@oguiza@muellerzr@vrodriguezf
Hi everyone, many thanks for this fantastic library, that has helped me a lot on my studies on time series.
I am facing a challenge and would like to see if there is an interesting solution using tsai.
I have a small dataset, containing different sizes wîdows of data for four different activitiies. The dataset is invalanced, class A has only four chunks, class B has 5, class C has 30 chubks and class D has 35.
I need to balance the data and also to generate a lot of other chunks or surrogateS data. In order to apply gmaf and then use Deep learning.
Does the Tsai, library has some ways of doing this?
Thanks for your feedback @el3oss! I’m really glad tsai has helped you with your time series tasks.
As to the dataset you mention, I’m not sure I understand your challenge. We might be able to help if you provide a more visual example or maybe a gist. I’m not share what you mean by chunks and the different sizes of windows. Do you mean instances or samples of each class?
Also, what do you mean by gmaf?
Hi @oguiza,
many thanks for your feedback.
By chunks I mean windows of data from triaxial accelerometer (X,Y,Z), which corresponds to a data acquisition during a certain time.
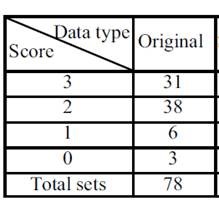
There are different participants performing a specific rehabilitation activity consisting of gripping an object and putting it somewhere else (a total of 78 trials), and each of this trial is labeled with a performance score that can be: 0, 1, 2, 3 depending on the performance
you can see an example of a chunk for the x-axis of an accelerometer for one trial below:
This particular activity lasted for 2 seconds but the length differ from trial to another, I will pad all of them with zeros so they have the same length later on.
The issue is that the data is very small as you can see on the table below:
so as you can see:
Dataset is unbalanced
The number of chunk/class is very small.
Since I cannot do new acquisition, I thought about creating some artificial data in order: (1) to balance the classes and (2) to augment the dataset size maybe 100 times or more, so that I can encode the different windows to images and classify them using some DL algorithm.
I think there is something broken in the imaging formats. For the tutorial in the Univariate time series explanation, they all come out wonky, and even on my personal data as well
What you found is normal. The issue is that some of tsai’s dependencies have conflicts. That’s ok because we are not using any of those conflicting libraries. That’s something I regularly monitor.
To ensure tsai works properly, you only need to restart the notebook. That’s the recommended approach when you install new libraries.
So in summary you can ignore those import ERRORs.
BTW, you can hide him if you put %%capture at the top of the cell where the imports occur. But you still need to restart the kernel every time you install them.
While I have your ears, I am working primarily in image classification, NLP, and collaborative filtering projects for my company. However, the current project is on “time series regression,” i.e., what would be the following number in the sequence?
I am fluent in Python and Fast.ai, so when I found your “tsai” (last week), I dived head-in. Thank you so much for this forum. My style is read (a little bit), code, and more code, and read again. I go through most of your Jupyter notebooks on GitHub, and when I come across the “Intro_to_Time_Series_Regression.ipynb” using Monash data, especially for datasets with one dimension. I thought I found what I needed, but I have a question.
For the model, you are using “InceptionTime,” and tsai has all models from “FCN to Rocket,” but where is the LSTM model? What are your thoughts on using LSTM?
LSTM is on e of the models in tsai. It’s in tsai.models.RNN.LSTM.
There’s no way to know apriori which model will work better on a given task. It’s always good to test several options up front. You may be surprise with the differences.
In my experience though, LSTM tend to underperform MiniRocket, CNNs or Transformers. But other may disagree.
I’ve put together a gist to show how you can quickly test several models on a regression task using tsai, including LSTM.
@oguiza, thank you for the generosity of your time.
The more I learn about time series regression, the more that perplexes me. I am good with math, so the algorithms are relatively easy to understand. I will also try out many time series algorithms/models and see what works best for my [client] project.
Maybe I am too new to the time series, but I will post the question.
There are user-id, item-id, and rating in collab filtering, and I regularly add embeddings to help it converged to a lower loss rate. For example, I use 34 dimensions embedding in the book store projects because they classified their book using 34 categories. It works wonders.
Can time series, where the data set is univariable, use embeddings for a better outcome?
BTW, your “gist” above links to an empty notebook.
I have the model train reasonably well using the “Inception Time.” I did try using a handful of other algorithms, but the question is, “how do you predict the next number at the end of the sequence?”
I did look/search through this channel but didn’t find the answer. There are discussions on predicting using the “test” set, but not the “next number (for univariable or set of number for multivariable) beyond the end of the sequence.”
Hi @duchaba,
Sorry for my late response. I’ll try to reply to your questions.
I’ve updated the link. Please, let me know if it doesn’t work.
Yes, you can always create categorical embeddings and concatenate them to a univariate/ multivariate time series. Categorical embeddings may improve your performance if the information they use is relevant for your task. I’m my experience they tend to work better than one-hot encoding.
This is a key concept to understand in deep learning. Deep learning uses neural networks that are trained to map an input (X) to a target (aka label, y), making sure that the output it generates is as close as possible to the target:
net(input) = output
loss(output, target) <== minimize this
The model doesn’t understand where the input or the target comes from. It just knows if need to create something similar to it. The way in which we translate those questions to the neural net is by using the appropriate targets. A different question needs different targets.
In your case, if your question is “which is the next number?”, you pass the next number as a target. If your question was “what are the next 3 numbers?”, you pass the next 3 numbers. You could even ask “what was the previous number?”, or “is this trend increasing or declining?”, or “is this customer going to buy this product?”. Anything you can think of. The key is to have the right labels for your task.
I hope this is clearer now.
“x” is the last sliding window, which gives you the last known “y” value. I am testing both univariable and multivariable data set. Furthermore, I shifted the sliding windows to include the last/unuse x-row, which would give the “next predict value (y-hat).”
However, using the above three lines of code, it can only predict “one” time. The next time the data-loaders are messed up. I can’t use it the second time, and I have to re-create the “loaders and the learn.”
Any help finding a new/different method to perform the “predict” will be greatly appreciated.
It’s difficult to answer. It depends on the modules already installed in your environment before you install tsai. In Google Colab for example, you need to restart the runtime. In Kaggle notebooks you don’t. You need to restart the runtime whenever the modules installed by tsai clash with others previously available.
The simplest way to get predictions in tsai is this:
probas, target, preds = learn.get_X_preds(X, y)
X and y may contain multiple samples. I don’t understand this:
However, using the above three lines of code, it can only predict “one” time. The next time the data-loaders are messed up. I can’t use it the second time, and I have to re-create the “loaders and the learn.”
Could you please explain why you can only predict “one” time?
During the last couple of months, Kaggle’s hosted a time series competition. It finished a few days ago.
I have reviewed the top 15 solutions (all gold winners) and have found some great ideas.
If you are interested in learning more you can read the Medium blog post I’ve created: