Thank you! Sharing the dataset here: with_or_without_helmet - Google Drive
Just finished the 1st lesson. I am very excited about the course. Here is my first go at building a model: https://www.kaggle.com/code/jasondwilson/identify-vehicle-type
I would like to know why I can’t Image.to_thumb to work in a code block in kaggle. Anybody able to help
# run the model against some images
import os;
errors = []
files = os.listdir('/kaggle/working')
for x in files:
try:
vehicle,_,probs = learn.predict(PILImage.create(x))
print(f'Testing: {x}')
print(f"This is a: {vehicle} [confidence: {(max(probs) * 100):.2f}%].")
img = Image.open(x)
img.to_thumb(128,128) ### Doesn't seem to work in a code block
except:
errors.append(x)
errors
I created a goodreads recommendation system based on the last lesson of this course. It made pretty accurate insights on the dataset.
Interesting outcome. Chapter 1 Notebook!
I wanted to know if the photo was of a person or not. I searched for photos of cars and people.
The solution works well for identifying cars and has zero probability of identifying a person.
Link: Is it a person? Create a model from your own data | Kaggle
Can anyone identify the problem in my solution?
Hello guys,
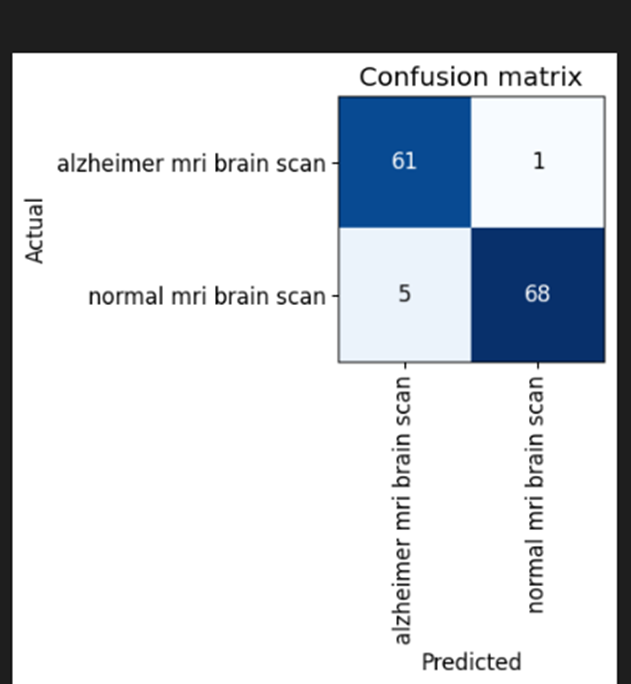
I just wanted to share my results of lesson 2 combined with Bing’s image search code from lesson 1. I’ve download brain MRI scans from Bing search and did try to differentiate between regular and Alzheimer’s MRI brain scans.
Given the small dataset, the results were not perfect and are naive, but maybe you can give me a few hints on how to get a better dataset. As I go along with the course, one of my end goal projects would be to improve accuracy or predict the likelihood of developing Alzheimer’s brain MRI changes.
Below are the results. Is it normal error_rate increase with more epochs or my data is flawed? Oddly enough I got a better results with ‘resnet34’ vs ‘vit_tiny_patch16_224’ - 0.0444.
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.606041 | 0.334426 | 0.127660 | 01:17 |
| 1 | 0.458656 | 0.134005 | 0.031915 | 01:08 |
| 2 | 0.357130 | 0.179682 | 0.042553 | 01:08 |
| 3 | 0.304873 | 0.159277 | 0.063830 | 01:09 |
| 4 | 0.276970 | 0.164375 | 0.085106 | 01:09 |
2 Likes
Thank you @suvash for sharing this notebook and demo, really interesting. I have a quick question, for example, if the dataset is not in the format you have right now rather you have a folder where each sub-folder is labelled and within that folder are images. Do you know how would you upload this local folder on a machine and do multi-classification? Or let me know if the Fastai course will cover it later. Thanks
1 Like
Hi @JuanHaunted thank you for sharing this. I am curious why you did not use “multi-category” block in data loaders and used a simple “category” block. Wouldn’t your problem be multi-class? Thank you
Hi,
As an Environmental Engineering graduate, sorting different types of solid waste felt like a good place to start. So after completing lesson 1 that’s what I did. I categorized 5 types of wastes that are commonly found in dumpster: organic waste, electronic waste, paper and cardboard waste, glass waste, and metalic waste. Do let me know if I can improve anywhere!
1 Like
Hi @mab.fayyaz I think multi-category is for images with objects more than one categories, or none. Thje name confused me too but reading this clarified.
1 Like
Hello Everyone,
So this is my project based on lesson 2 of the course which focused more on production softwares, so I tried creating the project from scratch and deployed it in the similar manner.
Project Details: Bird Classifier
The Project is made using Fastai module and I have used the ResNet50 Architecture in the Project and fine tuned it for 5 epochs resulting in the app deployed on HuggingFace Spaces.
Project Link:Bird Classifier
Thanks for asking. The course and docs will definitely cover more builtin as well as custom ways to load your data. I can also recommend the datablock tutorial if you’re interested right away, but there’s no rush either if you’re progressing with the course.
1 Like
Started the fast.ai course this week, created a small project on HF: Painters - a Hugging Face Space by viktor-kertanov.
Base on a given picture it defines who’s the author of a painting. Currently there are only 5 impressionists painters: Cezanne, Pissarro, Van Gogh, Monet, Renoir. The data was collected from artsy.com, <~ 200 works from each artist.
Accuracy of the model is ~ 85%, which seems not that bad. As a side bonus, found out that there are a lot of museums (like MET) that have an open API with all their collection, which sounds intriguing.
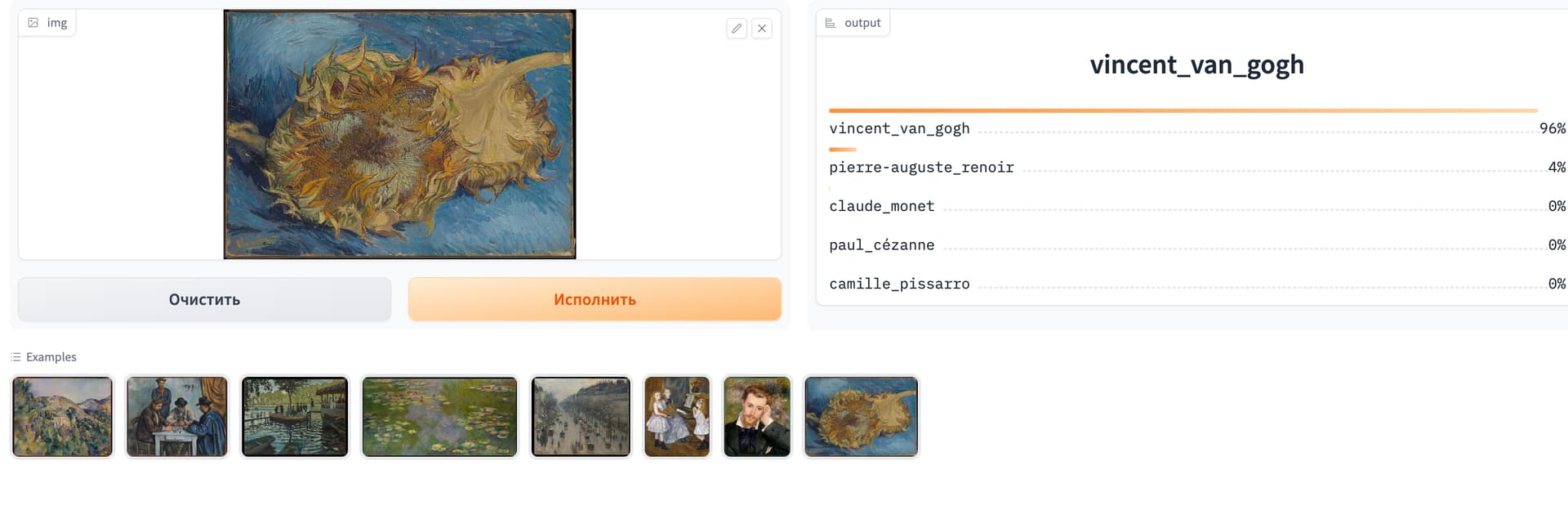
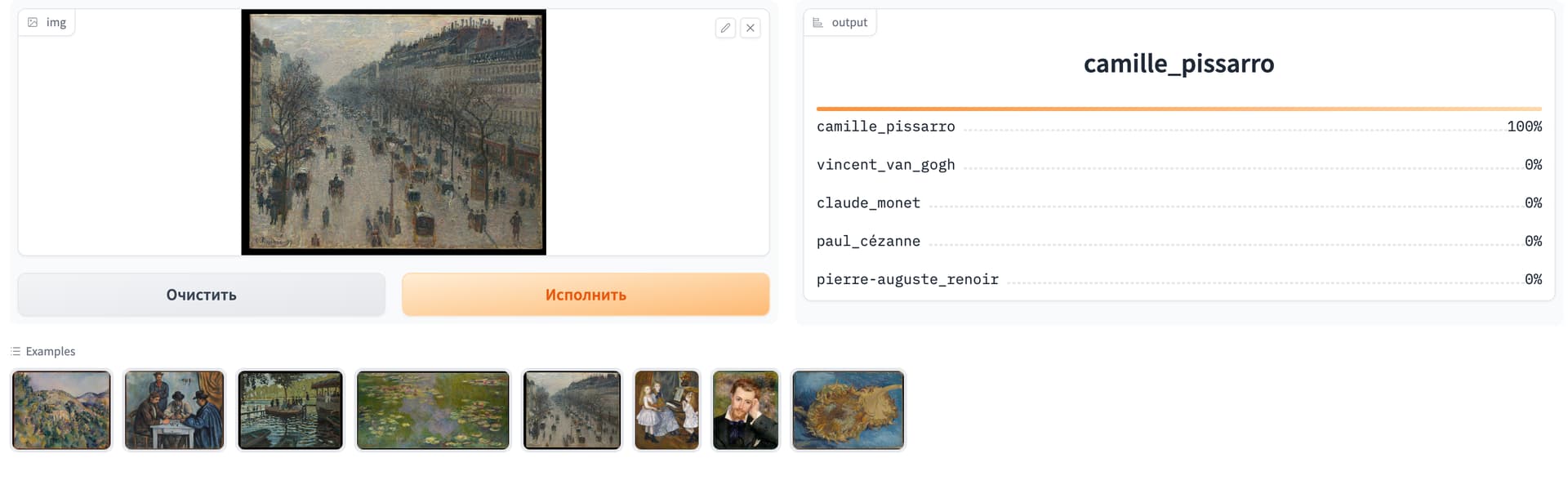
2 Likes
Great thanks for your organization and design of this amazing course. After finishing Lesson 1, I started to think about possible interesting image classification questions. One day when I was going grocery shopping with my fiancee, she mentioned to me that we should buy some zucchini for our vegetable, which can be easily cooked using a conventional oven. Then I asked, “Isn’t it a cucumber?”. She said “Nope, look at the label, it is zucchini.” This is how I find zucchini looks very similar to cucumber, which motivates me to simply use what I learned in Lesson 1 to build a zucchini-cucumber classifier.
Here are some screenshots of this toy classifier (just for fun and just in case there are some cucumbers mixed into the zucchini):

I think one interesting takeaway here is that data quality is really important. We need to create some variations for each category to let the model learn different scenarios. For instance, I put “table” and “cut” as additional strings to download photos of vegetables in different statuses.

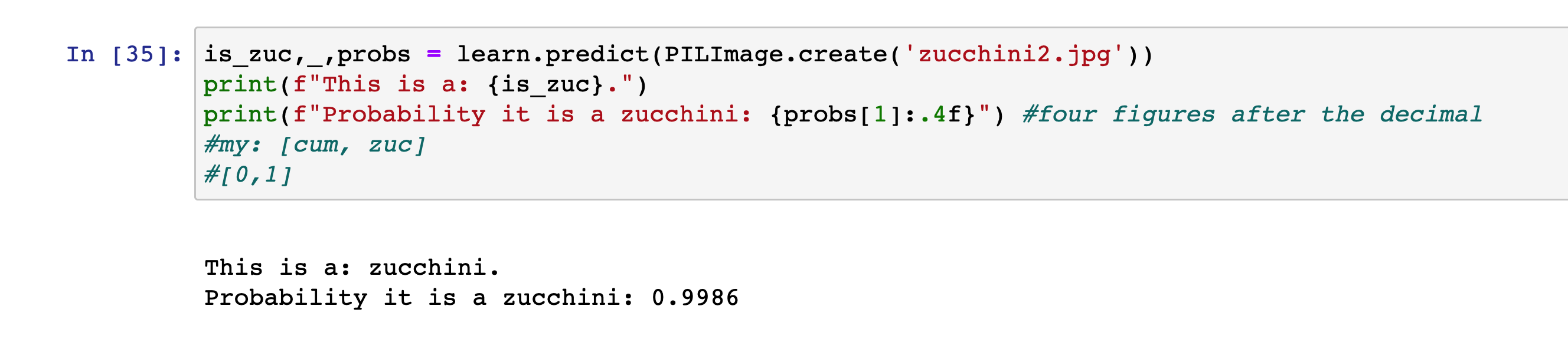
I treat this procedure as a way to understand the end-to-end process. I may further think about how to put a model into production (or a more interactive way with a more dynamic online environment to interact with real-world data) in future lessons (e.g. Lesson 2).
2 Likes
after lesson 1 video, I tried classifying types of basketball shots. Here is the notebook. I’m curious if the third thing I found interesting is common.

Things I found interesting were…
- Changing search from “layup” and “dunk” to “basketball layup” and “basketball dunk” improved error rate from 21% to 9%
- predicting basketball layup, basketball dunk, or basketball threepointer gets 26% error rate when searching for 100 images of each one
- Increasing the number of searched images from 100 to 200 images actually increased error rate from 26% to 36%.
3 Likes
I’ve published it as a Gradio space on HuggingFace, feel free to check it out! ;D
I just published a fastai baseline for an ongoing kaggle competition. And it’s still 4 weeks to go, if you want to play along. ![]()
2 Likes
Thank you for your response on this. I will have a read into it.
thank you @suvash for clarifying.
I had the same experience had been using fastai for a while but hadn’t redone the course when I did I was so amazed at how the library has progressed.
