When I generate a DataBlock for classification for sentiment analysis of the IMDB dataset, I find that my first few batches are almost entirely padding (xpad). But when I train a classifier, I still get an ok accuracy (0.86 after one round of fit_one_cycle)
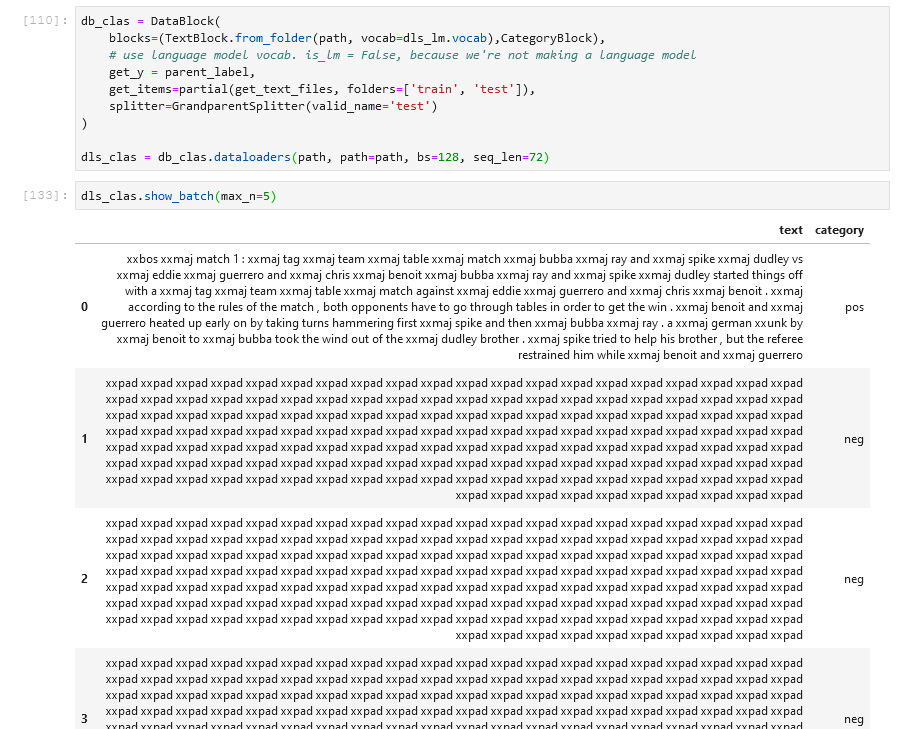
I’ve looked at as many as 50 batches with show_batch, and all but the first batch are entirely padding. Has anyone encountered this? Does anyone have any thoughts on how I can best investigate this further?