Well, if someone could explain to me how this cudnn “layer” actually works…
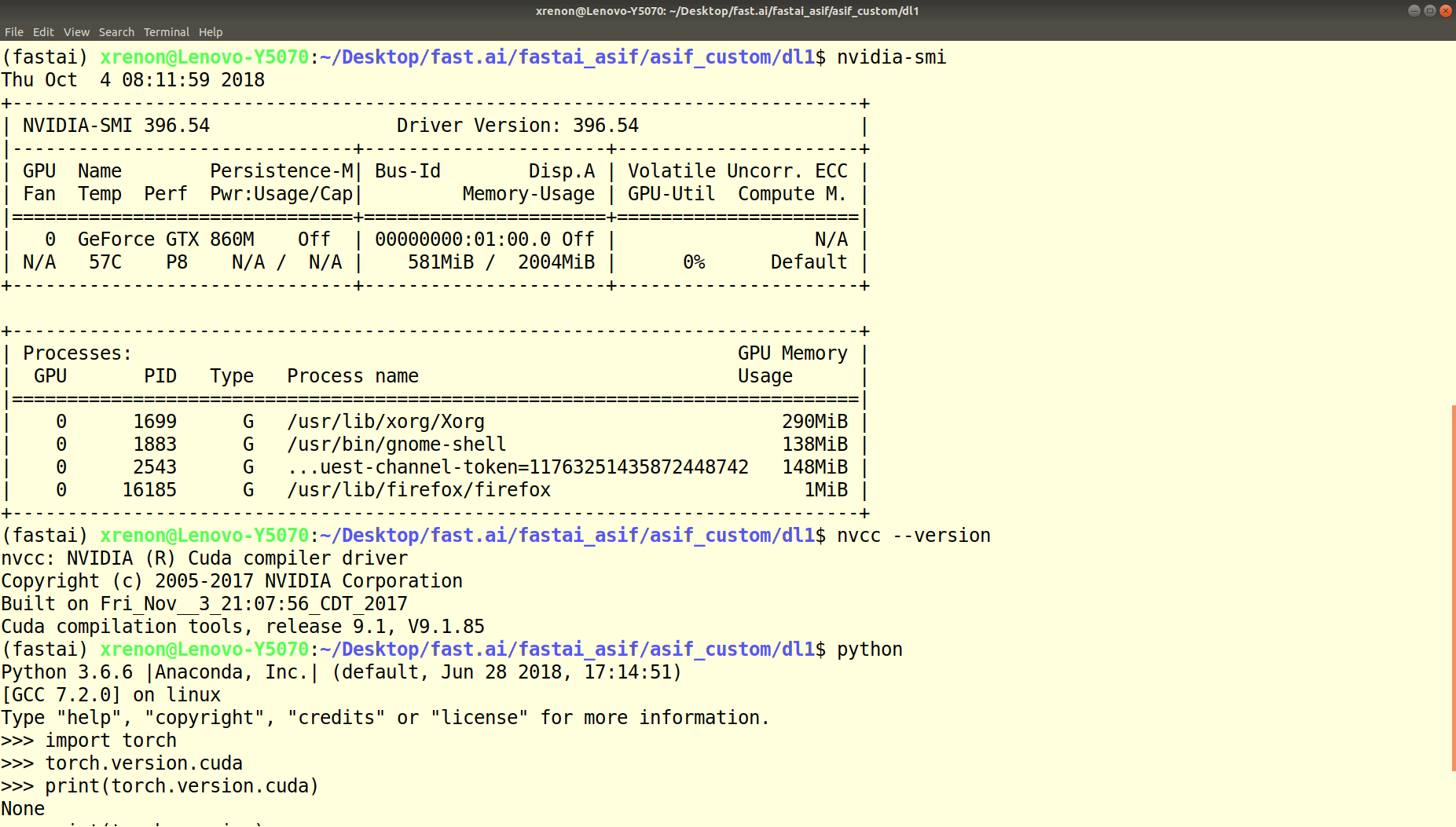
So - I can’t really answer that, because I don’t know how to really test or verify that. I run the following code for checking:
import torch
print('environment: fastai')
print('pytorch version:', torch.__version__)
print('cuda available? ->', torch.cuda.is_available(), ' - Version:', torch.version.cuda)
print('cudnn enabled? ->', torch.backends.cudnn.enabled,' - Version:', torch.backends.cudnn.version())
Now, for the fastai (not v1) environment, setup after fresh pull it gives me this:
environment: fastai
pytorch version: 0.3.1.post2
cuda available? -> True - Version: 9.0.176
cudnn enabled? -> True - Version: 7005
That would lead me to think cudnn works correctly. But if I do it on my knowingly non-working pytorch cuda9.2 version in a different conda env I get this:
environment: pytorch92
pytorch version: 0.4.1
cuda available? -> False - Version: 9.2.148
cudnn enabled? -> True - Version: 7104
This shows that “cudnn.enabled” doesn’t really mean anything 
So - do you have a proposition of how to check that it really is working? Is there some testsetup that could be run, where it is clear that cudnn would perform better than cuda and this could be switched/activated to show a difference between a pure cuda run vs. a cudnn run of an optimizer/model?
This also shows, that it is absolutely possible to have different versions of cuda running on the same machine (which a lot of SO articles negate). (Caveat: not if you are trying to develop cuda applications, but as long as you run the “finished libraries” like pytorch in different versions…)
if you do locate libcudnn on your machine (at least on mine) this shows that in all the conda envs with pytorch this lib is present as .so etc. (in different versions accross different setups/envs). So I would expect this to be working also without installing the cudnn stuff manually from the nvidia-dev account pages…