This makes me nervous, anything on Facebook actually makes me nervous hah. But on that note, be mindful of permissions when getting images from Facebook. You can read here - https://developers.facebook.com/docs/graph-api/reference/photo/#permissions. For example, you can only get user photos if when they authenticate with your app they have granted you said permission.
I found solution on this thread and it worked for me!
Newbie here… just watched lesson 1 and trying to build an image set. I’m using the Google Cloud setting.
Has anyone used rar files on google drive? I found a dataset I’d like to use, which is shared on google drive as a rar file. Here’s the URL:
https://drive.google.com/open?id=1sRHjwTx0akh9L9EAjiKK6OE4sBnwTZJg
I was able to download the file to my laptop but cannot access it from the jupyternotebook on GCP (I guess if I run a web server on my laptop and share this dataset that way, it’ll likely work, but I wonder if there is another way).
From what I heard/read so far, it depends. The example Jeremy gave in the lesson 1 video of baseball vs. cricket has 30 images, IIRC. I guess if there are more categories, you will need more images (so every category has at least several); if the risk of overfitting is higher, e.g. images with the same label have same visual features by accident, perhaps more images will help.
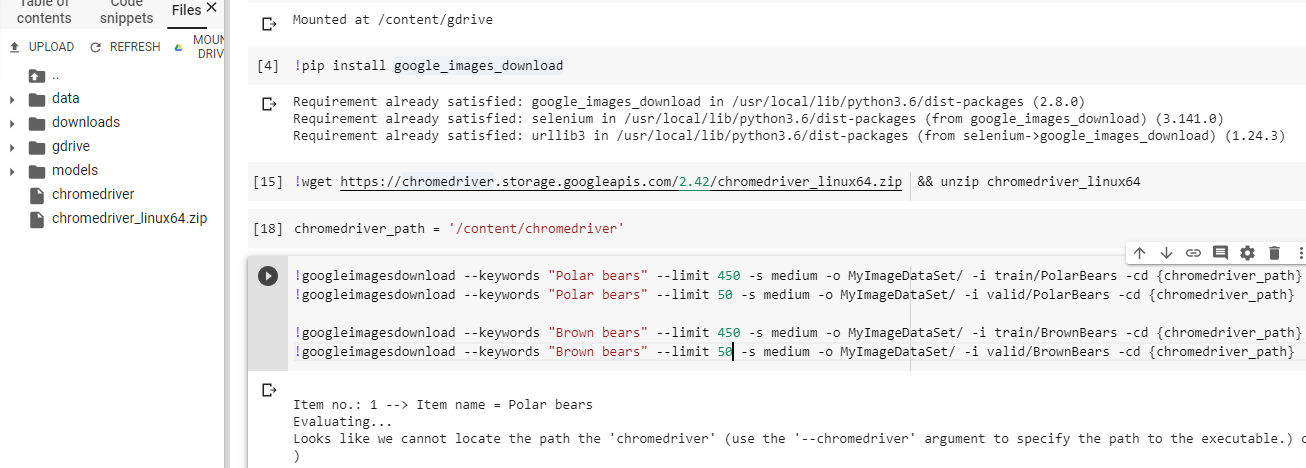
Hi @lindyrock i am not able to download more than 100 images at a time even after i have downloaded the chromedriver. I am using Google Colab as my Jupyter Environment.
I used icrawler and was able to download upto 700images. Attaching colab link.
https://colab.research.google.com/drive/14Zwx9Uh9p8lf-H18sLoaI3s8ByT5jGk6
5 Likes
for what it’s worth - I wrote a tiny helper script to help with gathering image data using google_images_download
Feel free to use and alter, as you’ll see the keywords and time_ranges have been hardcoded to loop over. I’ll be adding more helper scripts to that repository as I go along the 2019 course so feel free to star/watch the repository (or contribute if the inspiration strikes you).
This is designed to run on a linux VM (I run mine on GCP, but I’m sure it should work elsewhere that has chromedriver and has python running in a virtualenv)
2 Likes
Thanks Lindy!
