Hello Everyone,
I want to train a model using MiniRocket (Pytorch implementation). Am having issue, when I use the SlidingWindow to split the data and introduce time step in the dataset. However, it works when I use the df2xy to split the data. Nevertheless, the SlidingWindow works using others architecture like XCM, TST. Here are the code (I can provide additional information if required:
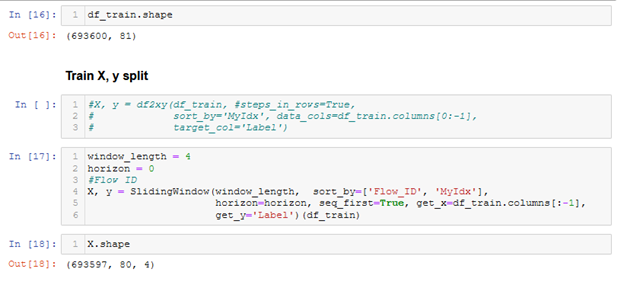
splits = get_splits(new_y, valid_size=.5, balance=True, stratify=True, random_state=23, shuffle=True)
tfms = [None, [TSClassification()]]
batch_tfms = [TSStandardize(by_sample=True)]
dsets = get_ts_dls(X, new_y, tfms=tfms, splits=splits, batch_tfms=batch_tfms, inplace=True)
dls = get_ts_dls(X, new_y, splits=splits, tfms=tfms, batch_tfms=batch_tfms)
model = build_ts_model(MiniRocket, dls=dls)
learn = Learner(dls, model,metrics=metrics, cbs=config["cbs"])
learn.save('stage0')
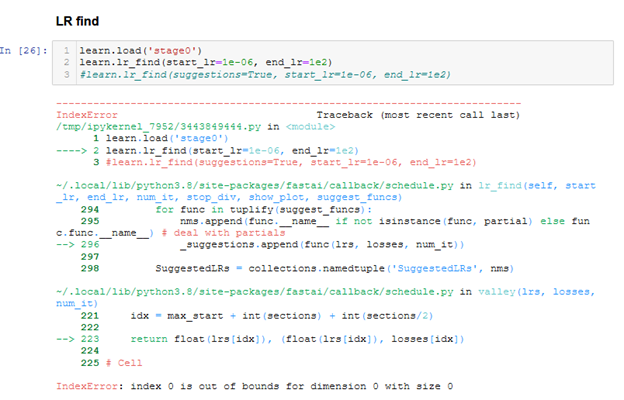
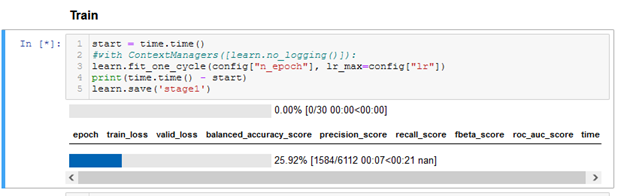
After a while, I get this error:
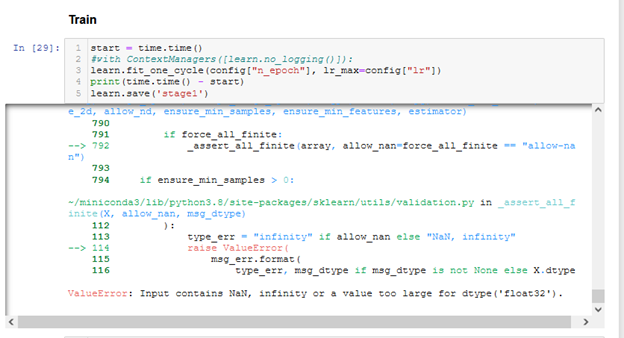
More logs about the error:
epoch train_loss valid_loss balanced_accuracy_score precision_score recall_score fbeta_score roc_auc_score time
100.00% [5419/5419 00:24<00:00 nan]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_7952/3124617560.py in <module>
1 start = time.time()
2 #with ContextManagers([learn.no_logging()]):
----> 3 learn.fit_one_cycle(config["n_epoch"], lr_max=config["lr"])
4 print(time.time() - start)
5 learn.save('stage1')
~/.local/lib/python3.8/site-packages/fastai/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
114 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
115 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 116 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
117
118 # Cell
~/.local/lib/python3.8/site-packages/fastai/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
219 self.opt.set_hypers(lr=self.lr if lr is None else lr)
220 self.n_epoch = n_epoch
--> 221 self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
222
223 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
~/.local/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
161
162 def _with_events(self, f, event_type, ex, final=noop):
--> 163 try: self(f'before_{event_type}'); f()
164 except ex: self(f'after_cancel_{event_type}')
165 self(f'after_{event_type}'); final()
~/.local/lib/python3.8/site-packages/fastai/learner.py in _do_fit(self)
210 for epoch in range(self.n_epoch):
211 self.epoch=epoch
--> 212 self._with_events(self._do_epoch, 'epoch', CancelEpochException)
213
214 def fit(self, n_epoch, lr=None, wd=None, cbs=None, reset_opt=False):
~/.local/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
161
162 def _with_events(self, f, event_type, ex, final=noop):
--> 163 try: self(f'before_{event_type}'); f()
164 except ex: self(f'after_cancel_{event_type}')
165 self(f'after_{event_type}'); final()
~/.local/lib/python3.8/site-packages/fastai/learner.py in _do_epoch(self)
205 def _do_epoch(self):
206 self._do_epoch_train()
--> 207 self._do_epoch_validate()
208
209 def _do_fit(self):
~/.local/lib/python3.8/site-packages/fastai/learner.py in _do_epoch_validate(self, ds_idx, dl)
201 if dl is None: dl = self.dls[ds_idx]
202 self.dl = dl
--> 203 with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)
204
205 def _do_epoch(self):
~/.local/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
163 try: self(f'before_{event_type}'); f()
164 except ex: self(f'after_cancel_{event_type}')
--> 165 self(f'after_{event_type}'); final()
166
167 def all_batches(self):
~/.local/lib/python3.8/site-packages/fastai/learner.py in __call__(self, event_name)
139
140 def ordered_cbs(self, event): return [cb for cb in self.cbs.sorted('order') if hasattr(cb, event)]
--> 141 def __call__(self, event_name): L(event_name).map(self._call_one)
142
143 def _call_one(self, event_name):
~/miniconda3/lib/python3.8/site-packages/fastcore/foundation.py in map(self, f, gen, *args, **kwargs)
152 def range(cls, a, b=None, step=None): return cls(range_of(a, b=b, step=step))
153
--> 154 def map(self, f, *args, gen=False, **kwargs): return self._new(map_ex(self, f, *args, gen=gen, **kwargs))
