Brilliant stuff ! We can clearly see that you’ve enjoyed building this classifier. Thank you for sharing the details and also telling us a bit more about different art styles.
While we’re at it, I also have some questions around some of the things you’ve raised/mentioned. Perhaps people with more experience in the current fastai library can clarify / talk more about it, and/or provide pointers to documentation/blogs etc.
I’ve been in a similar situation working on a project this week (dataset: 1024x1024px). I first thought that it would probably make sense to pre-resize images, so that the training loop could “feed the GPU” faster. But then, I thought of using the RandomResizedCrop augmentation, which would introduce more variation to the training process. As far as I understand, this is done in-memory on CPU per item (aug_transforms). Am I correct in understanding that there would be no real alternative to pre-compute this step ? (the equivalent pre-sizing technique using up a lot of disk space to create more randomly-resized-and-cropped training data, and still it wouldn’t really cover the possibilities of on-the-fly every-time randomisation.)
I also would like to experiment with this and understand this better. Right now, I used the RandomResizedCrop to 512px to get better results than 224px, the number being somewhat arbritary. Is there a good post/article that talks about how resizing affects the training process, mostly in terms of model performance(in terms of loss/metrics), perhaps also providing general hints on how to go about resizing when starting out with a baseline all the way to fine-tuning ?
It’s been a while since I’ve used the lib, so I’m just trying to figure out these details that might seem obvious to the “actively been using fastai” people here. Cheers and thanks in advance !
Wow! amazing work! and thanks for sharing! I really enjoyed playing around with the HF space and top three really do seem to get the jist of the piece.
While playing around with this, I had the idea that using something like this, it might even be possible to separate out the fakes from originals for a given artist?
FYI: I’m refactoring my “Is it a Marvel Character” image regression model one session at a time, making sure to note from what lesson each refactoring comes from.
Why am I doing this?
As we are introduced to new ways of improving our models each week, it can be confusing remembering where we learned about each of them. When you want to dive deeper into one of these improvements and revisit the particular lesson where it is covered, frankly, it can be difficult to find out where that was. I’m hoping to remedy some of this by releasing new versions of my Kaggle notebook and indicating the lesson from which each change derives.
Anyways, hopefully this will be of value to some folks (it is for me at least).
Just added the bits learned from session 2 with a twist: Showing you how to clean up data used in a regression task (rather than the multiclassification task discussed in session 1)
This stimulates a naive idea to simply the process.
A function RandomResizedCropToMatchGPU() might be useful. This would use the GPU memory size to determine optimal crop-size to maximally use the GPU, maybe even adjust dynamically if needed. Downside may be varying results depending on where code runs.
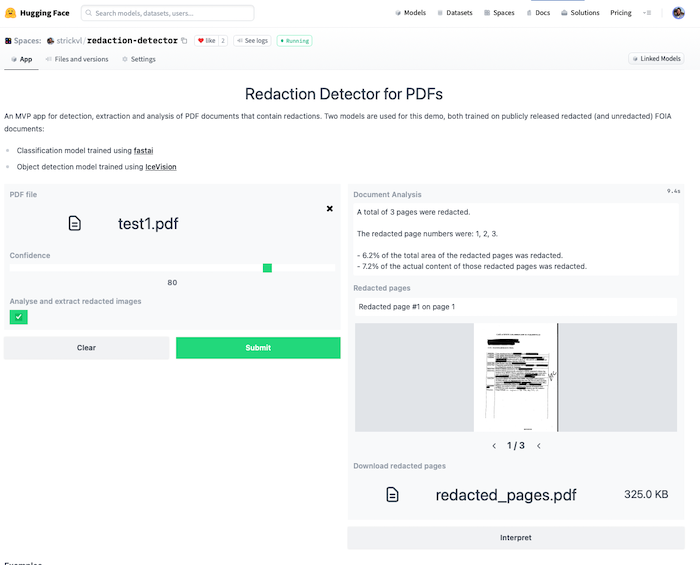
This week (post lesson 2) I created a few deployed MVP demos showcasing things I’ve learned so far, uploading them to the Huggingface Hub and using a Gradio Demo hosted on Huggingface Spaces.
I first created a ‘Space’ showcasing a simple classification app, got it running on Spaces (here) and then used the inference API to adapt one of the Github Pages examples (here). (Thanks to @nuvic for the base example and thanks to @ilovescience for the HF/Gradio blog tutorial… both super useful!)
I then decided to think a bit bigger and made a HF Spaces MVP application that showcases two models.
This MVP app runs two models to mimic the experience of what a final deployed version of the project might look like.
The first model (a classification model trained with fastai, available on the Huggingface Hub here and testable as a standalone demo here), classifies and determines which pages of the PDF are redacted. I’ve written about how I trained this model here.
The second model (an object detection model trained using IceVision (itself built partly on top of fastai)) detects which parts of the image are redacted. This is a model I’ve been working on for a while and I described my process in a series of blog posts.
This MVP app does several things:
it extracts any pages it considers to contain redactions and displays that subset as an image carousel. It also displays some text alerting you to which specific pages were redacted.
if you click the “Analyse and extract redacted images” checkbox, it will:
pass the pages it considered redacted through the object detection model
calculate what proportion of the total area of the image was redacted as well as what proportion of the actual content (i.e. excluding margins etc where there is no content)
create a PDF that you can download that contains only the redacted images, with an overlay of the redactions that it was able to identify along with the confidence score for each item.