Lindy/All:
Working on p2.xlarge instance on EC2 service by AWS, and stuck on ‘chromedriver’?!
I’ve installed: (a) Google images download ; (b) chromedriver
using your steps (1) and in:
Moving ‘chromedriver’ to /usr/bin/chromedriver
Unfortunately, ‘chromedriver’ path can’t be located:
Item no.: 1 --> Item name = shadow on highway and freeway Evaluating… Looks like we cannot locate the path the ‘chromedriver’ (use the ‘–chromedriver’ argument to specify the path to the executable.) or google chrome browser is not installed on your machine (exception: Message: unknown error: cannot find Chrome binary (Driver info: chromedriver=2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7),platform=Linux 4.4.0-1099-aws x86_64) )
Tried to install google-chrome using:
curl https://intoli.com/install-google-chrome.sh | bash
I get bunch of “command not found” messages, like:
Downloaded google-chrome-stable_current_x86_64.rpm bash: line 70: rpm: command not found Installing the required font dependencies. bash: line 76: yum: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting glibc… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting util-linux… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting libmount… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting libblkid… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting libuuid… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting libselinux… bash: line 107: rpm2cpio: command not found bash: line 100: repoquery: command not found http://: Invalid host name. Extracting pcre… bash: line 107: rpm2cpio: command not found Finding dependency for ldd.sh bash: line 176: repoquery: command not found Finding dependency for ldd.sh
1 Like
I have the same issue on paperspace/gradient 
am.sharan .ipynb using colab:
Continuing the discussion from Tips for building large image datasets:
https://colab.research.google.com/drive/14Zwx9Uh9p8lf-H18sLoaI3s8ByT5jGk6#scrollTo=gaRW9mnxSiUc
worked.
2 Likes
Hi,
I decided to classify mushrooms and found this website, where observers can upload photos of mushrooms along with the species they believe the mushrooms belong to (and maybe more/less specific denominations, e.g. infraspecific name/stirp). The community also contributes by stating their opinions based on the photos.
Well, anyways, the maintainers explicitly ask not to scrape the website but rather drop them an email. I did so and got a reply within 5 minutes or so. 30 min later I got access to 10⁶ mushroom figs. Great people.
2 Likes
Hi,
I’ve been trying to use the duck goose package, but am getting an error while running it -
"
Unfortunately all 100 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!
"
I’m using Gradient/Paperspace.
I ran in the Jupyter terminal -
pip install duckgoos
pip install chromedriver
Any help would be appreciated!
Thanks
Hi Eran,
That sounds like an message from chrome-driver. I don’t know why it occurred though.
Good luck!
Hey everyone. I just watched the 1st lesson, and I tried to make my own image classifier, using the code from lesson 1.
My idea was to classify images of people’s facial expressions (with focus on negative emotions), and for that I tried to scrape Google images using the uppermost method from this thread (google-image-download).
I’m using Colab and I get an error “Unfortunately all 5 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!”
