A language model could probably guess (or make up?) what was there based on the surrounding context, but no guarantees that this guess is correct 
2 Likes
So from lesson 1, I tried creating an model for classification of alligator and crocodile.
The model did not give much accuracy (it was around 60%) even after cleaning mislabelled data using ‘Imageclassifiercleaner’. Probably because of the features used to identify the animals was not directly available in the input images.

So next I used another dataset to create a model for classifying cheetah and leopard. The model was able to classify well and got accuracy of about 95 %.
Here is Kaggle notebook, I’ve check and it is accessible to public 
Since I am a beginner, with Lesson 2 video, I was feeling bit difficult to understand the installation process and other software usage.
I’m using Kaggle/Google colab to run my model and am familiar with these than other ones mentioned. So I created the “app.py” and “requirements.txt” using the “writefile” magic command in Kaggle. I then downloaded all the 3 files needed for deployment (including export.pkl).
To deploy model I directly uploaded the python file (app.py), saved model (export.pkl) and requirements file in HuggingFace spaces using “Add file” option.
So now this is My HuggingFace app after deployment, which can be used to classify leopard and cheetah.
8 Likes
Is there a way we can call your model via an API call?
Working on a demo that strings together a call to my example and then to your depending on the former’s result. Lmk.
1 Like
Great approach!
Is your machine Mac or Windows? Which bits were feeling a bit difficult to understand - using git; installing python; something else? I’m keen to help you (and anyone else in your situation) get things installed and working, if you’re open to spending time on that. I think having a productive local working environment on your computer can be very beneficial.
2 Likes
So far, I’ve completed the following as part of lessons 1 and 2 of fast.ai:
-
Read chapter 1 of the fast.ai book
-
Ran the cat/dog model on Kaggle via the GPU processor here: fast.ai_lesson_01_first_example_model | Kaggle
-
My Hugging Face space with a demo created using Gradio of the above cat/dog model is here: Cat_or_dog_predictor - a Hugging Face Space by Zakia
-
Read chapter 2 of the fast.ai book
-
Created my own model to classify pediatric chest X rays - either pneumonia or normal using Chest X-Ray Images (Pneumonia) based on the Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning scientific journal (have completed reading this paper, too) - the model is on Kaggle, ran using the GPU processor here: chest_x_ray_pneumonia | Kaggle
-
My Hugging Face space with a demo created using Gradio of the above pneumonia/normal pediatric X-ray images model is here: Chest_x_ray_pneumonia_predictor - a Hugging Face Space by Zakia
Note:
The training dataset has:
3875 rows of PNEUMONIA X-Ray images
1341 rows of NORMAL X-Ray images
The accuracy is 81.25% trained on 3 epochs.
Please let me know of any feedbacks/comments/thoughts/suggestions - especially of what’s the best practice/techniques (if anyone knows) when handling medical images like X-Rays here, to improve the performance of the model? Any other pertinent advice will be most appreciated.
Thanks so much in advance, all! Much appreciated…
Looking forward to lesson 3 of the awesome fast.ai course in a few hours time!
10 Likes
This is awesome, glad you are getting started with an ongoing Kaggle competition, that is one of the best ways to learn and study deep learning.
4 Likes
I’ve got a series of 5 notebooks on that topic here:
Also check out the x-ray tutorial:
9 Likes
I think we should be able to use an API since it is a Gradio app. At the bottom, there is the Gradio app link.
I was also wondering and hopefully will do research on adversarial attacks. How to protect the model from recognizing any one of us as either a Marvel or DC character  . Do you have any ideas?
. Do you have any ideas?
5 Likes
I only see two cells in this linked notebook. The second cells is listing all the files in the dataset. Am I not looking at the right notebook?
1 Like
This week I tried training resnet18 to distinguish serif fonts from sans-serif fonts, using specimens from identifont.com. It does really well: the error rate is around 5% on the validation set. I also successfully deployed the model on HF Spaces! See here: Font_classifier - a Hugging Face Space by skalyan91, and see below for a screenshot (the image shown is of Times New Roman, which is in fact a serif font).

