Here is a quick vision model using a Breast Cancer CT Scan Kaggle dataset.
My experience has been mostly with tabular data and NLP so I need practice working with image data.
The model does surprisingly well ! Comments welcome.
6 Likes
A few problems with your code. First dest and dest1 should be computed outside of the for loops as they are not dependent on the loop variable ‘o’.
Second you set your max_size to 20. That is way too small to build a model. Stick with 400.
To keep something similar to your code:
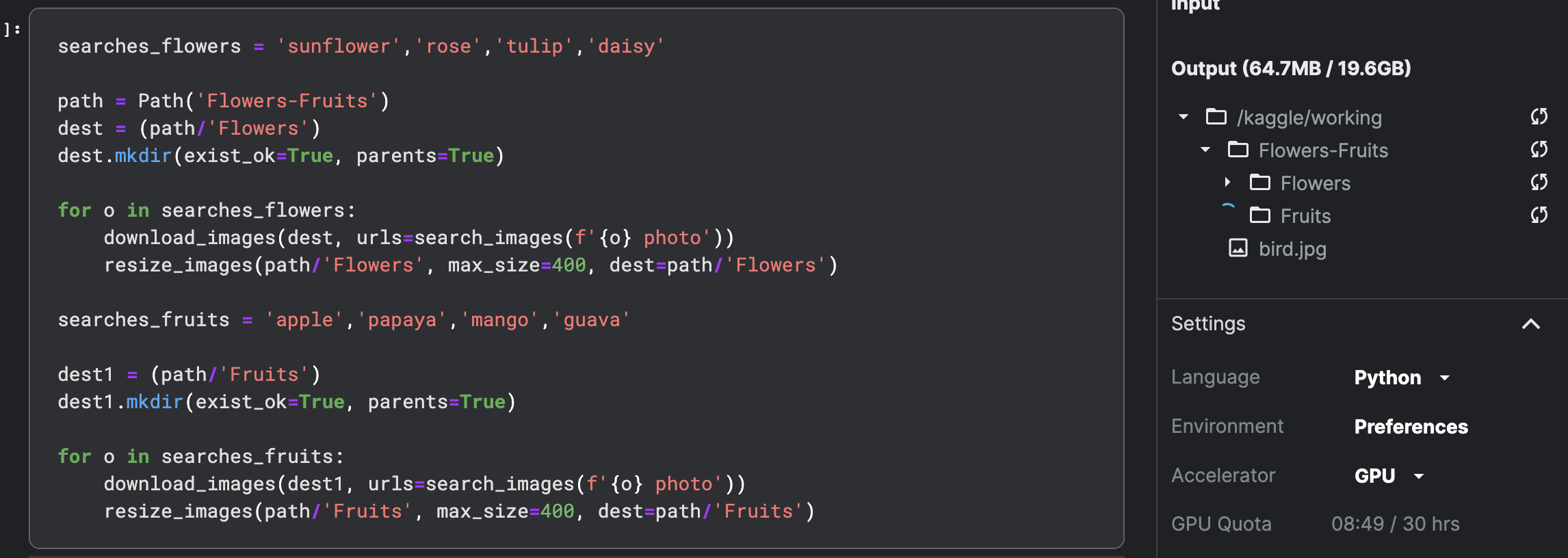
After that you need to delete images that are corrupted and cannot be read. If you went directly to the DataBlock it would fail.
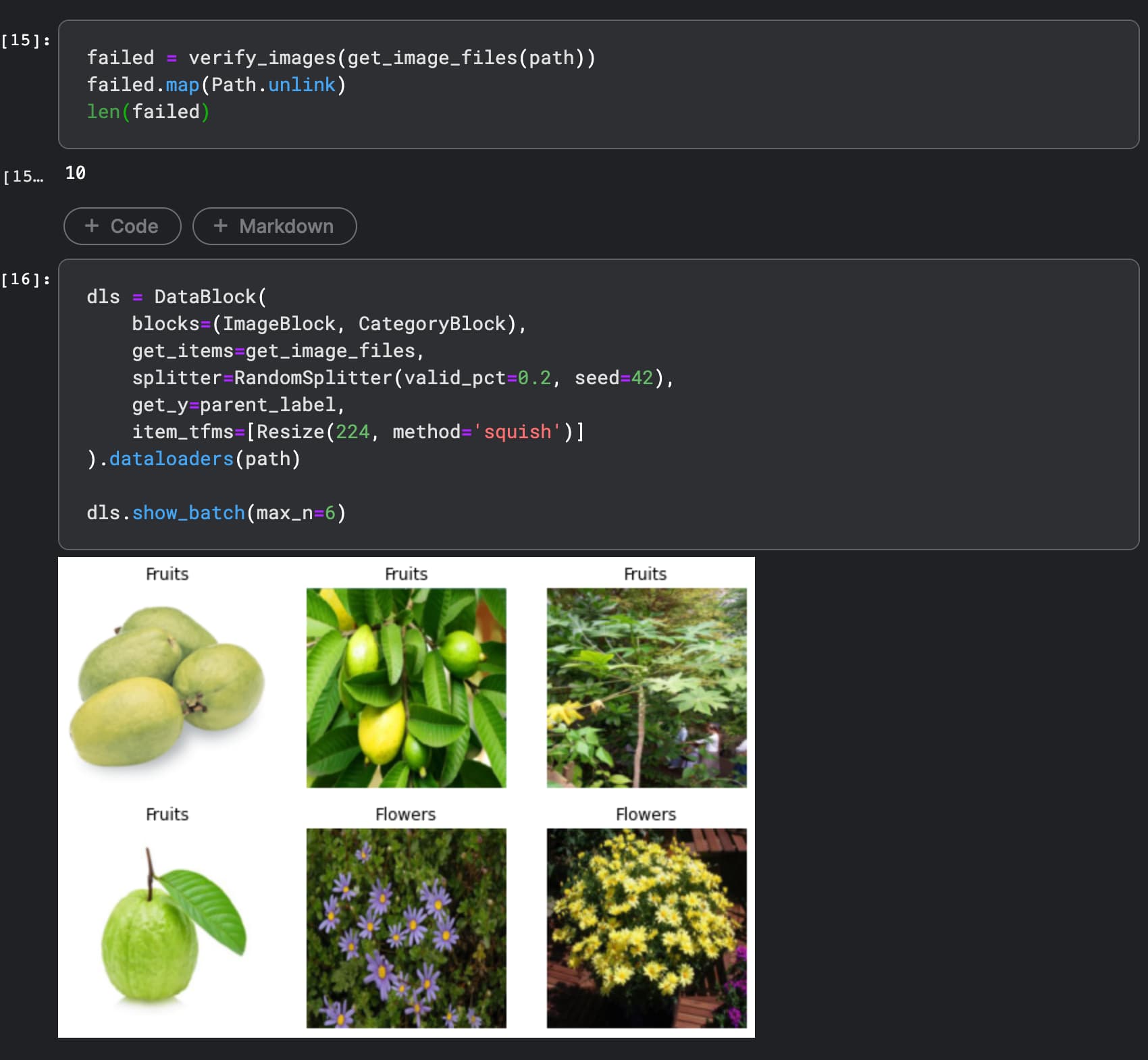
You can take it from here !
Thanks. I did exactly the same as above. I believe in kaggle there might be an issue in how I am passing the “Path”. Not sure though this is my guess.
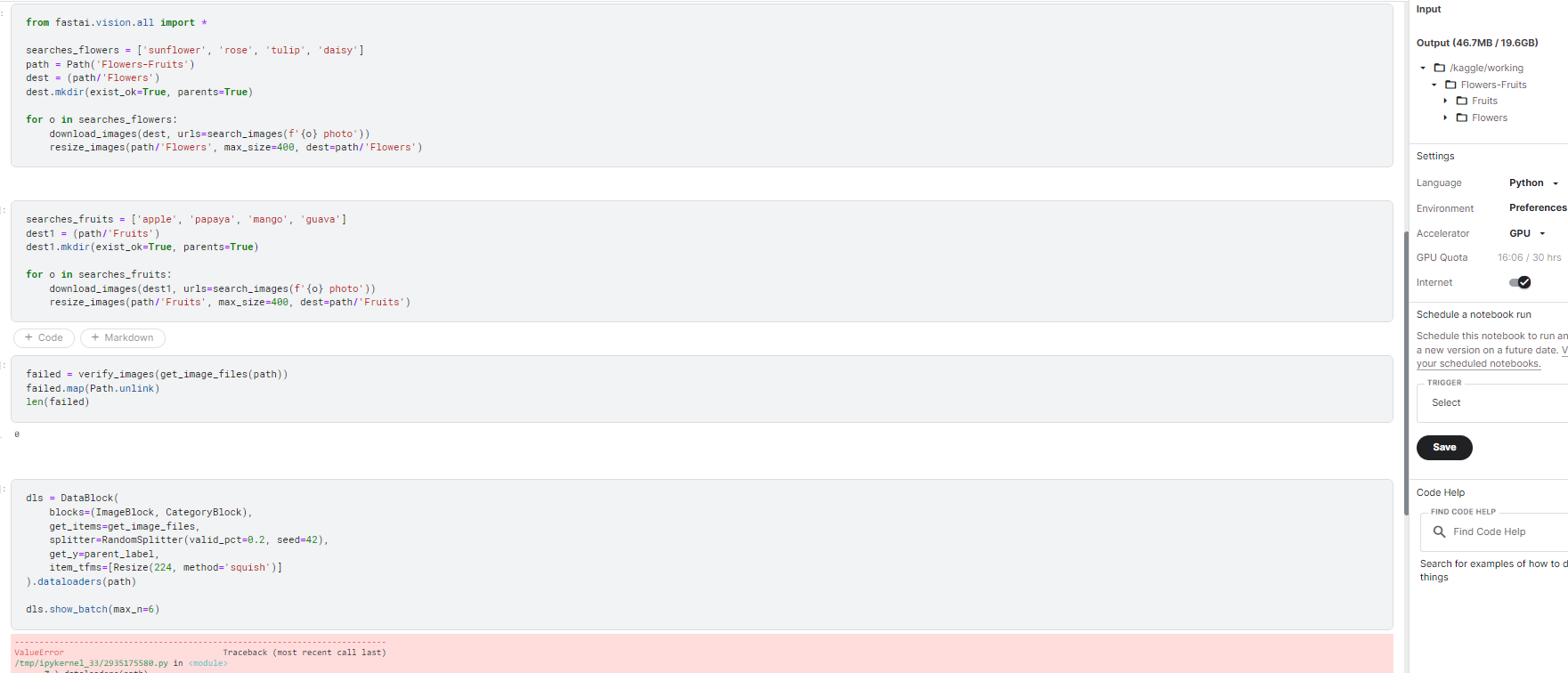
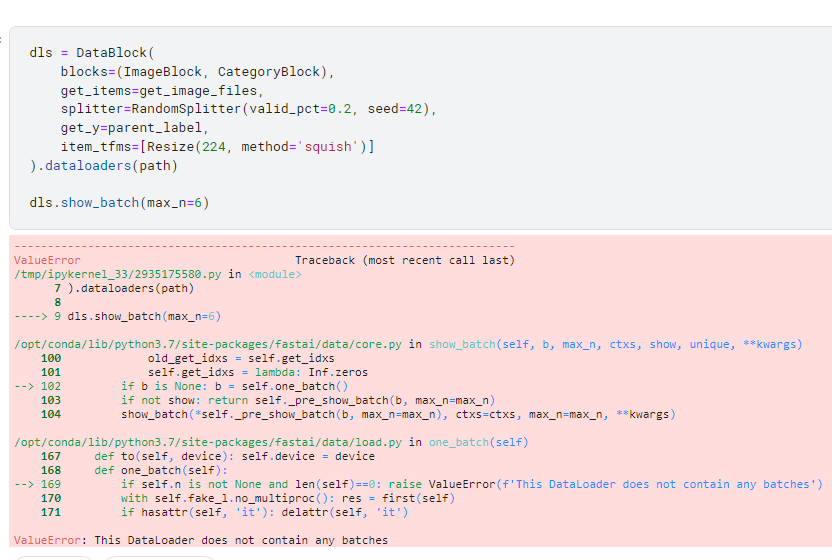
In googlecolab - I can see the batch output but not in kaggle. Anything i am missing here?
can you share what is the error you are getting?
Friends, this post was on HN’s front page today:
This is an excellent post. Fast AI is brought up – as is this course. Many of the elements Jeremy has taught in just these first two weeks were guiding lights in the author’s quest. I love one of the comments on HN referencing the article:

It’s a great example of what you can produce with small, consistent efforts. Be inspired!
18 Likes
Can you make your notebook public? Must be an issue in cell above your screenshot
1 Like
Can you confirm that path has the data you are expecting? check path.ls() and then dest1.ls()
I’m wondering if the images aren’t downloading properly
Try changing your batch size or collecting more data:
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(224, method='squish')]
).dataloaders(path, bs=8)
I think the problem is that the default batch size is 64 and you don’t currently have a single full batch of data
4 Likes
you are downloading only 20 images of each fruits and flowers class.
check here
def search_images(term, max_images=20)
..
fastai uses default batch size of 64. so it does not have enough images available for batch.
if you download more images around 100 or so it will work as it is.
Alternatively, you can decrease batch_size =4 or 8 in data loaders.
4 Likes
That’s it, the original code has max_images set to 200 and he changed it to 20
3 Likes
This worked spot on when I tried the notebook shared by @shravan.koninti . Really interesting problem. Thanks for sharing solution @KevinB
2 Likes
After some iterations: I have this.
I launched the gradio app inside kaggle notebook. It throwed an error after I saved the version. "FileNotFoundError: [Errno 2] No such file or directory: ‘/opt/conda/lib/python3.7/site-packages/typing_extensions-4.2.0.dist-info/METADATA’
Here is the link for gradio app (Only applicable for 72 hours as it is not launched in HF spaces) : Flowers_Fruits_Classifier
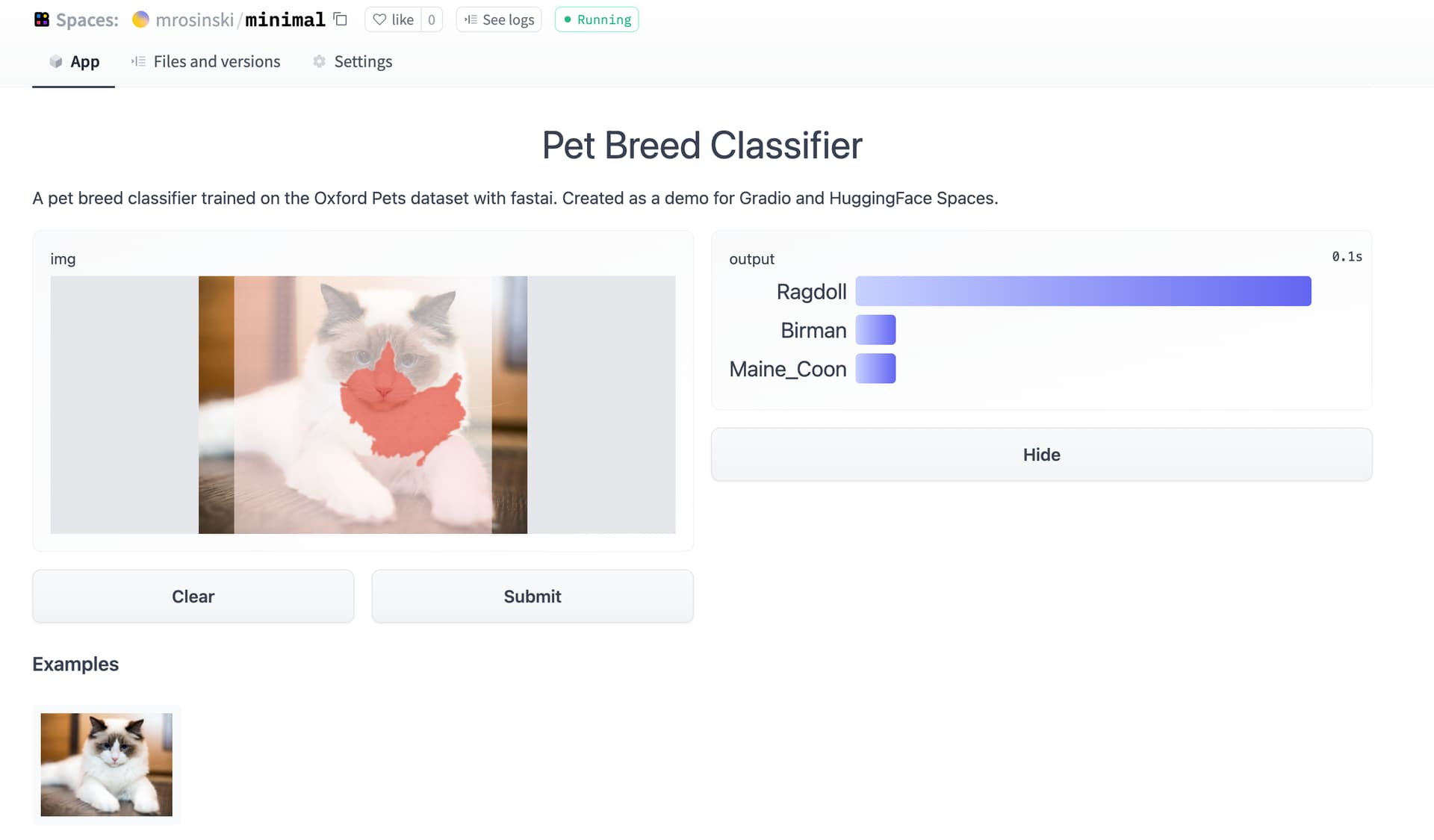
So I just trained a pet breed classifier and deployed it on Hugging Face Spaces. My biggest issue was not reading all of Tanishq’s blog post before pushing. Needed to install git-lfs and track both .pkl and .jpg files. But a previous commit that did not have tracking enabled was causing errors. I ended up having to recreate the repo because I wasn’t able to reset/fix previous commits.
It’s pretty exciting to have a way to get inference models into an app that you can so easily share with others! Here’s my Pet Breed Classifier!
7 Likes
Oh I guess its not running.
Better I deploy in HF spaces. Will get back again. thanks
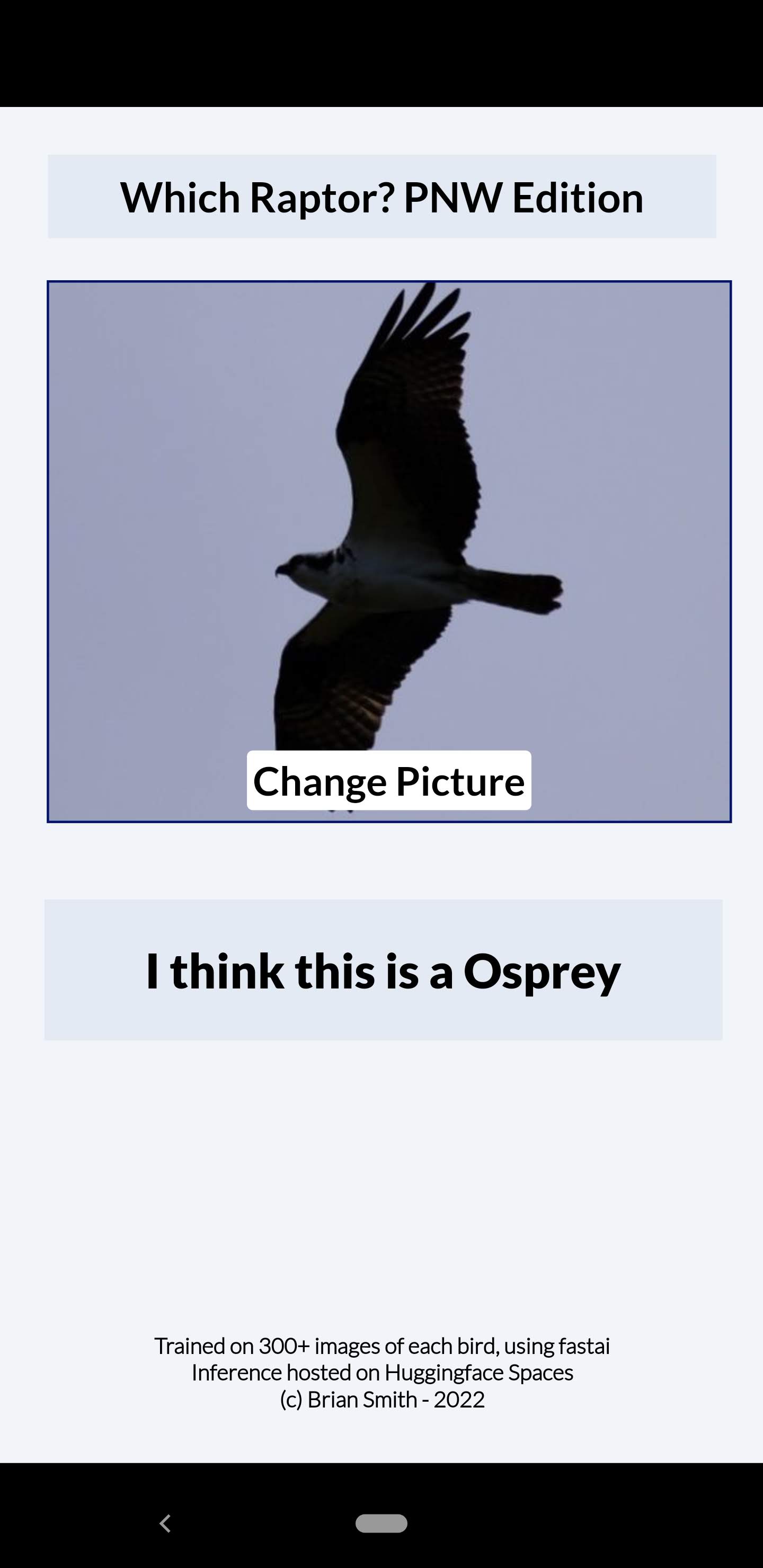
I created a Power App that sent pictures from my phone to the Huggingface API to identify from some common raptors I see on my local walks. The Power Apps solution file and swagger are shared on the Huggingface Spaces - link in the blog (Powerapps | Brian Smith’s Data Science Journey) as well as some general details of how I did it. If more detail is needed then let me know. This may be a great solution for any low-code people on the course!
