Here, is what I am getting. I tried this with IMDB data too, same results
2 Likes
Hey,
I believe that when working with a dataframe, fastai creates and uses a “Text” column internally. Could you try renaming the column on your dataframe to something else and pass it on with the new name and see if that fixes the problem?
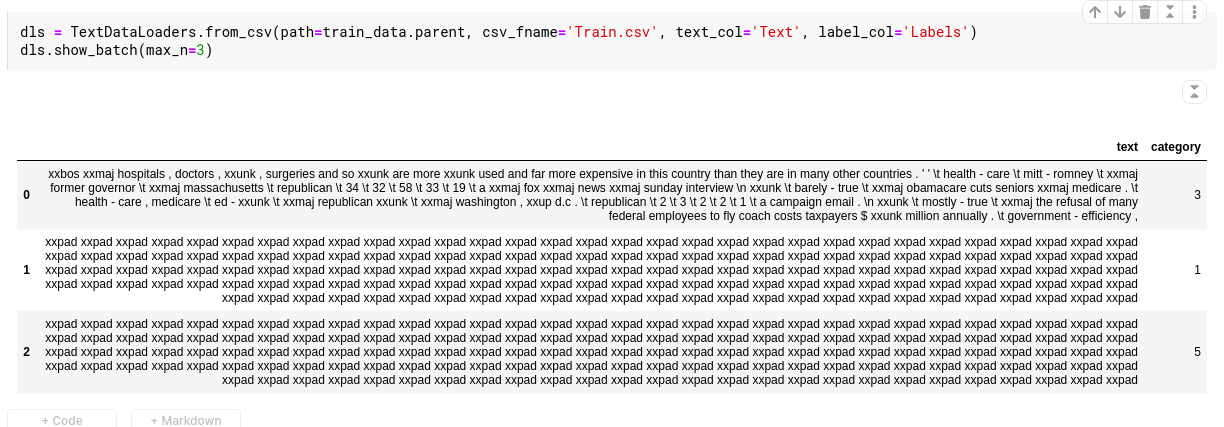
The behavior is the same in the 38_turorial.text.ipynb notebook. There is an issue with dls.show_batch() and learn.show_results(). The first row in the batch is decoded correctly and the following rows are all xxpad values.
1 Like
HI NavneetSajwan hope your having a wonderful day!
Some of the posts in this thread may help with your question.
Cheers mrfabulous1 ![]()
![]()
1 Like
Tried it. Doesn’t seem to work.
Thanks for your responses @orendar @mrfabulous1 @markphillips. I am new to NLP and I think I might have to dig deeper into Fastai text data loaders to find the solution.
It seems like a bug. I looked for a bit but didn’t track it down to the source. I will continue looking tomorrow.
@NavneetSajwan @KevinB, if I understand Jeremy’s response to my post, I don’t think it’s a bug, I think it is expected (albeit confusing) behaviour.
There is one review in the IMDB dataset which is much longer than the rest of the reviews.
Fastai chops up variable-length token sequences (i.e. movie reviews) into fixed size mini-batches, with bs other reviews, where other reviews are different rows of the tensor. The resulting mini-batches must be sufficiently small to fit into GPU memory, but also need to retain continuity in the sequence of tokens between consecutive mini-batches, so that the text flows between mini-batches. In order for all the mini-batches to have the same dimensions, fastai uses the special xpad token (i.e. padding, like in computer vision where black pixels can be used to make all the images square).
If there is one review which is much longer than the rest, the rest of the reviews in the same mini-batch will be mostly padding. Therefore what you are seeing is expected behaviour. My guess is that show_batch() returns movie reviews in order of decreasing length, which is why you’re seeing this at all.
I think there are a few ways you can verify the story above. One way might be to iterate through mini-batches until you get to e.g. the 10,000th mini-batch, and then take a look at that batch to see that you’re seeing words again, not just padding. Alternatively, you could exclude the very long movie review before building your dls.
2 Likes
I’ve been struggling with this as well, but there seems to be an easy way to see the full sample. You can increase the trunc_at=150:
For your dataloaders:
dls.show_batch(max_n=10, trunc_at=500)
For your plot_top_losses to see where your models makes the biggest mistakes:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(10, trunc_at=500)
You might need to increase above 500 as well of course, just have a look at the printed result to see if you can read enough data.
3 Likes