As you might expect, the model does really well on test images from identifont.com (which show a standard sample of letters in a font, at a standard size and in a standard arrangement); but it does very poorly on almost any other sort of font sample! In particular, it tends to classify everything as “serif” (even if the image clearly contains text in a sans font).
10 Likes
Hi everyone. Sorry I am a little late to the party, I have been at my first ever academic conference over the past week and a bit. I have still been following along with the lessons and some of the contributions to this page—lots of impressive applications. Well done everyone! Also, thanks and congratulations to fast.ai for creating such a useful and accessible platform for us all.
I recently watched the movie CODA and was inspired to dedicate my fast.ai coursework to building inclusive technology. To kick it off, this week I created a sign language digit classifier using a Kaggle dataset, based on what I learnt in lessons 1 and 2 of fast ai Part 1 v5. Click through for my gradio app and colab notebook. I have shown all my workings in the colab notebook, including both attempts to create a web app (see below for more info).
A couple of reflections I wanted to share in the forum:
- All images in the Kaggle dataset I used to train the classifier have white backgrounds, and no objects other than a single hand in the image. This may cause issues for this model in production as the model could struggle to classify images with different backgrounds or images with additional objects in the frame.
- Originally I created a notebook app from the model and tried to deploy the app to Heroku, but I couldn’t quite get it to work! I think it was because my
export.pklwas too big to be handled bygit. After trying and failing a couple of times I used Gradio and hosted on Hugging Face (HF) spaces (see attempt 2 at the end of the notebook), which was very easy (great instructions @ilovescience). HF automatically handled the large.pklfile withgit lfs. Next time I use Heroku I will look into usinggit lfsmyself.
Thanks Jeremy, fast.ai team and fellow students. I am having a ball in this course.
13 Likes
Absolutely! I did some competitions with plain PyTorch and also with Lightning, writing hundreds/thousands lines of code usually. (Seems like my software development background kicks in, and I can’t help but write a ton of non-modeling things…) So this time, I decided to go with the fastai lib and see how far I can go with it. So far, so good!
7 Likes
So, here is my late entry to the gradio party:
This classifies between images of birds, planes and superman flying in the sky, which was quite hard to distinguish in early days of comics. Not now, with Fastai and Gradio ![]()
One interesting thing I’d like to point out is that when looking at the data for “planes in flight” or “planes flying”, I got a few images of the cockpit with pilots possibly because they are “flying the plane”. Also birds in superman colors (red, blue) had a bit less confidence (they were classifying alright but the probs were not as high as a yellow bird)
6 Likes
Answer: By combining forces in the MarvelAndMe application
This mobile friendly web application is built on top of Quasar, a Vue based development framework that allows developers to deploy web, desktop, and device native versions of an application using a single codebase! It also makes frontend challenged folks like me look like a UX god.
If folks would be interested in learning how to build Quasar/Vue apps to showcase your ML models lmk. If there is enough interest I’d be up to putting together a livestream and go through the whole process from beginning to gh pages deployment.
9 Likes
btw, my Vietnamese friend says we need more asian representation ![]()
1 Like
Thats clever work, but the app is still not immune to adversarial attacks ![]() .
.
For example, I tried this.