12 Likes
So I decided to build on the Art Movement classifier that I shared earlier by leveraging the WikiArt Dataset - I kept the Genres that had at least 1000 photos to train on, which left 20 genres. Demo here.
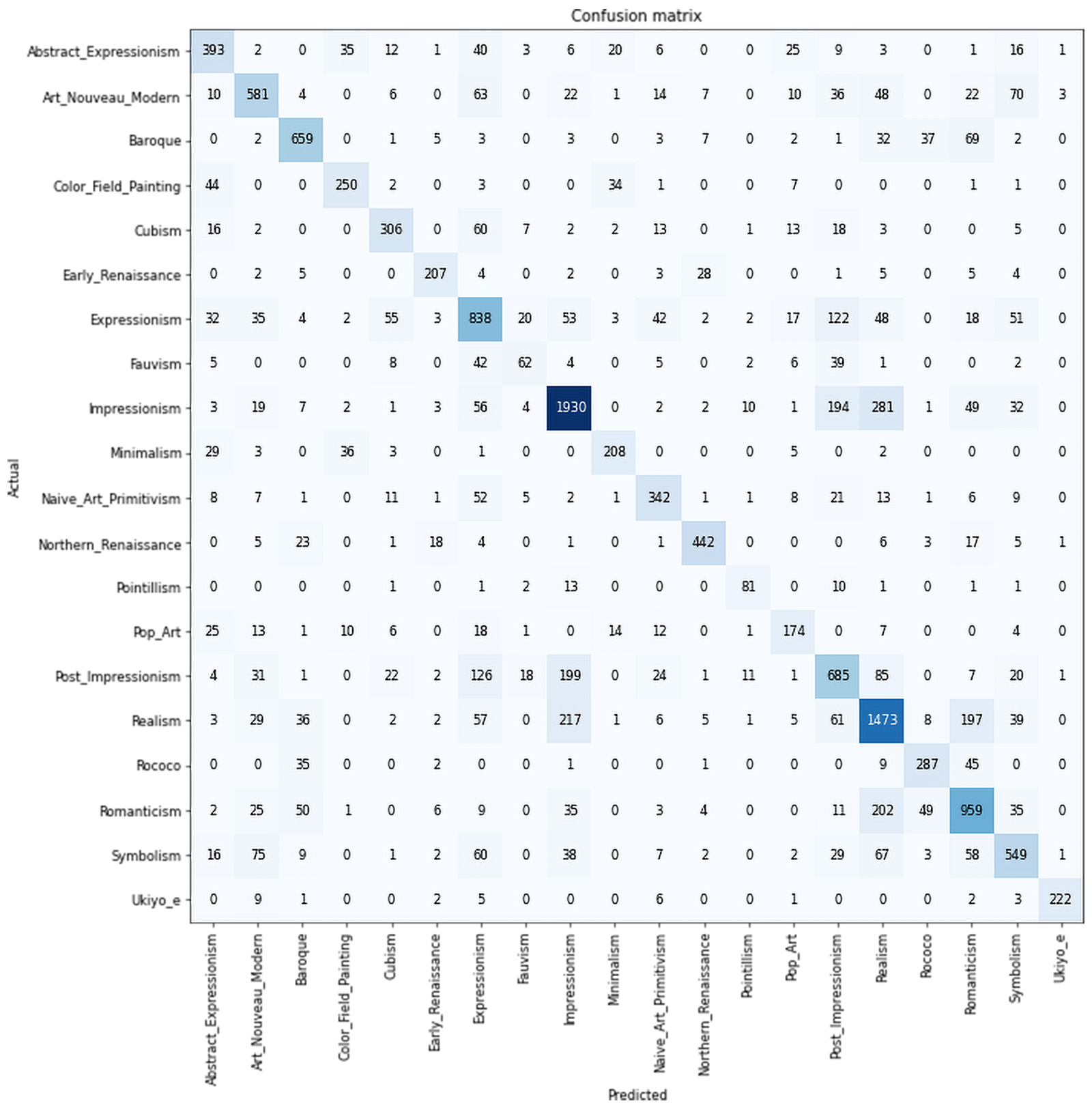
It’s interesting to look back at the first papers to do classification on this dataset - Saleh and Elgammal (2015) were getting accuracies around 50% with CNNs (training from scratch), and 58% using SVM on classeme features. Recognizing Art Style Automatically in painting with deep learning (2017) used transfer learning with a ResNet50 plus Bagging & Data Augmentation to get Top-1 accuracy of 62.5%.
Training a ResNet50 using presizing I was able to get to around 67% accuracy, and a good part of the remaining confusion between images may be coming from the blurriness of the boundaries of the art categories themselves: (E.g., Fauvism & Expressionism / Post-Impressionism, Impressionism and Post-Impressionism)
It would be really nice to be able to go a little deeper into which paintings are getting categorized to an art movement different from the WikiArt label: is there a way to output to csv the image names with predicted categories?
Training was interesting - on my RTX 2070 I was getting 14 minutes/epoch, with a batch size of 64 and using mixed-precision. On Colab with a V100 it was more like 36 minutes/epoch. I was curious what the limiting factor was, and I thought it might be CPU doing the image resizing - some images were as large as 3000x4000, and in my DataBlock item_tfms I’m resizing to 512px.
So per the fastai performance suggestions I switched out Pillow to Pillow-SIMD and libjpeg to libjpeg-turbo, and I also resized the WikiArt dataset to a largest-size resolution of 512px. This left my CPU cores no longer completely maxed out during training, and my training time was cut in half, down to about 6 min/epoch locally.
The GPU gods also blessed me on Colab with an A100, which allowed me to bump my batch size way up - epoch times were about 3min, and I was able to confirm that running with full precision didn’t improve accuracy.
I did get a 2% improvement in accuracy going from 224px to 256px in my batch_tfms size
I created a new HuggingFace Space to demo this model: and beyond the accuracy stats I’m pretty pleased with its top-3 as a reliable indicator of how much those styles are represented in the image independent of its historical association with an art movement:
Like Matisse’s "Portrait of Madame Matisse (1905) is correctly categorized as Fauvism, but also as Post-Impressionist + Expressionist, which fits:

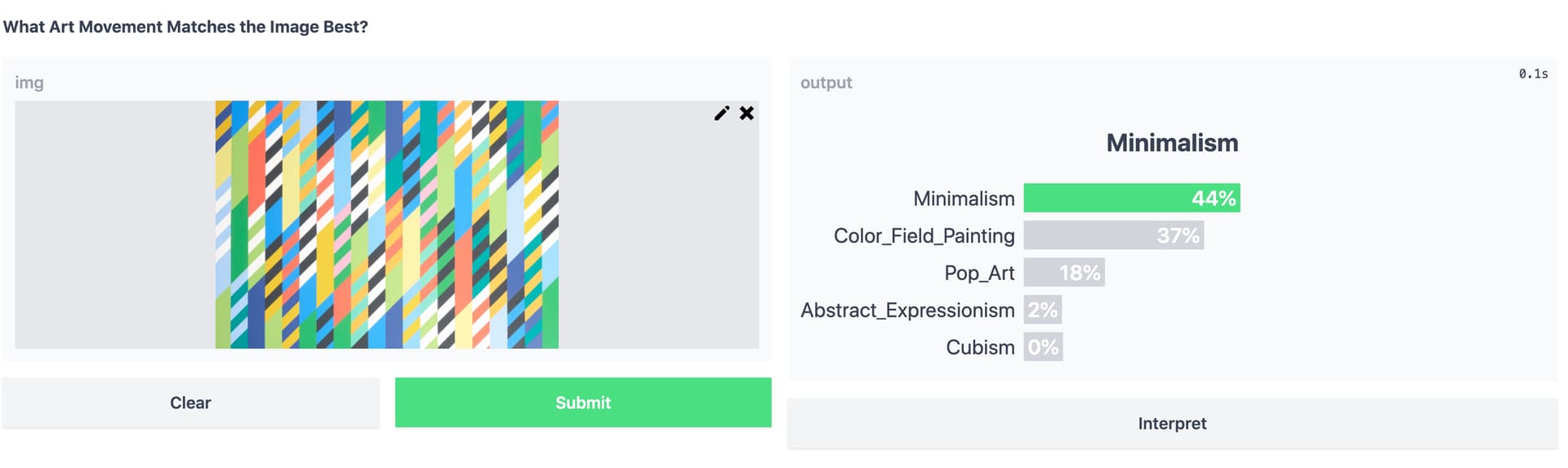
Bridget Riley’s work is prototypical Op-Art, which wasn’t included as a category in training, and for this painting I get Minimalism > Color Field > Pop-Art > Abstract Expressionism, which seems pretty reasonable to me
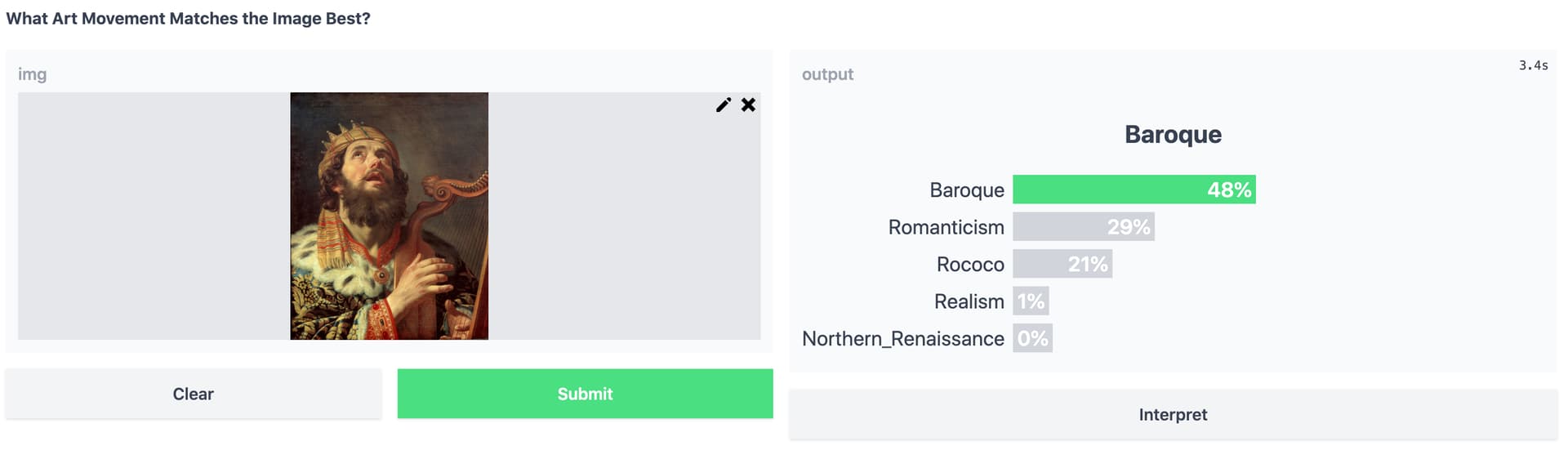
And Jan de Bray’s David Playing the Harp (1670), is Baroque / Dutch Golden Age, which is matched by the top-1, and Romanticism + Rococo as runners-up makes sense.
Going forward there’s some interesting recent work around the WikiArt dataset, like Artemis: Affective Language for Visual Art, which includes a dataset of 439K emotion attributions and explanations from humans, on these same 81K artworks from WikiArt.
They trained and demonstrated a series of captioning systems capable of expressing and explaining emotions from visual stimuli which is really cool, I’d be curious to see if I could even just use their model in a JavaScript API endpoint integration like Jeremy demoed at the end of Lecture 2 to augment my visual classifier with an emotionally descriptive caption.
If you’re familiar with BatBot’s image captioning on the EleutherAI Discord, this seems very similar but I believe BatBot uses Clip + Personality captioning. Would be very cool to combine BatBot with Artemis, and maybe some question answering or something with a LLM, will have to investigate further. Any ideas or suggestions are super welcome!
25 Likes