Is there a way to extend the tabular model with costume NLP text features.
Suppose we have a data frame of real estate characteristics “tabular characteristics” -e.g. square meters, age, condition, price …, and a detailed text description of the estate. Example of such dataset can be found HERE (I have created this dataset, Czech language of description)
I would like to have one deep learning model that would use tabular features as well as text features.
One workaround would be to train the separated ulmfit model on estate descriptions and use a model encoder.
Where this model would take use a pre-trained model and convert text columns into a vector. This may then be used to train the separated tabular models with only tabular features.
However, I want to use text features directly in one model and not this workaround. Is there any way to extend tabular learner with nlp components within the fastai ecosystem?
Definitely watching this thread because this is exactly the use case I would like to apply as well. I was thinking that I might have to do it in two steps, train an NLP model on the text only to generate predictions and then combine these with the tabular features. I have not yet seen an integrated example with fastai but I would be surprised if no-one in the community is working on an integrated multi-modal approach.
Thanks for sharing with us about this interesting dataset. I wanted to experiment with open multimodal datasets.
I am having a hard time to find examples in docs.fast.ai itself for this type of MultiModal scenario.
Two approaches I would experiment with
Turning all features into text ie turning these categorical and numerical as string and concatenating them into a text column as a single input.This would turn the multimodal into a simple text problem.
Eg: Dresses [SEP] General [SEP] 34 [SEP] 5 [TEXT]
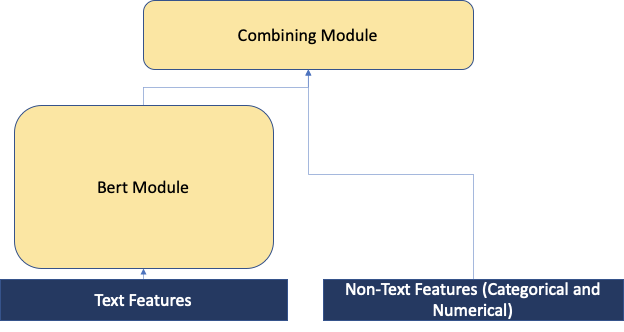
Changing the head of the model to combine the features from numerical & categorical columns as described in multimodal toolkit [2]
This paper: Benchmarking Multimodal AutoML for Tabular Data with Text Fields
compares a bunch of strategies for modeling such data and finds the one used in autogluon can give really high accuracy (it even gets 1st or 2nd place on historical leaderboard of numerous ML competitions from Kaggle & MachineHack)