I was — and continue to be — surprised that the free Huggingface Spaces environment has no problem running all this fairly compute-intensive inference on their backend. (That said, if you try to upload a document containing dozens or hundreds of pages and you’ll quickly hit up against the edge of what they allow.)
Full blog writeup of the process / the context around the app / use case is here.
(UPDATE: I added in my efforts to convert my Gradio app to a Streamlit app (see the blogpost) and some of the tradeoffs I discovered along the way.)
Well… we do have a considerable number of paired documents where we have the redacted version that was later released in a completely unredacted form. Unfortunately for the most part the things that get redacted are, I’d say, fairly unpredictable – names or email addresses or phone numbers etc. The thing that I can thing would make sense to create would be something that predicts the kind of the thing that has been redacted. I.e. is it just a name that’s been redacted, or is it something else. That would be a challenging next step for the project, esp if the idea would be for it to generalise.
I am little late here. But I started from Lesson 1 and created a " Planetary Objects Classifier" which will classify the Planets vs BlackHoles vs Asteroids vs Binary Stars. The accuracy is very low for the baseline, will keep improving this further. Please have a look and I would love some suggestions on improving it. Thanks.
This is great! And 85% accuracy on the validation set is nothing to be scoffed at! It seems that having better quality data for the training indeed is the bottleneck there. I wonder if there are some other datasets you could use? The Astropy community might have some suggestions there and there are people for sure working on similar problems.
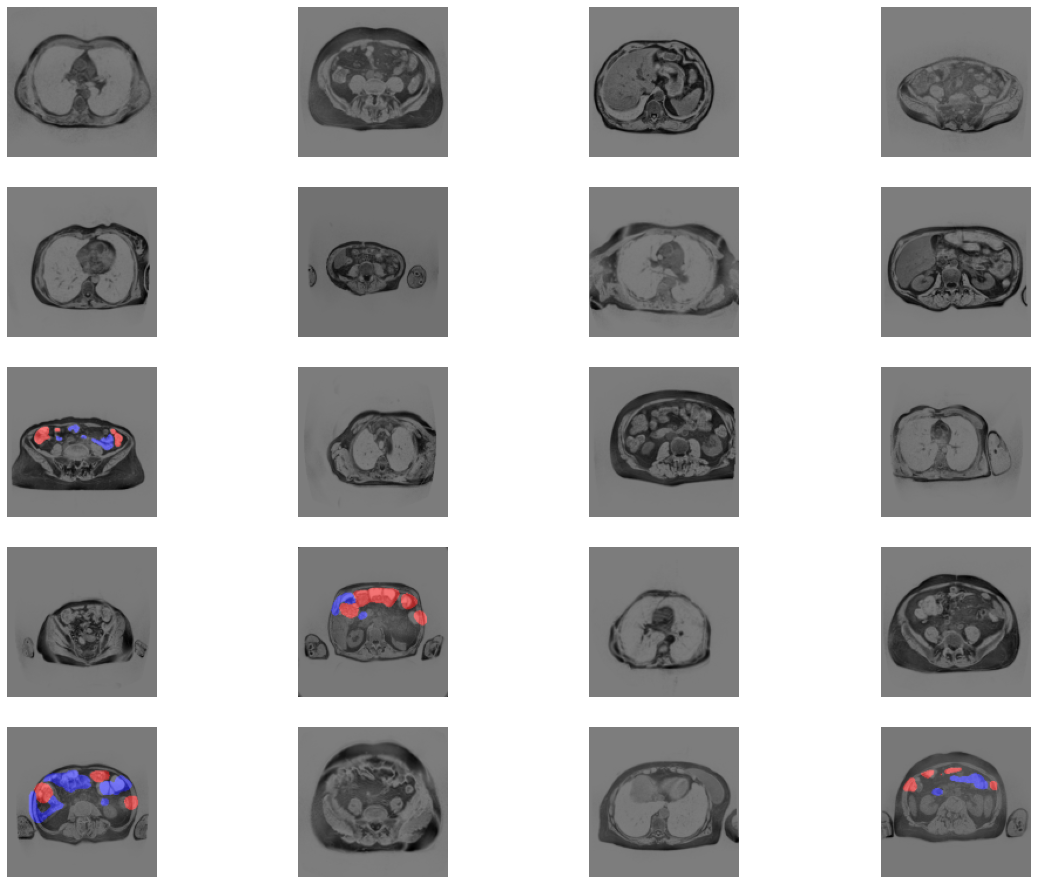
Improving the dataset with histogram equalization. A somewhat standard approach for this kind of data, I believe. If I am not wrong, there is some out-of-the-box functionality for this in medical fastai but I did some simplistic scripting instead.
Nothing fancy, I would say. But gives some tip of what one can do with the library after a few hours of hacking.
Also, I encountered a small problem when tried to load the model on Kaggle: PIL.Image complained about missing Resampling attribute. I fixed it as follows. (Including the rest of the code required to load a previously exported model.)
I wonder what is the best practice to ensure that inference works as expected? I guess that versions pinning is the only way to be sure that things go well when you restore a previously trained model. Like, use the exact same versions of everything involved into data preprocessing and model code when doing inference. On Kaggle, I used to create a special dataset for this, with all required libraries packed there. In production, something like a Docker image could be used.


 Notebook:
Notebook:  HF Space:
HF Space: 

 or a bread loaf
or a bread loaf  ?
? or retweet
or retweet