Hi,
I’ve been trying to use the duck goose package, but am getting an error while running it -
"
Unfortunately all 100 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!
"
I’m using Gradient/Paperspace.
I ran in the Jupyter terminal -
pip install duckgoos
pip install chromedriver
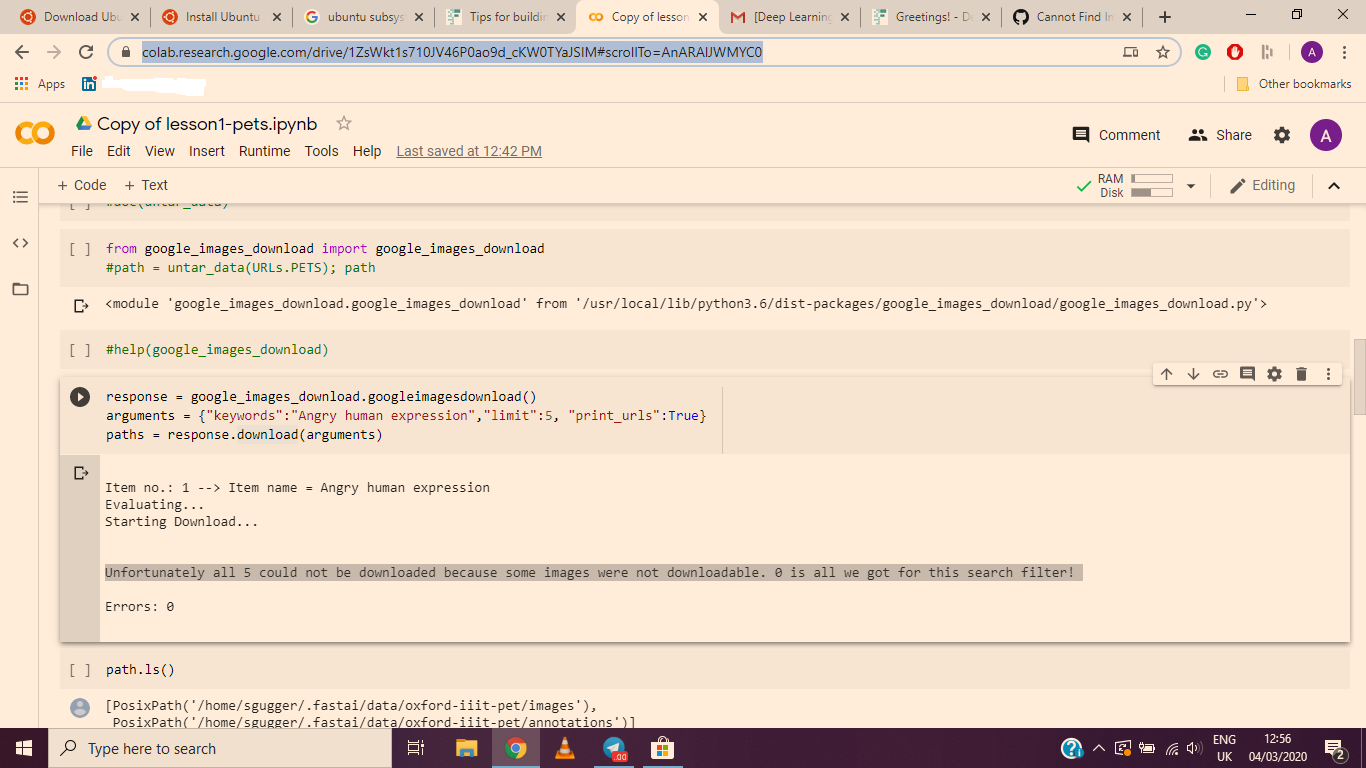
Hey everyone. I just watched the 1st lesson, and I tried to make my own image classifier, using the code from lesson 1.
My idea was to classify images of people’s facial expressions (with focus on negative emotions), and for that I tried to scrape Google images using the uppermost method from this thread (google-image-download).
I’m using Colab and I get an error “Unfortunately all 5 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!”
The underlying script to pull images from Google is no longer working. There’s a bug report here:
Edit: Removing old link to a script that did not work for me. I ended up using this script which did work for me. If you have any issues with it just let me know.
This fork of google_images_download works, it has not been merged yet but you can use it in place of the pip install google-images-download version:
However:
I cannot download more than 100 images per search
I cannot use the -wr parameter for some reason it seems, which forces me to slightly change the keyword for searches which is not great to build a consistent image dataset. I chose to use different colors of a similar objects in order to build it anyway
The first method doesnt work for me. Finally it is finished that “Unfortunately all 50 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!”. Before it, you need to install Selenium and chromedrive (I had some errors between version to solve etc)
Lets start with the positive. The following worked for me. googliser is shell script that worked for me (the only mechanism that I worked for me in colab).
Here are the steps (can be found in the git as well)