Update 3
I’m thinking that it might be my detector code mistake.
So, here is my code for using the trained learner/model to predict images.
import requests
import cv2
bytes = b''
stream = requests.get(url, stream=True)
bytes = bytes + self.stream.raw.read(1024)
a = bytes.find(b'\xff\xd8')
b = bytes.find(b'\xff\xd9')
if a != -1 and b != -1:
jpg = bytes[a:b+2]
bytes = bytes[b+2:]
img = cv2.imdecode(np.fromstring(jpg, dtype=np.uint8), cv2.IMREAD_COLOR)
processedImg = Image(pil2tensor(img, np.float32).div_(255))
predict = learn.predict(processedImg)
self.objectClass = predict[0].obj
and I read imdecode() method return image in B G R order.
Could it because of different channel data used when in training and detecting?
Update 2
Why is there a turn around at the end?? I have highlighten it by the red circle.
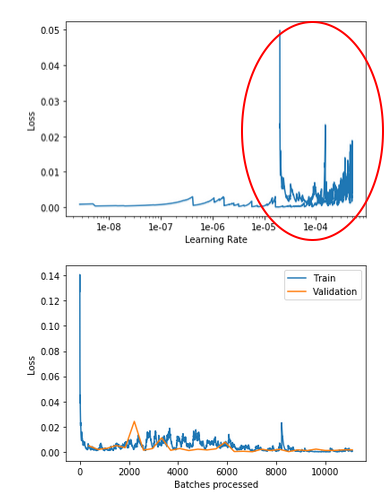
Update 1
After some research, I found that someone suggested to turn off Shuffle?
But that’s for the Keras + Tensorflow.
Do I need to turn off shuffle=False in Fast.Ai?
Hi there,
new to FastAi, ML and Python. I trained my “Birds Or Not-Birds” model. The train_loss, valid_loss and error_rate were improving. If I only trained 3 epochs, then the model worked(meaning it can recognize whether there are birds or no birds in images), then I increased to 30 epochs, all metrics look very good, but the model does not recognize things anymore, whatever images I input, the model always return Not-Birds.
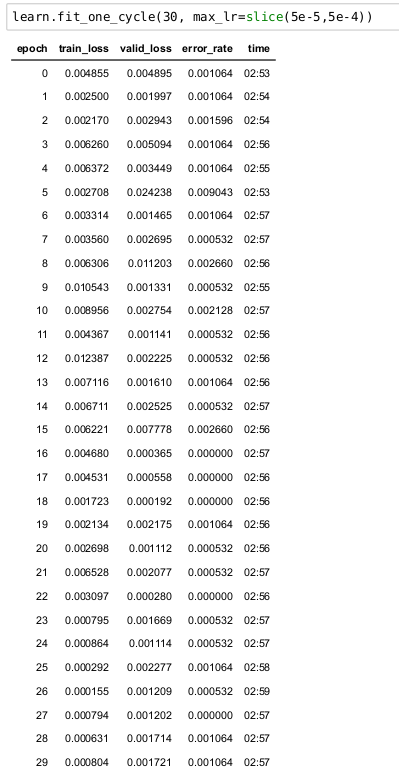
here is the training output:
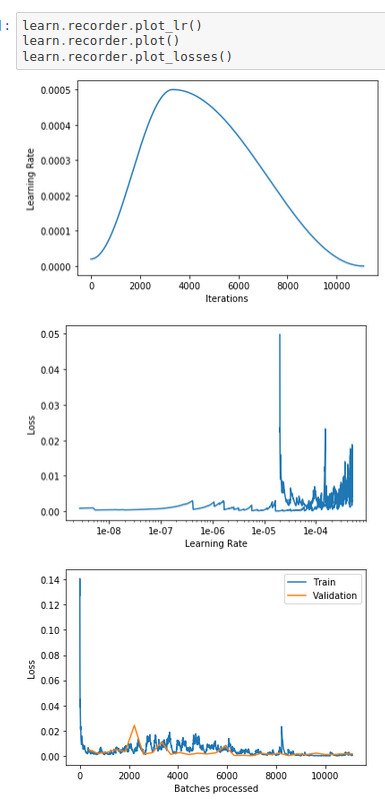
here are the plots of learn.recorder
Here is my code:
from fastai.vision import *
from fastai.metrics import error_rate
from fastai.callbacks import EarlyStoppingCallback,SaveModelCallback
from datetime import datetime as dt
from functools import partial
path_img = '/minidata'
train_folder = 'train'
valid_folder = 'validation'
tunedTransform = partial(get_transforms, max_zoom=1.5)
data = ImageDataBunch.from_folder(path=path_img, train=train_folder, valid=valid_folder, ds_tfms=tunedTransform(),
size=(299, 450), bs=40, classes=['birds', 'others'],
resize_method=ResizeMethod.SQUISH)
data = data.normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.fit_one_cycle(30, max_lr=slice(5e-5,5e-4))
learn.recorder.plot_lr()
learn.recorder.plot()
learn.recorder.plot_losses()
Is it over-fitting? Although the graphs look very good.
Could someone point out where I get wrong?