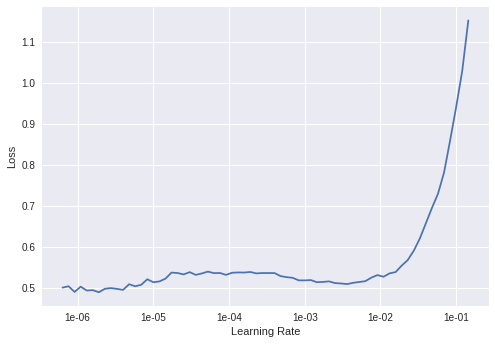
This may help you, I’ve subclassed the Recorder so that will plot the LR’s for all the layer groups.
from collections import defaultdict
class MyRecorder(fastai.Recorder):
"A `LearnerCallback` that records epoch, loss, opt and metric data during training."
_order=-10
def __init__(self, learn:Learner):
super().__init__(learn)
def on_backward_begin(self, smooth_loss:Tensor, **kwargs:Any)->None:
"Record the loss before any other callback has a chance to modify it."
self.losses.append(smooth_loss.item())
if self.pbar is not None and hasattr(self.pbar,'child'):
self.pbar.child.comment = f'{smooth_loss:.4f}'
def on_train_begin(self, pbar:PBar, metrics_names:Collection[str], **kwargs:Any)->None:
"Initialize recording status at beginning of training."
self.pbar = pbar
self.names = ['epoch', 'train_loss', 'valid_loss'] + metrics_names
self.pbar.write(' '.join(self.names), table=True)
self.losses,self.val_losses,self.moms,self.metrics,self.nb_batches = [],[],[],[],[]
self.lrs = defaultdict(list)
def on_batch_begin(self, train, **kwargs:Any)->None:
"Record learning rate and momentum at beginning of batch."
if train:
for i, lr in enumerate(self.opt.read_val('lr')):
self.lrs[f"layer_group_{i}"].append(lr)
self.moms.append(self.opt.mom)
def plot_lr(self, show_moms=False)->None:
"Plot learning rate, `show_moms` to include momentum."
n_layer_groups = len(self.lrs)
if show_moms:
_, axs = plt.subplots(n_layer_groups, 2, figsize=(12, 4), constrained_layout=True)
axs = np.array(axs).flatten()
for i, (layer_group, lrs) in enumerate(self.lrs.items()):
axs[i * 2].set_title(f"LR for {layer_group}")
axs[i * 2].plot(range_of(lrs), lrs)
axs[(i * 2) + 1].set_title(f"Momentum for {layer_group}")
axs[(i * 2) + 1].plot(range_of(self.moms), self.moms)
else:
_, axs = plt.subplots(n_layer_groups, 1, figsize=(12, 4), constrained_layout=True)
axs = np.array(axs).flatten()
for i, (layer_group, lrs) in enumerate(self.lrs.items()):
axs[i].set_title(f"LR for {layer_group}")
axs[i].plot(range_of(lrs), lrs)
def plot(self, skip_start:int=10, skip_end:int=5)->None:
"Plot learning rate and losses, trimmed between `skip_start` and `skip_end`."
n_layer_groups = len(self.lrs)
_, axs = plt.subplots(n_layer_groups, 1, figsize=(8, 8), constrained_layout=True)
axs = np.array(axs).flatten()
for i, (layer_group, lrs) in enumerate(self.lrs.items()):
lrs = lrs[skip_start:-skip_end] if skip_end > 0 else lrs[skip_start:]
losses = self.losses[skip_start:-skip_end] if skip_end > 0 else self.losses[skip_start:]
axs[i].set_title(f"{layer_group}")
axs[i].plot(lrs, losses)
axs[i].set_ylabel("Loss")
axs[i].set_xlabel("Learning Rate")
axs[i].set_xscale('log')
axs[i].xaxis.set_major_formatter(plt.FormatStrFormatter('%.0e'))