tells you that for 4 of 5 examples it’s [0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.91, 0.01, 0.01] and for 5-th one it’s [0.01, 0.01, 0.01, 0.47, 0.01, 0.01, 0.01, 0.45, 0.01, 0.01]. Accuracy will be less 100% as only 4 of 5 examples were detected correctly. But loss function for N-th step should be lower as net is much more sure in it’s right answers, than on N-1-th step (and got pretty close to 7 in the 5-th one).
Coming back to your case. I think system bouncing around getting one last example right or wrong (it’s accuracy slightly goes both ways), but it is getting more sure in other examples, that it already got right but with less probability (sureness), so losses go down.
Thanks @Pak.
I am really doing a regression here, not a classification. Does your answer still apply?
A little bit aside, but triggered by your response: With classification I understand how you can express confidence, but can you do this for regression as well?
In fact I was replying to @som.subhra question
As for your initial question I’m a little bit confused. In my mind this kind of gap can appear when you don’t apply some technics on validation set. Dropout indeed is used only on test set, that definetly was one of the reasons. But you’ve turned it off. Maybe some part of data augmentation plays its role
For expl its used at training phase, making images a but harder to detect. Are you using some kind of image aug? (Im on my mobile now and cannot look at your notebook)
I now tried to turn everything off that I could recognize as regularization.
learn = create_cnn(data_bunch, models.resnet34, ps=0, true_wd = False, bn_wd = False)
lr = 5e-2
learn.fit_one_cycle(50, slice(lr), wd=0)
But it did not have the effect I was hoping for. Validation loss is still lower:
I also don’t think I am using image augmentation. I can certainly say that I did not turn it on.
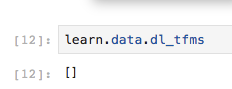
Maybe you could try to use a deeper model, e.g. Resnet50. The current plots indicate that you are underfitting, hence, your model may be not complex enough.
Yes, you’re right about that. Looks like no augmentation is done by default.
I looked at your notebook and noticed that LR_find graph never goes up. This may mean that you can use higher than 5e-2 learning rates. Maybe 100 epoch is really is not enough for this case for this learning rate.
Also if I’m not mistaken you never unfreeze the model, so effectively you use only couple of last layers for training (but since counting squares doesn’t seem to be a hard problem for nn, maybe it has enough layers for the job).
So I’d probably try to use bigger LR (and do another 100 epochs) and try to unfreeze the model (even though it will make learning 100 epochs much longer)
I wonder if the training loss for each epoch is averaged over each mini batch and because your model is getting better from batch to batch, the average is going to be higher than what it would be when loss is calculated at the end of each epoch (what happens with validation loss)?
To test this, perhaps use the same dataset for training and validation?
@ptrampert, thank you. I am really interested in the validation loss being below the training loss.
Even if I would use more weights, this shouldn’t change the general picture, or should it? Both training and validation would use the same model complexity, no?
Hey @Patrick. Thanks for your suggestions.
I would think this should not matter over a couple of epochs.
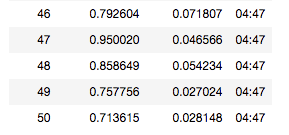
If you look at the numbers above you see that the difference from epoch to epoch within the training loss series or within the validation loss series is tiny. This is especially true, if you compare it to the difference between validation loss and training loss for a given epoch. Agreed?
Anyway, I am feeling my way into this, so I would like to do the test you suggested to get confirmation. What did you have in mind? How would you implement this test?
Let the learner work for 20 epochs and then compare the train_loss of the last epoch with learn.validate(learn.data.train_dl)?
Should I run something like this, but with 20 epochs, not 1?

What would we be looking for in the results? train should then be lower than val, correct?
@Pak, I increased the LR from 5e-2 to 6e-2 and let it train for 100 and then 50 epochs. The training became less stable with the slightly higher LR and I still was not able to lower the training loss under the validation los.
