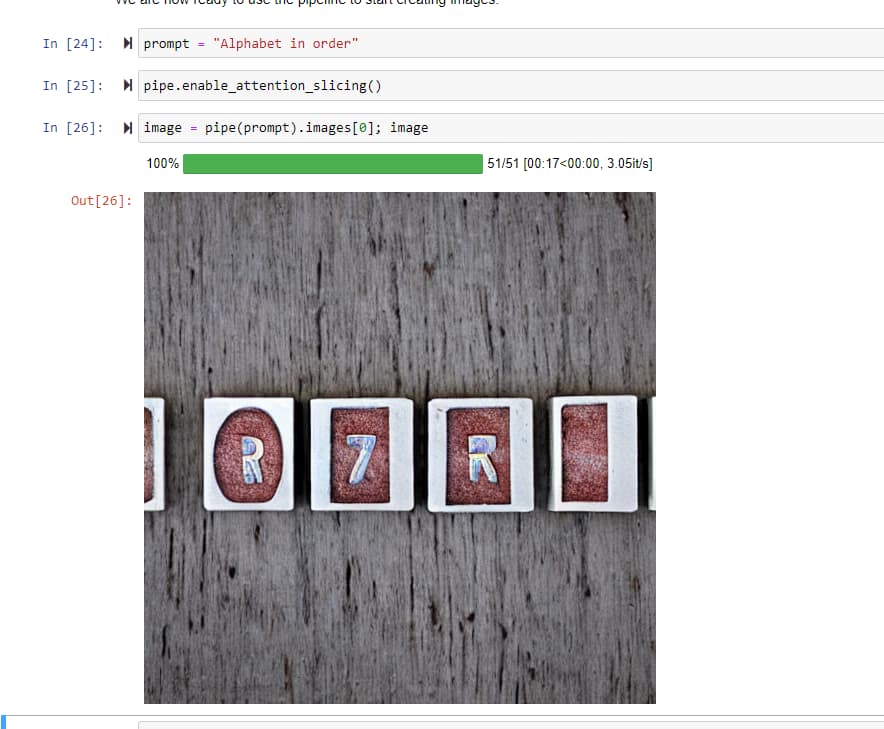
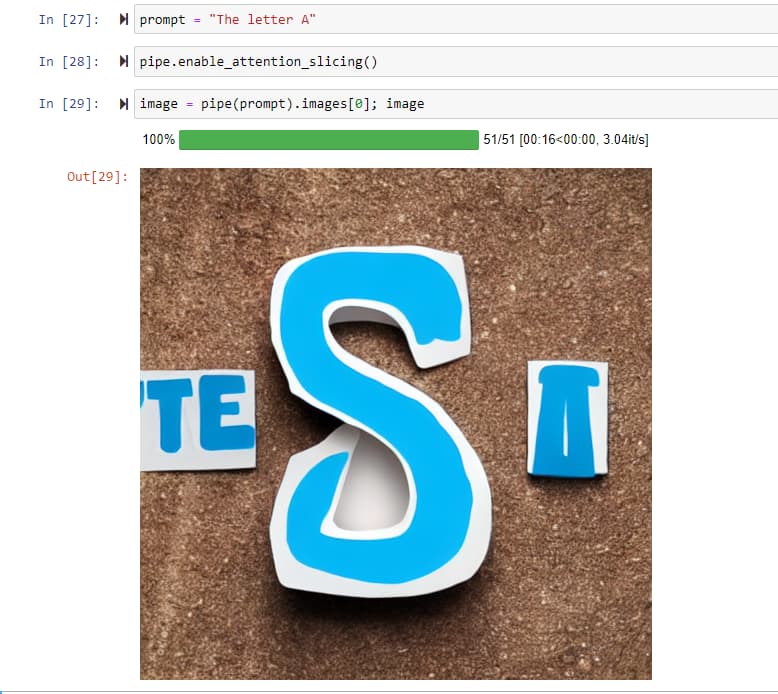
I have been playing around with the Stable Diffusion prompts and one observation I have made is that the model is very limited in the knowledge it has on specific letters.
I thought this one was interesting because it looks like a video game of some sort. I can pick out “Solver” just overall super interesting to see this lack of information being transmitted.
My guess is that these limitations are because of how the embeddings have been generated. There are not very many times where “A” actually does mean the letter A.
I don’t have any specific questions, but just thought this was interesting to observe!
Might be interesting to try fine tuning with lots of examples of letters, words, sentences, and paragraphs, in a variety of fonts and placed on different backgrounds, where the caption is the displayed text. (Or maybe if the text is placed on some image as a background, use the original image caption as the caption, with “with the text ‘…’ displayed”). Dunno if any of that would help…
Kinda OT, but seeing the last image (“problem solver…”) reminded me of a comment I heard someone make about lucid dreaming; that in a lucid dream, when you look at a written/printed page , it doesn’t actually make any sense. (or that it isn’t “stable” … it keeps changing) …
I may be off to total conjecture land here, but I’m so tempted to think that maybe dreams are also probably conjured out of some kind of noise that happens to be there at the time ? … but then the question would be, “what is giving the visual system the prompts?”
The core dataset was trained on LAION-Aesthetics, a soon to be released subset of LAION 5B. LAION-Aesthetics was created with a new CLIP-based model that filtered LAION-5B based on how “beautiful” an image was, building on ratings from the alpha testers of Stable Diffusion. LAION-Aesthetics will be released with other subsets in the coming days on https://laion.ai.
So, I doubt that images of specific letters got classified as “beautiful” images.
