At least for me, it looks like smaller batch sizes are simply training way longer and do not result in any better results.
What do you mean with adjust the learning rate?
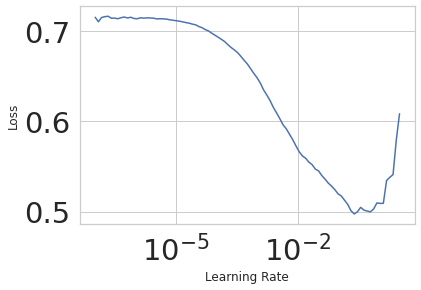
I currently use d1e-4 but with the learning rate finder, I would guess that 1e-2 is much better. Is this assumption correct? However, the results are noticeably worse with the increased learning rate.
The: learn.recorder.plot(suggestion=True) fails for me as mWDN does not seem to have the attribute plot.
Then go with a large batch size. Performance is what should drive your decisions.
Sorry if I wasn’t clear. What I mean if that if you use a different batch size, you should run learn.lr_find() first to decide which lr to use. Usually, larger batch sizes require a larger lr.
There’s no connection between the learning rate finder plot and the model you use AFAIK.
I don’t get suggestions either. There might be a bug in fastai.
With the lr find plot you’ve shared, I’d probably go with a lr 1e-3 or 3e-3.
And many thanks for your hardwork.
I have just a parallel quick question related to what you have been doing and would like to have an assistance from your great expertise!
I have a numpy array containing time series data on which I will use pyts library to encode the different samples into images, similarly to what you have been doing in your great library.
The thing is I will not use fastai but another framework for classification, so I cannot use tsai.
My problem is when I try to encode the array into images, it makes my ram crash I think due to the big size of images, and large nulber of samples I do not want to change the image size but would like to find another way to deal with this. How did you do it, please? Can you give me ideas on how to fix it.
@oguiza are we planning to have discord server for tsai anytime in the future? Was thinking that chats can be more organized if we could put them under various channels in discord
Well I am not using fastai library.
I just have an array containing segmented data, and then when applying for example the markov or the gramian angular fields algorithm from PYTS library it is making the ram crash because the resulting images are huge.
While when using yout library it doesn’t! So I just want to know what eas your trick! Are you doing batch processing? If so how dis you do it. My code is simillar to the one bellow
Gmaf = mkv_transformation(array)
Where array shape is a 19000 x 100X 3 .
I should finally have 19000 images of size (224x224)
Hi @el3oss,
I’m not sure what makes your system crash. But these image-like objects (they are not proper images, as they have a channel per variable) are pretty big, so you won’t be able to store many in memory. tsai creates these representation online, when the batch is created. The process is slow though, especially if you have a large dataset. So I try to always use the raw data instead of this expensive transforms. Having said that, if you still want to apply any ts to image transform, you have 2 options:
perform the transform online (per batch). This will slow down the process as you will need to create the images. It has the benefit that you may be able to apply data augmentation. You will need to manage the batch sie to ensure you don’t get an OOM error.
preprocess all data and save the output to disk (numpy array for example). Then you’ll need to create batches from the data on disk. (This is not implemented in tsai).
Dear oguiza,
Many thanks for your answer.
Yeah I want to write a paper on different encoding techniques and see if it improves activity recognition.
As you said I tried the tsai approach but it was very slow, I also followed your advice to save them the images in an array and then use memmap from numpy and classify them.
Just one question, once I have the images on my disk, can I load them by batches and do my classification in order to avoid my ram to crash again? If so, using memmap from numpy as you kindly explained in your notbook, woukd work?
Hi guys
I have hit a brick wall and need your help.
My model is only ever using the last value it encounters to make predictions.
I tested this by only giving it the minimum 9 data points required by MiniRocket. These 9 points usually only contain 1 value due to high frequency sampling.
This gave the best accuracy, which turns out to exactly match the random movement of the time series (i.e. no predictive ability beyond randomly guessing).
When I add more prior data, all relevant, the accuracy only goes down. In other words, the more i ask the model to use data other than the last encountered value, the worse it gets.
I can’t understand what’s going wrong. Just relying on the last value is useless as I need to predict movements in the data.
Hi @shado,
I’m afraid it’s impossible to help you with the information you have provided. Is there any code you can share to further explain what you issue is?
I’m not how many steps ahead get_y is giving me. It looks like only the first value of the next window, but I need at least one step ahead (20 values) otherwise it’s not predicting t+1 just t0.
E.g. say these are two of my windows:
w1 = aaaaaaaaaaaaabbbbbbb
w2 = bbbbbbbcccccccccccccc
then for my first y prediction it will give me b since that is the last value it saw.
Whereas I need it to give me c, since that is the next value that is actually useful to me.
There are 2 parameters in SlidingWindow that may be useful to you:
horizon = number of future datapoints to predict:
* 0 for last step in each sub-window.
* n > 0 for a range of n future steps (1 to n).
* n < 0 for a range of n past steps (-n + 1 to 0).
* list : for those exact timesteps.
In your case, it seems the horizon should be set to 20.
y_func = function to calculate the ys based on the get_y col/s and each y sub-window. y_func must be a function applied to axis=1!
A simple example of y_func would be this where the mode is calculated along axis=1 (in your case the 20 values):
@oguiza do you know the impact of weight initialization for TSAI? I have the feeling that for my data it greatly changes the outcome by simply restarting the script (dataset splits are the same so I guess it must be weight initialization). Are there some suggestions or best practices?
Hi everyone! @KevinB and I are playing with Informer for time series forecasting. Both of us are relatively new to the time series stuff.
Many of the results presented in paper are obtained on their own datasets and comparison is done with popular models trained by authors of the paper. It would be nice to compare the results of Informer on some well established benchmark. It would be of great help if someone experienced with the topic could suggest a dataset and reasonable baseline models for forecasting with horizon of 20-100 time steps or direct us in a direction to search.
Thanks!
@geoHeil at one point I struggle to produce consistent result over multiple runs and I decided to seed all my runs:
def random_seed(seed_value, use_cuda):
np.random.seed(seed_value) # cpu vars
torch.manual_seed(seed_value) # cpu vars
random.seed(seed_value) # Python
if use_cuda:
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # gpu vars
torch.backends.cudnn.deterministic = True #needed
torch.backends.cudnn.benchmark = False
random_seed(77, True)
Not sure if is the best way though. But I get the exact numbers in training and results for every run. Seeding allows me to do other hyperparameter tuning without concerns about the results improvements coming from all the random factors.