155 def argwhere(self, f, negate=False, **kwargs): return self._new(argwhere(self, f, negate, **kwargs))
156 def argfirst(self, f, negate=False): return first(i for i,o in self.enumerate() if f(o))
~/miniconda3/lib/python3.8/site-packages/fastcore/basics.py in map_ex(iterable, f, gen, *args, **kwargs)
664 res = map(g, iterable)
665 if gen: return res
--> 666 return list(res)
667
668 # Cell
~/miniconda3/lib/python3.8/site-packages/fastcore/basics.py in __call__(self, *args, **kwargs)
649 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
650 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 651 return self.func(*fargs, **kwargs)
652
653 # Cell
~/.local/lib/python3.8/site-packages/fastai/learner.py in _call_one(self, event_name)
143 def _call_one(self, event_name):
144 if not hasattr(event, event_name): raise Exception(f'missing {event_name}')
--> 145 for cb in self.cbs.sorted('order'): cb(event_name)
146
147 def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)
~/.local/lib/python3.8/site-packages/fastai/callback/core.py in __call__(self, event_name)
43 (self.run_valid and not getattr(self, 'training', False)))
44 res = None
---> 45 if self.run and _run: res = getattr(self, event_name, noop)()
46 if event_name=='after_fit': self.run=True #Reset self.run to True at each end of fit
47 return res
~/.local/lib/python3.8/site-packages/fastai/learner.py in after_validate(self)
517 def before_validate(self): self._valid_mets.map(Self.reset())
518 def after_train (self): self.log += self._train_mets.map(_maybe_item)
--> 519 def after_validate(self): self.log += self._valid_mets.map(_maybe_item)
520 def after_cancel_train(self): self.cancel_train = True
521 def after_cancel_validate(self): self.cancel_valid = True
~/miniconda3/lib/python3.8/site-packages/fastcore/foundation.py in map(self, f, gen, *args, **kwargs)
152 def range(cls, a, b=None, step=None): return cls(range_of(a, b=b, step=step))
153
--> 154 def map(self, f, *args, gen=False, **kwargs): return self._new(map_ex(self, f, *args, gen=gen, **kwargs))
155 def argwhere(self, f, negate=False, **kwargs): return self._new(argwhere(self, f, negate, **kwargs))
156 def argfirst(self, f, negate=False): return first(i for i,o in self.enumerate() if f(o))
~/miniconda3/lib/python3.8/site-packages/fastcore/basics.py in map_ex(iterable, f, gen, *args, **kwargs)
664 res = map(g, iterable)
665 if gen: return res
--> 666 return list(res)
667
668 # Cell
~/miniconda3/lib/python3.8/site-packages/fastcore/basics.py in __call__(self, *args, **kwargs)
649 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
650 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 651 return self.func(*fargs, **kwargs)
652
653 # Cell
~/.local/lib/python3.8/site-packages/fastai/learner.py in _maybe_item(t)
471 # Cell
472 def _maybe_item(t):
--> 473 t = t.value
474 try: return t.item()
475 except: return t
~/.local/lib/python3.8/site-packages/fastai/metrics.py in value(self)
65 preds,targs = torch.cat(self.preds),torch.cat(self.targs)
66 if self.to_np: preds,targs = preds.numpy(),targs.numpy()
---> 67 return self.func(targs, preds, **self.kwargs) if self.invert_args else self.func(preds, targs, **self.kwargs)
68
69 @property
~/miniconda3/lib/python3.8/site-packages/sklearn/metrics/_ranking.py in roc_auc_score(y_true, y_score, average, sample_weight, max_fpr, multi_class, labels)
544 y_type = type_of_target(y_true)
545 y_true = check_array(y_true, ensure_2d=False, dtype=None)
--> 546 y_score = check_array(y_score, ensure_2d=False)
547
548 if y_type == "multiclass" or (
~/miniconda3/lib/python3.8/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
790
791 if force_all_finite:
--> 792 _assert_all_finite(array, allow_nan=force_all_finite == "allow-nan")
793
794 if ensure_min_samples > 0:
~/miniconda3/lib/python3.8/site-packages/sklearn/utils/validation.py in _assert_all_finite(X, allow_nan, msg_dtype)
112 ):
113 type_err = "infinity" if allow_nan else "NaN, infinity"
--> 114 raise ValueError(
115 msg_err.format(
116 type_err, msg_dtype if msg_dtype is not None else X.dtype
ValueError: Input contains NaN, infinity or a value too large for dtype('float32').
 in GitHub this week!
in GitHub this week!
