Ah, I was misunderstanding your process. But anyway, I think the 2 plots are different:
When you call lr.find() , before unfreeze, you let the weights in only the last layer change. Its loss function will act differently compare to the after unfreeze case. In that case, all the weights allowed to be changed.
(Actually, in the first batch your 2 models are the same. But after some batchs, the weights are totally different )
Imagine lr.find() is similar to train your model in one epoch. The different is it will stop when the loss increase drastically.
Even if you have the exact same network, you will probably get different curves for lr_find since the training is always random (we shuffle the data in batches). lr_find doesn’t change the weights: it saves the model before doing anything else then loads it back at the end.
In this case, you should probably use lr_find after unfreezing, and you can even use differential learning rates while running lr_find.
I am wondering whether we could use the lr_find result before unfreezing can tell us the LR for the later layer, and lr_find result after unfreezing can tell us the LR for the earlier layers.
In other words, say you run LR finder without unfreezing, and it says things start to get worse at 1e-4. You unfreeze and run LR finder again and it says things get worse around 1e-5. Using Jeremy’s “pick LR way well before things gets worse for earlier layers”, we would pick max_lr=slice(1e-6, 1e-4).
Just a gut feeling and not based on ay experiments. What do you guys think?
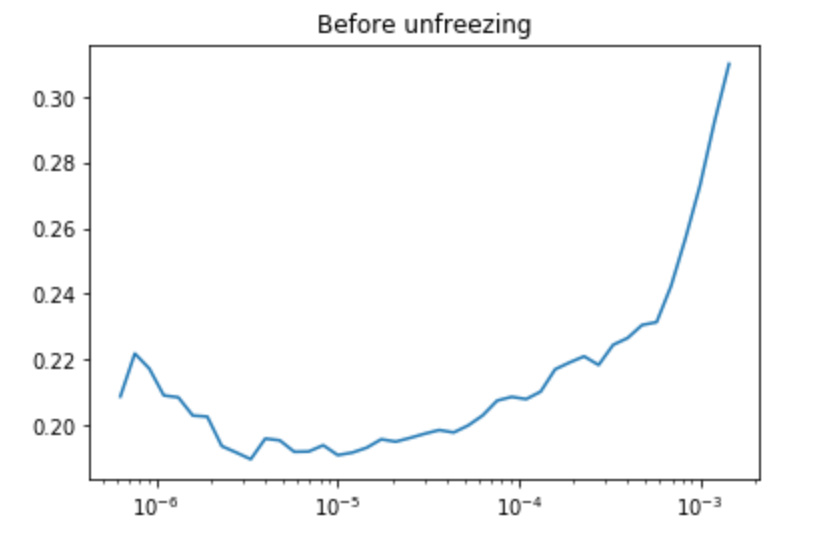
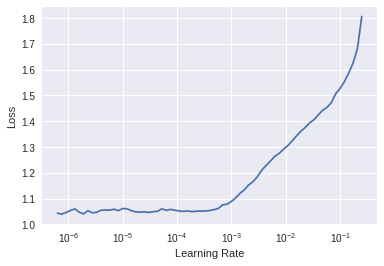
I am trying to train a classifier on a bunch of images (144 images in 4 categories. )
after running fit for 4 epochs, and then (before unfreezing) lr_find
i get
that looked like a good range for the unfrozen would be 1e-3, 1e-2
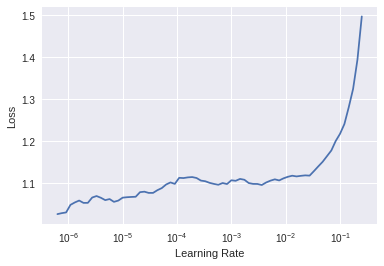
but after trying that i get
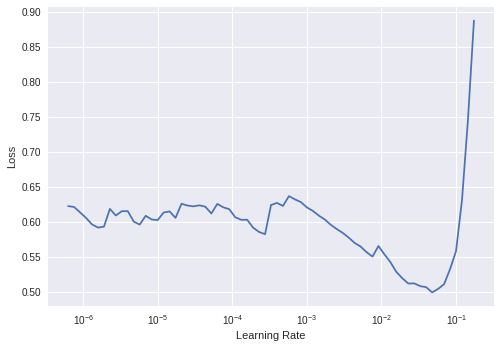
First of all I just want to say that Im very interested to hear how much better results you can get with these methods. I believe that it shouldn’t make huge difference. But I also need to ask question about this graph above. I sometimes got same kind of shapes and I think I have the same problem of small amount of data but the question is that is it always too small train set or can we get this kind of graphs in some other cases too?
I experimented with 2 sets of training rate based on lr_find() output: One with a higher learning rate (based on without unfreeze()) and another with a lower learning rate. I continued training .fit_one_cycle() for the same number of epoch. Eventually both sets of learning rate resulted in very similar error_rate.
Have the same issue.
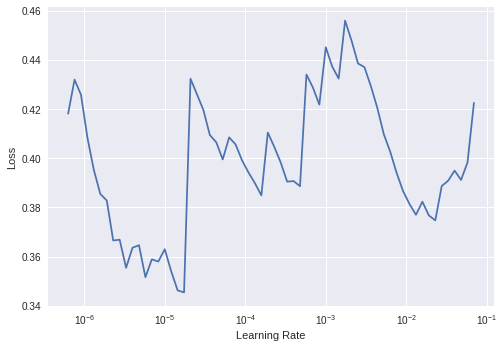
When I just load imagenet weights, after lr_find() plot looks more like on course site (decreasing and then jumping infinity) but I always got similar plots as yours (straight and then infinity) after first learn.
I think that mean, network is already finetuned, and won’t easily learn more.
There was an example that network is a multidimensional function of valleys and hills, and we want to find the lowest valley, so I used two approaches:
learn again with slightly different parameters (restart all and find better valley)
learn unfreezed with lr near to the left side of the plot (correct valley, go to its bottom)
I tried both and usually, it progress a bit (1-5%)
For more, I think you need to check out your dataset, model size, bach size etc.
Edit: As in lesson3 for second step Jeremy choose max_lr = slice(a/10, b/5) where a last value on not-increasing-line and b is value on previous lr_find plot.
Seems to be better.
If learn.lr_find() yields non-deterministic results, how should we choose the range for lr? One time running it shows that 1e-04 gives a low error, while another says that 1e-03 is much better. Is there really a best range for lr?