Here’s my code:
https://colab.research.google.com/drive/1ZsWkt1s710JV46P0ao9d_cKW0TYaJSIM#scrollTo=AnARAlJWMYC0
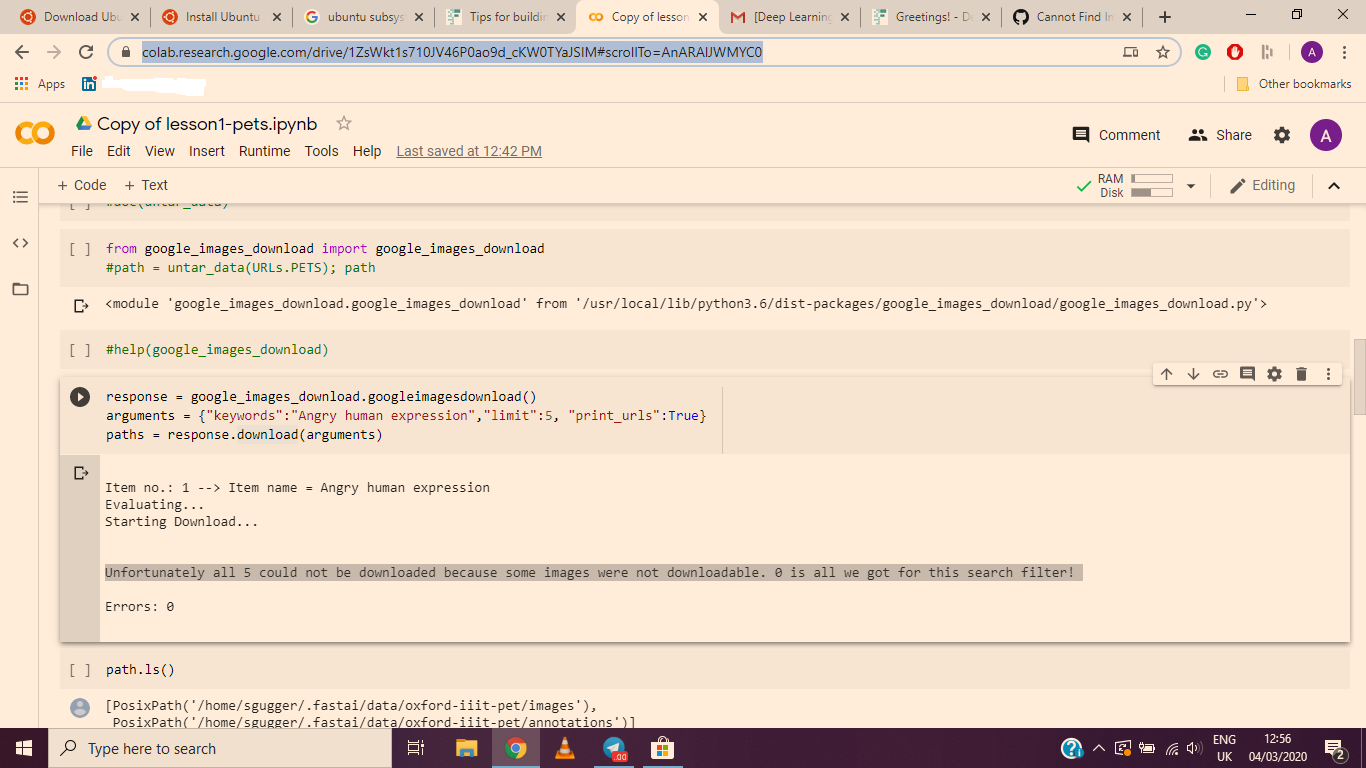
Does anyone have an idea about how to solve the issue?
Tried googling this error and found this thread (https://github.com/hardikvasa/google-images-download/issues/280), where the last few messages are also from frustrated people like me.
The underlying script to pull images from Google is no longer working. There’s a bug report here:
Edit: Removing old link to a script that did not work for me. I ended up using this script which did work for me. If you have any issues with it just let me know.
2 Likes
google_images_download is currently broken
I built a script to do batch download using a Bing Image API account: https://github.com/TedGraham/fastai-ted
It is similar to the PyImageSearch tutorial but my script:
- allows you to specify multiple searches via a text-file
- avoids overwriting existing files
It runs out of the box on Google Cloud instances, you might need to install python3 and PILLOW on some machines.
1 Like
Recent reviews for the add-ons are quite bad.
Following the official tutorial to scrape image using javascript trick here and it worked well.
This fork of google_images_download works, it has not been merged yet but you can use it in place of the pip install google-images-download version:
However:
- I cannot download more than 100 images per search
- I cannot use the -wr parameter for some reason it seems, which forces me to slightly change the keyword for searches which is not great to build a consistent image dataset. I chose to use different colors of a similar objects in order to build it anyway
1 Like
Thanks… this was really useful
can you share your notebook for reference