From the comparison notebook I like the ResNet34 the most. Did I see it correctly, that you always use the same learning rate for all models?
Have you looked into lr_find() for each model individually? From my experience, deeper models need lower learning rates. In general I prefer to converge slower, but more smoothly. The extreme jumping in the loss makes me assume that the learning rate is a problem.
Have you also computed different evaluation measures and how these evolve?
I think that has not to be the case in Deep Learning to find a good model, but at least the validation loss should not be (much) below the training loss. Maybe looking at some evaluation measures, there may be more meaningful trends?
By comparing the graphs it looks like they all behave roughly the same. With a more complex architecture, however, the variance in the validation loss goes up.
I did use the same LR for all, in the hope of making them better comparable.
I have, but honestly lr_find() was hit and miss for me, in both directions. I picked LRs based on the lr_finder that did not progress and LRs where the training loss was jumpy. But maybe I am not reading it right.
I only observed the jumpy graph in the validation loss. My understanding is that the learning rate has no impact here, but the number of samples I use to calculate the loss (higher number of samples would lead to a smoother validation loss graph) and the model complexity (higher complexity would lead to a jumpier validation graph).
But indeed to compare architectures properly, learning rate has to be adapted per architecture, as does the batch size. With respect to the later I let the training run for an epoch, when it does not produce an out of GPU memory error, I increase the bs, until I get an out of GPU memory error and then I backup a bit. It does not feel like the right way. How do other people do that? I also have an eye on nvidia-smi to see how much memory is allocated, but this is not changing the overall process. It just helps to approximate how much the batch size needs to be incremented per step.
Not yet, have you got something specific in mind? For the case at hand, a regression, validation loss based on ( R )MSE sounds perfect to me.
Anyway, thanks for sharing your insights and helping me to get to the bottom of this. I am meanwhile able to produce overfitting and the answer is obvious and has been established a long time ago: More data is a regularization as well.
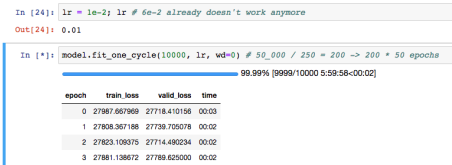
Hence eventually I reduced the number of samples from 50_000 to 250 and now it is overfitting.
Don’t mind the 10_000 epochs. This was a result of making two runs comparable, one with 50_000 samples and 50 epochs and the other one then with a higher number of epochs to normalize the “trainings sightings” in both approaches.
I ran into the same problem where the training loss is always higher than the validation loss no matter what LR I used or epoch I ran (I did it in a loop). Anyone has an answer for this?
Thanks for the quick reply. I am happy to report that I was able to get a pretty good learning rate using the following code where the error rate was low and the training loss was lower than the validate loss.
r = [1e-3,5e-3,7e-3]
for i in r:
print(i)
l3 = cnn_learner(data,models.resnet34,metrics=error_rate) #l3.fit_one_cycle(5,max_lr=i,wd=0)
l3.fit_one_cycle(20,slice(i))
l3.recorder.plot_losses()