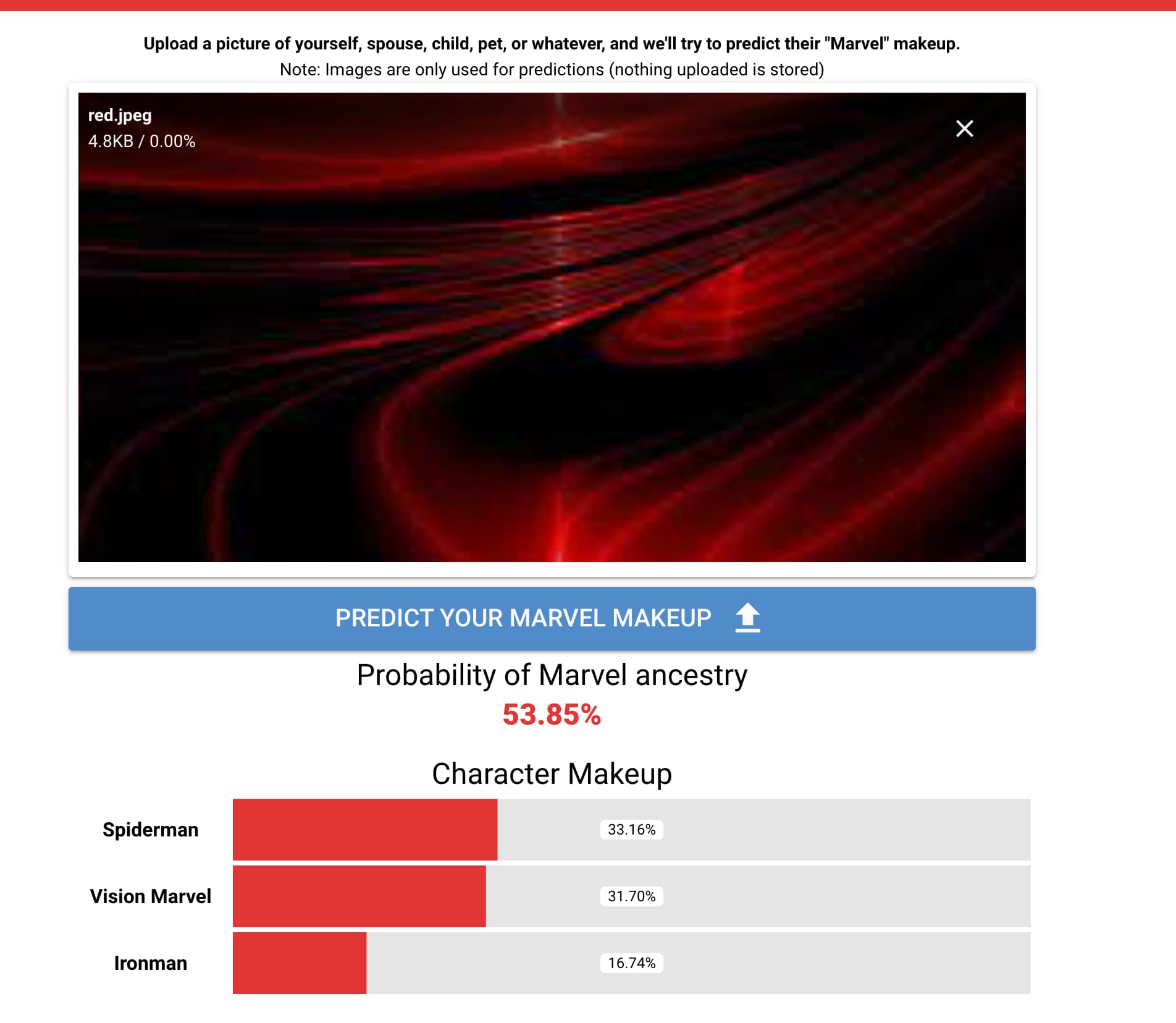
So my question still remains? I remember Ian Goodfellow has some talks about this.
3 Likes
Yah there is still work to do.
As we get further into the course and more tips and tricks are revealed, I’m hoping to see these models improve.
1 Like
Yup true. When I start doing some research on this I will share my findings here ![]() .
.
1 Like
It’s discussed in the book, and we’ll cover it in the course soon. Basically: remove the final softmax and use binary cross-entropy instead…
6 Likes
Looks like this is the first VueJS based ML webapp build using fast.ai. Atleast I couldn’t find anything else and no documentation about building VueJS apps with ML models, when we(Ravi Mashru & me) were trying few months back to build a movie-recommender app. Would really appreciate a live stream on this topic.
2 Likes