But it is still going down:
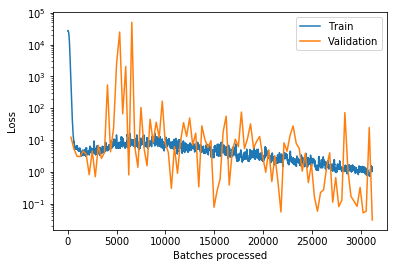
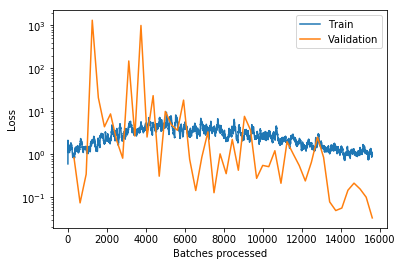
I may try with 200 epochs another time.
@Patrick’s idea looks good too:
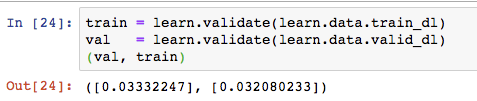
Maybe I need more labeled data to get stable results?
Mariano,
Is it possible to pass the exact same dataset to your learner to be employed as both the training and validation data? You won’t be able to use .split_by_pct() method though. Maybe you’ll have to duplicate the training data and then use another method to inform your learner which indices refer to the validation data or something.
About the complexity of a model: For two architectures with different number of parameters, the one that has more parameters also can fit a more complex distribution.
Taking a two-dimensional example, where you want to fit a function through points. If you fit a simple line when given points from a polynomial you are underfitting, that means you have to increase the degree of the polynomial you are fitting (a line can be seen as a polynomial of degree one). In turn that means you are increasing the number of parameters that are used to fit your function.
Looking at your new experiments it may be meaningful to even increase complexity a little, take e.g. resnet101. As counterexample you could also try resnet18 and see if it gets worse. Also you can try a different architecture. Even if Resnet is considered a default for many tasks, it may not always be the best.
One further point: Set np.random.seed(42) at the beginning of your notebook. That guarantees that you validation set (random split) is always the same, which makes different experiments easier comparable. Also it prevents accidentally wrong evaluations. Just imagine you train a model and save it. Next time you load the model and run some tests, but due to a different split some part of your former training data now is in the validation set. I think you see the point. Sure, it may not help for robustness tests, but that is not the goal at the moment and a different story, I think.
Furthermore, I would not avoid regularization, as this gives the model more flexibility. For your tests at the moment it may be ok, but for a final model I advise against abandoning regularization. However, getting the flexibility right, so that it is no too flexible, may not be straight forward.
Isn’t that what I did above? There I print out the metric mse, which to my understanding, is calculated with all training data of the epoch (and is the same method as applied to the validation set).

So I see the training loss based on the last batch (train_loss) and the training loss of the training set (mean_squared_error), or am I misinterpreting the results or your question?
Thanks. I applied that to the code.
Absolutely. Right now I am trying to establish a baseline where the model overfits and then I would try to heal that step by step.
So your suggestion is to increase model complexity to create overfitting? That is a nice way to put it. Unfortunately I fail to really do so.
The details are in this notebook, but below you will find the graphs. What I was looking for is a point where the training loss gets smaller and smaller and the validation loss gets higher and higher. But I do not see such a point.
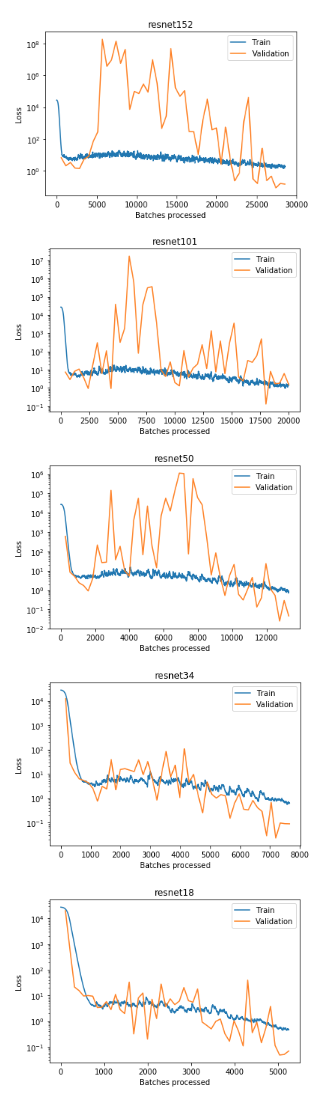
I did not, however, train the more complex models longer than the others. Not sure if this is an issue, but I would try this next. Maybe just for the most complex model.