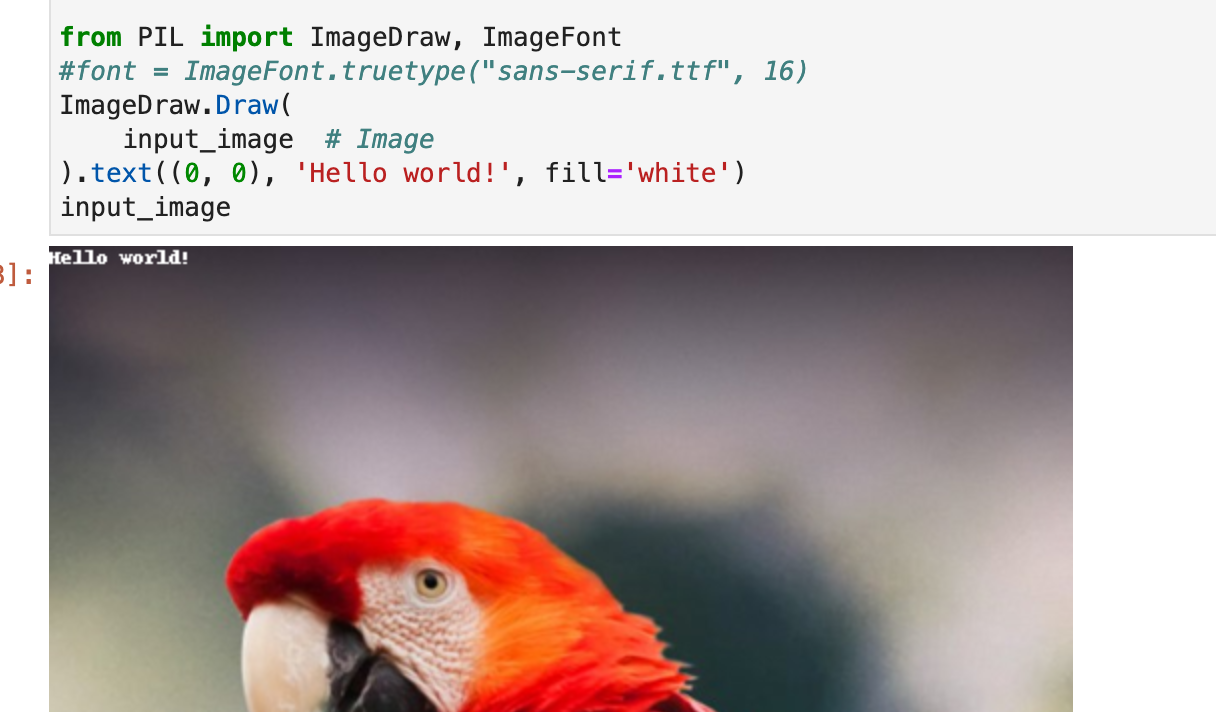
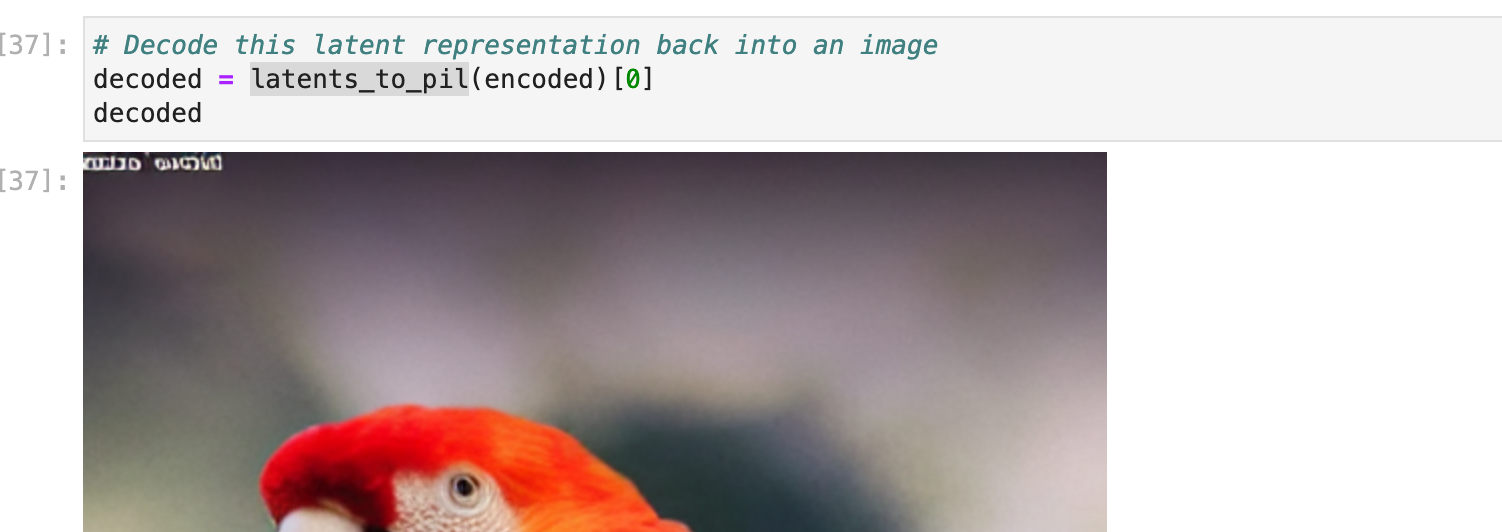
It is as well the autoencoder issue. It seems that compression does not have a way to represent text. I’ve added text to the parrot image to see how it will be decoded and here are the results. I haven’t tested different font sizes yet as my gpu instance is missing fonts :(. But the text after AE looks like texts that you find on other stable diffusion generated images.
The AE is making the text looks bad if it is smaller than 30px. So retraining stable diffusion will only work for large text. Here is how it works now: