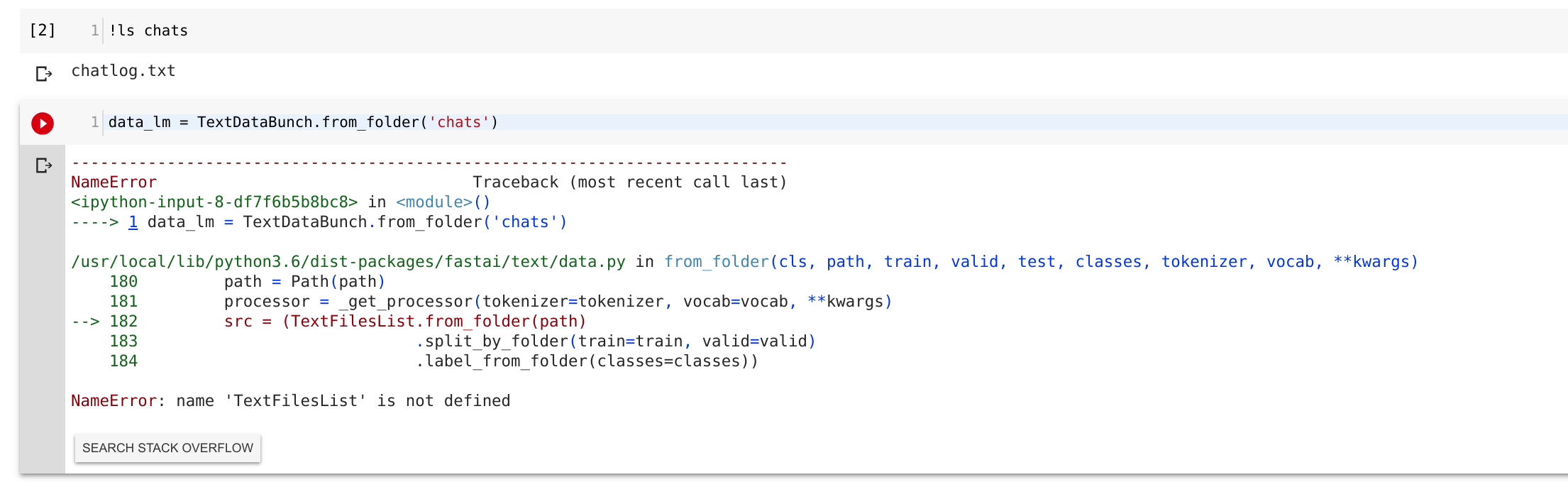
I am trying to make my own little next-word-guesser. I have all my data cleaned and in a file called chatlog.txt
After being unable to decipher how to use TextDataBunch, I tried to use the from_folder option with only one file in the folder.
I then get the following error:
NameError Traceback (most recent call last)
<ipython-input-8-df7f6b5b8bc8> in <module>()
----> 1 data_lm = TextDataBunch.from_folder('chats')
/usr/local/lib/python3.6/dist-packages/fastai/text/data.py in from_folder(cls, path, train, valid, test, classes, tokenizer, vocab, **kwargs)
180 path = Path(path)
181 processor = _get_processor(tokenizer=tokenizer, vocab=vocab, **kwargs)
--> 182 src = (TextFilesList.from_folder(path)
183 .split_by_folder(train=train, valid=valid)
184 .label_from_folder(classes=classes))
NameError: name 'TextFilesList' is not defined
This is runing on google colab:
=== Software ===
python version : 3.6.6
fastai version : 1.0.27
torch version : 1.0.0.dev20181116
nvidia driver : 396.44
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 11441MB | Tesla K80
=== Environment ===
platform : Linux-4.14.65+-x86_64-with-Ubuntu-18.04-bionic
distro : #1 SMP Sun Sep 9 02:18:33 PDT 2018
conda env : Unknown
python : /usr/bin/python3
sys.path :
/env/python
/usr/lib/python36.zip
/usr/lib/python3.6
/usr/lib/python3.6/lib-dynload
/usr/local/lib/python3.6/dist-packages
/usr/lib/python3/dist-packages
/usr/local/lib/python3.6/dist-packages/IPython/extensions
Sun Nov 18 16:22:58 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.44 Driver Version: 396.44 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P8 27W / 149W | 11MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+

 Now it works right locally for me in my notebook.
Now it works right locally for me in my notebook.