From the comparison notebook I like the ResNet34 the most. Did I see it correctly, that you always use the same learning rate for all models?
Have you looked into lr_find() for each model individually? From my experience, deeper models need lower learning rates. In general I prefer to converge slower, but more smoothly. The extreme jumping in the loss makes me assume that the learning rate is a problem.
Have you also computed different evaluation measures and how these evolve?
I think that has not to be the case in Deep Learning to find a good model, but at least the validation loss should not be (much) below the training loss. Maybe looking at some evaluation measures, there may be more meaningful trends?
By comparing the graphs it looks like they all behave roughly the same. With a more complex architecture, however, the variance in the validation loss goes up.
I did use the same LR for all, in the hope of making them better comparable.
I have, but honestly lr_find() was hit and miss for me, in both directions. I picked LRs based on the lr_finder that did not progress and LRs where the training loss was jumpy. But maybe I am not reading it right.
I only observed the jumpy graph in the validation loss. My understanding is that the learning rate has no impact here, but the number of samples I use to calculate the loss (higher number of samples would lead to a smoother validation loss graph) and the model complexity (higher complexity would lead to a jumpier validation graph).
But indeed to compare architectures properly, learning rate has to be adapted per architecture, as does the batch size. With respect to the later I let the training run for an epoch, when it does not produce an out of GPU memory error, I increase the bs, until I get an out of GPU memory error and then I backup a bit. It does not feel like the right way. How do other people do that? I also have an eye on nvidia-smi to see how much memory is allocated, but this is not changing the overall process. It just helps to approximate how much the batch size needs to be incremented per step.
Not yet, have you got something specific in mind? For the case at hand, a regression, validation loss based on ( R )MSE sounds perfect to me.
Anyway, thanks for sharing your insights and helping me to get to the bottom of this. I am meanwhile able to produce overfitting and the answer is obvious and has been established a long time ago: More data is a regularization as well.
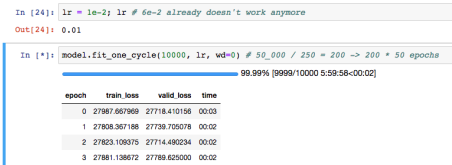
Hence eventually I reduced the number of samples from 50_000 to 250 and now it is overfitting.
Don’t mind the 10_000 epochs. This was a result of making two runs comparable, one with 50_000 samples and 50 epochs and the other one then with a higher number of epochs to normalize the “trainings sightings” in both approaches.
Once again, thanks for your help @ptrampert.
I ran into the same problem where the training loss is always higher than the validation loss no matter what LR I used or epoch I ran (I did it in a loop). Anyone has an answer for this?
Hey John. Can you share some more context?
Could it be that dropout or any other generalization is the cause of the difference?
Hi Mariano:
Thanks for the quick reply. I am happy to report that I was able to get a pretty good learning rate using the following code where the error rate was low and the training loss was lower than the validate loss.
r = [1e-3,5e-3,7e-3]
for i in r:
print(i)
l3 = cnn_learner(data,models.resnet34,metrics=error_rate)
#l3.fit_one_cycle(5,max_lr=i,wd=0)
l3.fit_one_cycle(20,slice(i))
l3.recorder.plot_losses()
So the trick is to use a smaller interval of learning rate and increase the # of epoch until you get the training loss lower than the validation loss.
How is your deep learning journey?