I am absolutely fascinated by the idea of the universality theorem as introduced by Jeremy. I intended to use that to count cars in a parking lot, without neither describing the concept of counting, nor what cars looks like. To approach this incrementally I created a “unit test” first, just count rectangles with synthetic and homogenous shapes. This works great: Notebook here.
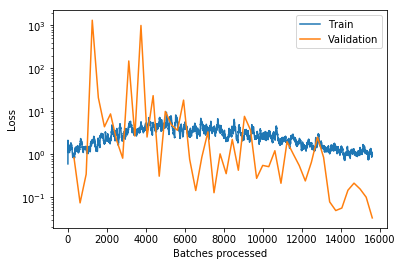
But I also observe that the training loss is greater than the validation loss, basically all the time.
This seems to be a recurring theme. We have a couple of threads here that I read and I also looked into the Disciplined Approach to Neural Network Hyper Parameters - paper by Leslie Smith.
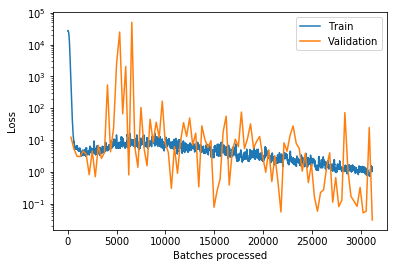
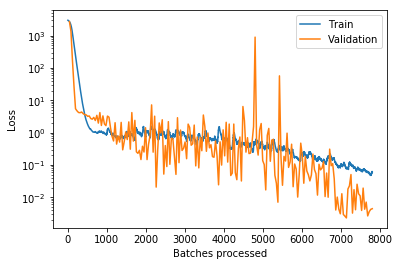
I still do not understand why this happens in my case. Details are in the Notebook referenced above, but the gist in this plot as well:
How can it be at all that the loss on trained examples is higher than when the model is applied to previously unseen examples?
The two suggestions from the threads and Jeremy’s lectures are to (a) reduce the learning late or (b) to train longer.
I don’t understand how this would be applicable to the situation at hand?
With respect to (a) I am using fit_one_cycle() which should limit the max learning rate to something effective and I also already use a low learning rate. The training and validation loss both flatten out and don’t have much variance anymore.
Also (b) training longer, I tried that, does not change the picture. If anything changes than that the validation loss is going up at some time.
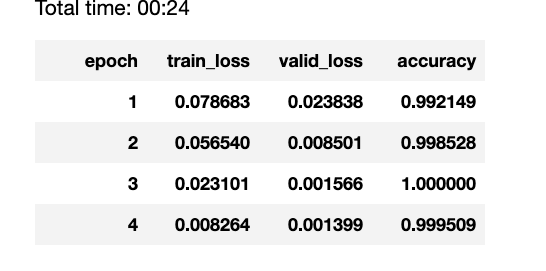
I have a question on the similar lines. I am using a resnet18 model on the MNIST dataset. This the last portion of lesson 1 pets. I see that training and validation loss keeps decreasing. The accuracy reaches 1.0 and goes back to 0.999509 and keeps getting lower. Surprisingly, the training and validation losses continue to go down. How do we explain this ? My understanding is that when the training loss keeps getting lower , but the validation losses starts to increase is an indication of overfitting. But I am not able to construe this. Thanks for your help.
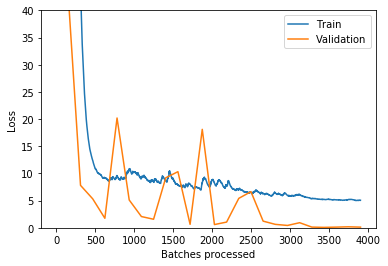
I disabled both dropout and weight decay. I now get closer to the validation error, but it remains that the training error exceeds the validation error:
Details are updated in the same Notebook that I also linked to above.
I am really doing a regression here, not a classification. Does your answer still apply?
A little bit aside, but triggered by your response: With classification I understand how you can express confidence, but can you do this for regression as well?
In fact I was replying to @som.subhra question
As for your initial question I’m a little bit confused. In my mind this kind of gap can appear when you don’t apply some technics on validation set. Dropout indeed is used only on test set, that definetly was one of the reasons. But you’ve turned it off. Maybe some part of data augmentation plays its role
For expl its used at training phase, making images a but harder to detect. Are you using some kind of image aug? (Im on my mobile now and cannot look at your notebook)
Maybe you could try to use a deeper model, e.g. Resnet50. The current plots indicate that you are underfitting, hence, your model may be not complex enough.
Yes, you’re right about that. Looks like no augmentation is done by default.
I looked at your notebook and noticed that LR_find graph never goes up. This may mean that you can use higher than 5e-2 learning rates. Maybe 100 epoch is really is not enough for this case for this learning rate.
Also if I’m not mistaken you never unfreeze the model, so effectively you use only couple of last layers for training (but since counting squares doesn’t seem to be a hard problem for nn, maybe it has enough layers for the job).
