@oguiza First of all, thank you for your valuable contributions!
I am looking for some guidance on a time series classification project.
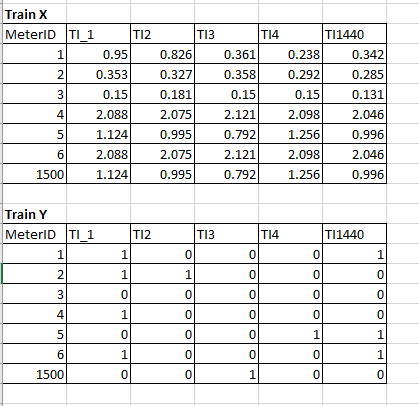
I have a dataset with 1500 sample meters, 1 feature and 1440 time intervals of data. The twist is that I am also given target variable for each of the time intervals.
So it is not the typical y shape of (1500, ). I need to do target prediction for each time interval in the test set as well. I could not find a way to prepare my data using df2xy mentioned in tsai. What is the best way to approach this problem?
This is what the data looks like, if it helps for visualization:
I’m not sure what to share since the data itself can be created in so many ways. E.g. I can either predict price movement up or down (categorical) or target price in the future. I can also use up to 14000 variables or as little as 1, but I’ve tried 1 to 8 variables and it’s the same result- 50/50. My problem is broad- like, could it be that the way I have upsampled the data is the problem? Or do I need to include more variables, like maybe 50 to 100? Or do I need to use sliding windows? Or do all my predictions need to be the same number of steps in the future or can they vary by sample? Or should I persist with image classification or tabular versions instead? Or… there’s like a million questions and different thing I can change but what I am asking is how can I figure out for myself what I need to learn/change/do different. All the discussions here are so high level and beyond my current understanding that the leap from where I am to where you guys are seems like walking on the moon.
@oguiza also, thanks for being patient, even though I was rude.
I just thought of something looking at your regression notebook. Would there likely be a material difference in accuracy if one model was set to predict a 50/50 increase/decrease in stock price (categorisation) vs predicting stock price (regression)? Using the exact same set of data and all else otherwise the same? In other words, are some problems likely to be more accurate as a regression problem vs a categorisation problem. My initial intuition is that categorisation would be easier but as I think about it maybe regression helps the algorithm learn quicker?
Updates:
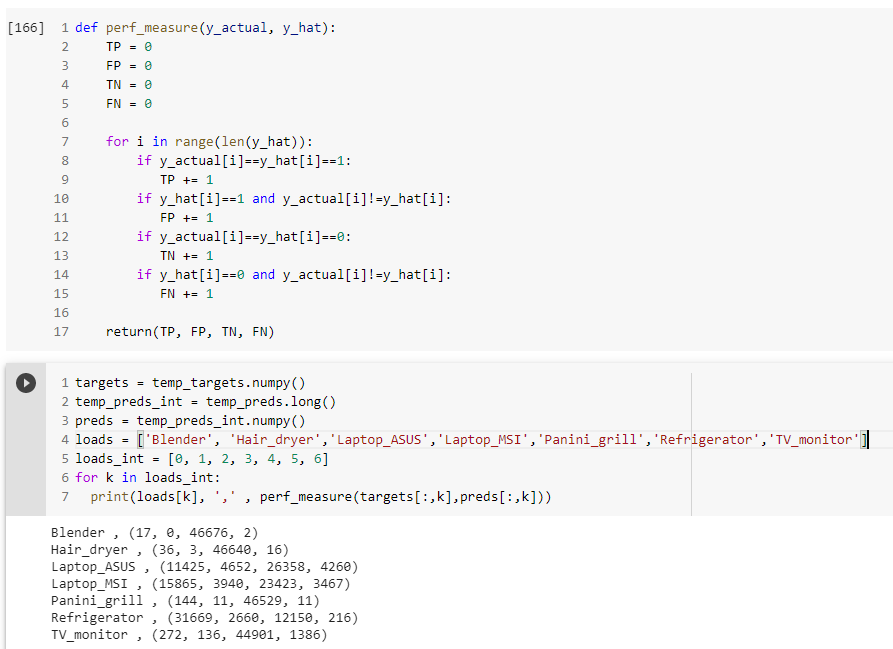
I was able to map the integers to their corresponding labels by manually investigating the test instances of the origianl test set … Then, I computed metrics for each label:
Hi everyone,
This looks like an interesting group. I am needing time series forecasting, hoping deep learning can work.
This might be a stupid question, but when you talk about number of samples, does this mean one long time series split into multiple parts, similar to a sliding window?
What if I have multiple datasets from different sources. Can the samples be of different sources and not split up? I.e. use the whole sample and have many different samples?
Hi @remapears. I’ve created an updated version of the 01a_MultiClass_MultiLabel_TSClassification.ipynb tutorial notebook to help answer your questions. Examples of label mapping are shown in cells 16-25 for multi-class and cells 44-51 for multi-label.
The updated tutorial is currently available as a gist at either:
Hi @remapears. Glad the updated tutorial was of value. Sorry for any confusion around L() – it’s an enhanced list class defined in fastcore and is included via the statement from tsai.all import * in cell 2.
Hi. If I have 1000 different cake stalls that each run for only 3 weeks, is it better to train a new model for every single stall, or is can I train a model that generalises for all stalls?
Training a new model for every stall sounds like a big task, considering you have 1000 stalls! Probably train one model that ingests the time series data from all the stalls? You will then have 1000 sequences (one for each stall) each with input and label (x,y) pairs.
Has someone tried this new loss on torch 1.8: torch.nn.` `GaussianNLLLoss
It looks cool for probabilistic forecasting. Maybe we can do something like here
Hi @geoHeil,
I don’t think you can say a priori that’s a too large batch size. It all depends on your dataset and task. I normally use large batch sizes (especially with large datasets) and then adjust the rest of parameters (like lr, regularization, etc). But it’s always a good idea if you have the time to test different batch sizes to see if there’s any performance degradation. If your dataset is too large, you can always use a fraction of the training set to test the impact of batch size.
I normally follow the rule of using the largest possible for the GPU I am using…there’s also the bs finder that OpenAI proposed, which is implemented here for fastai, but I’ve never tried it.
There’s something else I forgot to mention when benchmarking different batch sizes. You will need to adjust learning rate accordingly. Usually larger batch sizes require larger lrs. So if you adjust the batch size, it’s always a good idea to run lr_find.