I’ve completed 3-4 runs of InceptionTime baseline after fixing the cone layer bias (thanks to @tcapelle for pointing that out). The results of 500 epochs are now better, and almost the same as the one @hfawaz has with the TensorFlow version with 1500 epochs. So I think it’s a good start. Here are the results:
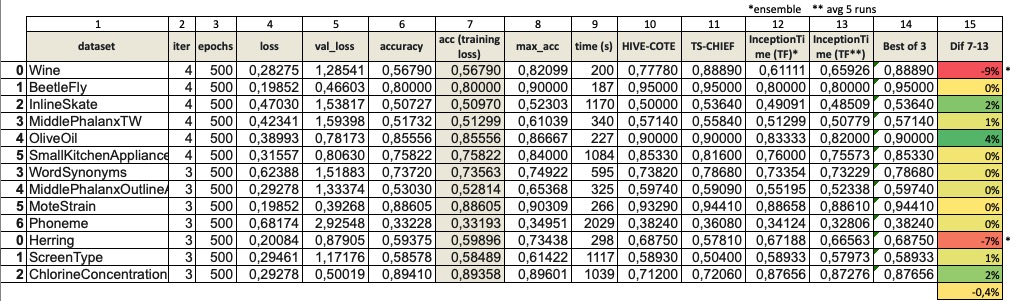
You’ll notice that the average performance is very close in 11 datasets, but there are 2 where it’s actually lower (Wine: -9%, and Herring: -7% accuracy compared to the avg of 5 TF InceptionTime runs).
I’ve digged a bit more to try to understand why, and have run Wine for 1500 epochs (with and without mixup). There’s a huge jump in performance (+23% without mixup, and +27% with mixup):
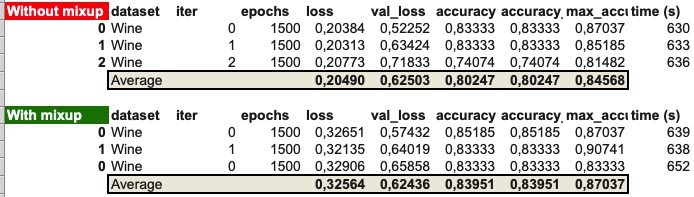
All these performance results use the same architecture as the original in TensorFlow. I have not made any single change yet. Any difference would mainly come from the training process/ optimizer.
So a few comments:
- some datasets benefit from a much larger number of epochs (Wine).
- mixup increases performance even after a long run. In the case of Wine an average of 3.7%. Actually, with a longer training and mixup, Wine goes from being the bottom performer, to being relatively close to the state-of-the-art.
- accuracy at the end of training tends to be the same or slightly better that the accuracy at the lowest training loss. This seems to indicate that there is little / no overfit even after 1500 epochs.