So I’d probably try to use bigger LR (and do another 100 epochs) and try to unfreeze the model (even though it will make learning 100 epochs much longer)
I wonder if the training loss for each epoch is averaged over each mini batch and because your model is getting better from batch to batch, the average is going to be higher than what it would be when loss is calculated at the end of each epoch (what happens with validation loss)?
To test this, perhaps use the same dataset for training and validation?
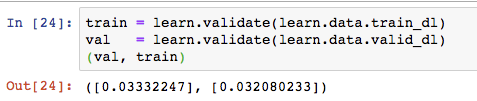
@ptrampert, thank you. I am really interested in the validation loss being below the training loss.
Even if I would use more weights, this shouldn’t change the general picture, or should it? Both training and validation would use the same model complexity, no?
I would think this should not matter over a couple of epochs.
If you look at the numbers above you see that the difference from epoch to epoch within the training loss series or within the validation loss series is tiny. This is especially true, if you compare it to the difference between validation loss and training loss for a given epoch. Agreed?
Anyway, I am feeling my way into this, so I would like to do the test you suggested to get confirmation. What did you have in mind? How would you implement this test?
Let the learner work for 20 epochs and then compare the train_loss of the last epoch with learn.validate(learn.data.train_dl)?
Should I run something like this, but with 20 epochs, not 1?
@Pak, I increased the LR from 5e-2 to 6e-2 and let it train for 100 and then 50 epochs. The training became less stable with the slightly higher LR and I still was not able to lower the training loss under the validation los.
But it is still going down:
Is it possible to pass the exact same dataset to your learner to be employed as both the training and validation data? You won’t be able to use .split_by_pct() method though. Maybe you’ll have to duplicate the training data and then use another method to inform your learner which indices refer to the validation data or something.
About the complexity of a model: For two architectures with different number of parameters, the one that has more parameters also can fit a more complex distribution.
Taking a two-dimensional example, where you want to fit a function through points. If you fit a simple line when given points from a polynomial you are underfitting, that means you have to increase the degree of the polynomial you are fitting (a line can be seen as a polynomial of degree one). In turn that means you are increasing the number of parameters that are used to fit your function.
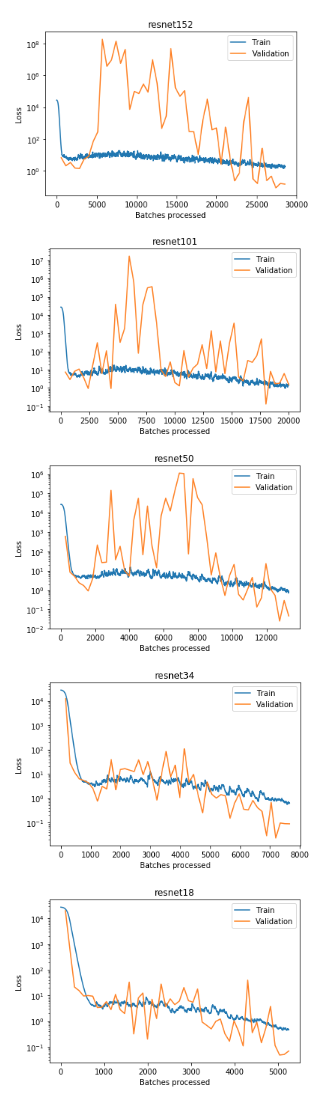
Looking at your new experiments it may be meaningful to even increase complexity a little, take e.g. resnet101. As counterexample you could also try resnet18 and see if it gets worse. Also you can try a different architecture. Even if Resnet is considered a default for many tasks, it may not always be the best.
One further point: Set np.random.seed(42) at the beginning of your notebook. That guarantees that you validation set (random split) is always the same, which makes different experiments easier comparable. Also it prevents accidentally wrong evaluations. Just imagine you train a model and save it. Next time you load the model and run some tests, but due to a different split some part of your former training data now is in the validation set. I think you see the point. Sure, it may not help for robustness tests, but that is not the goal at the moment and a different story, I think.
Furthermore, I would not avoid regularization, as this gives the model more flexibility. For your tests at the moment it may be ok, but for a final model I advise against abandoning regularization. However, getting the flexibility right, so that it is no too flexible, may not be straight forward.
Isn’t that what I did above? There I print out the metric mse, which to my understanding, is calculated with all training data of the epoch (and is the same method as applied to the validation set).
So I see the training loss based on the last batch (train_loss) and the training loss of the training set (mean_squared_error), or am I misinterpreting the results or your question?
Absolutely. Right now I am trying to establish a baseline where the model overfits and then I would try to heal that step by step.
So your suggestion is to increase model complexity to create overfitting? That is a nice way to put it. Unfortunately I fail to really do so.
The details are in this notebook, but below you will find the graphs. What I was looking for is a point where the training loss gets smaller and smaller and the validation loss gets higher and higher. But I do not see such a point.
I did not, however, train the more complex models longer than the others. Not sure if this is an issue, but I would try this next. Maybe just for the most complex model.
 ) is the following:
) is the following: