I’m happy with my process so far - it performs well on my training data, however I must say it doesn’t seem to do great when I deploy it to Hugging Face. I suspect that even with data augmentation, the 10-15 examples I generated for each character is just not enough. In any case I’m sharing it now and may revisit it later after working through some more lessons - I’d like to learn a more methodical way to evaluate my model before spending time trying lots of different ideas. In any case you can still try it here.
It’s been fun to see how the model fails. Toki Pona has ~120-150 characters that are often quite similar, or have one character completely represented inside another, or identical except for rotation, etc. Enjoy!
Adapting Jeremy’s notebook already got near-perfect results. Even tiny segments of the images are sometimes enough to show where they came from – I cropped random 20x20px pieces, trained a learner on those, and the error rate was 16%.
That said – the images are just from duckduckgo, and are messier than the bird example. e.g. some ‘midjourney’ images are screenshots of the discord channel, and I’m not convinced the learner isn’t cheating on things like that. Plus some images have become famous (avocado armchairs?), and I’m not sure they aren’t showing up multiple times in the results.
Things I’m considering doing next:
looking more into the color palettes used by the diffusion models. It looks a lot like midjourney and especially DALL-E are prone to certain colors – can you show that on a color histogram? Or from an AI approach – if I threw away the shape of the image and just treated it as a bag of pixels, would that be enough to identify what created an image?
training a GAN to make images from one source look like they come from another source. could I take a stable diffusion image and midjourney-ify it?
finding a cleaner source of images, and seeing if the classifier still works on them
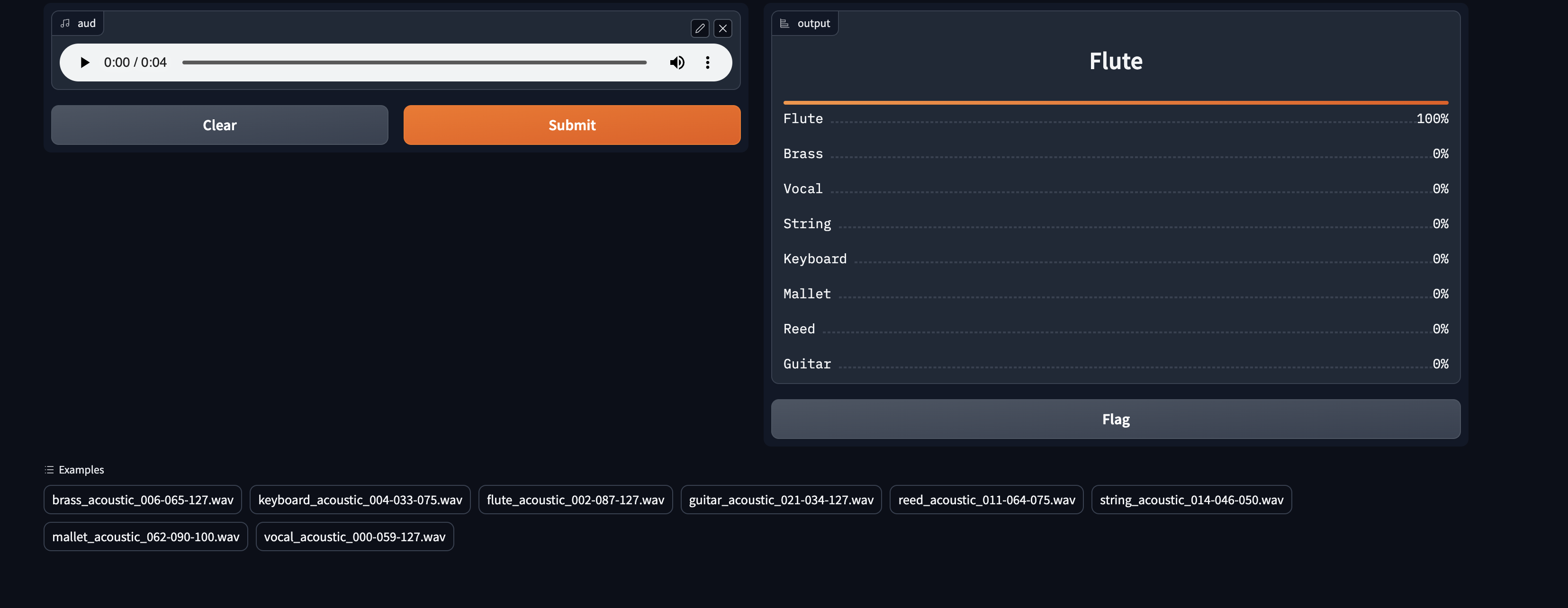
I’ve always been fascinated by the intersection of both music and technology and I’ve been meaning to work in this field as for some time. I tried to replicate jhartquist 's model on the nsynth dataset and built an app where you can input an audio file and it tells you which instrument it is. This is a hacky version of something I want to build for more nuanced sounds. Will keep you posted on the main project soon!
Completed the first lesson, and the chapter 1 from the book. Got inspired by the different ideas and approaches other people came up with to apply in machine learning, specifically the sound transformation into image for recognition.
Reading the comments, saw @Mattr comment on a wonderfully simple yet appealing idea of recognising damaged vehicles from normal.
Thought, why not use the same idea on delivery parcels.
It works really great and takes less than 5 minutes to run.
Added a predict_image function to return rendering of the image and the prediction results from the file path string.
I have completed the first lesson of the course. And then decided to do the same thing with other things. So, created Boot or Sneaker classifier taking the is_bird notebook as a reference. Used images of boots and sneakers to train the model. Accuracy was not 100% though unlike the is_bird classifier, but still it’s quite impressive. In the process of project creation, got more clarity of the first lesson of the course.
Completed lesson 1 of Practical Deep Learning, and I tweaked the “is it a bird” note book to “Butterflies vs Moths” notebook to check if the image is of a butterfly or a moth!
Completed lesson 2 of Practical Deep Learning, and I have hosted my model on HuggingFace spaces and created a simple website on Replit which uses the HF space via an API!
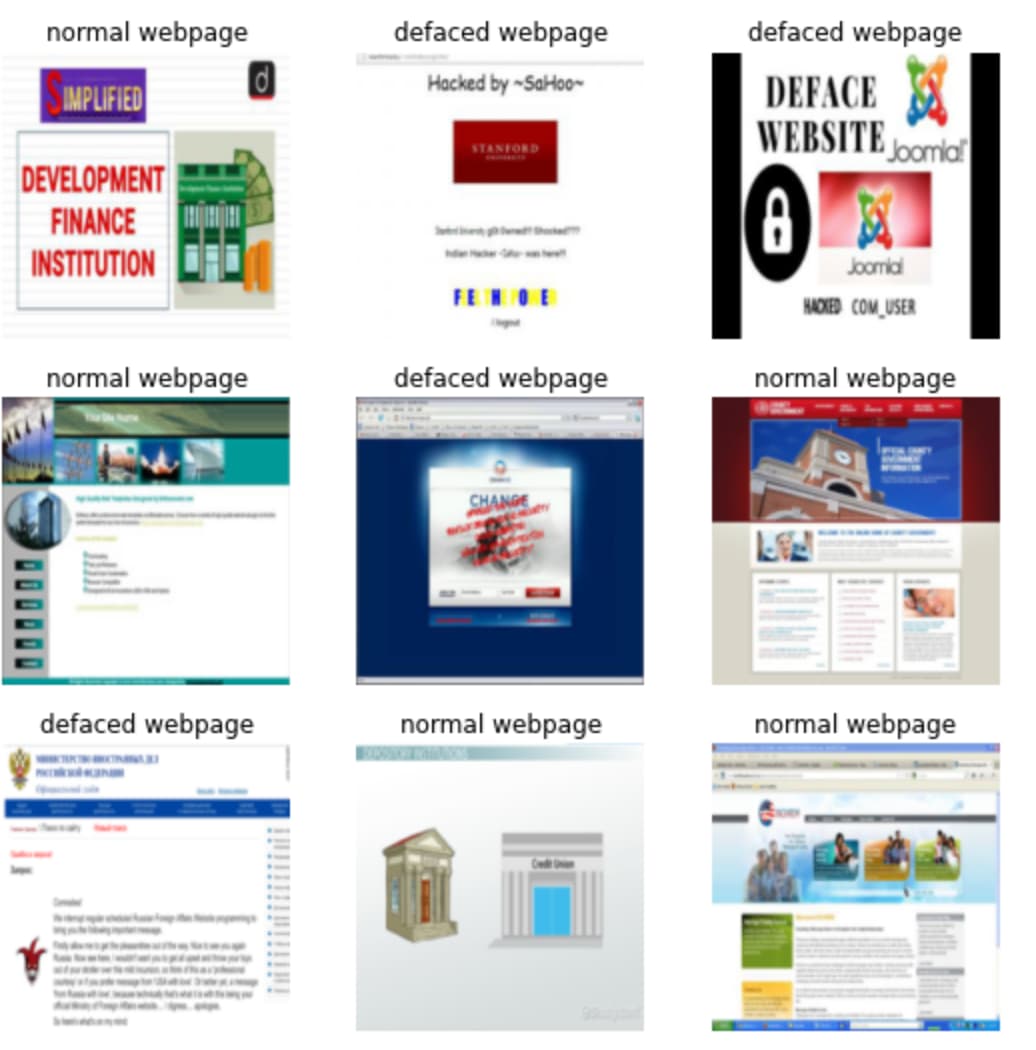
I made a simple classifier to detect web defacement. Right now it’s about 73% accuracy on validation set but I hope it will get better during the course I’ll keep improving the work.
After the first couple of lessons I had a go at building a classifier for my prescription medication, it was a great learning experience applying what I have learned so far.
I took this course some time ago (around october). Back then, I did not have a laptop. I was interested in the field of data science and decided to take the course nonetheless. I bought the laptop and with that came my finals, my senior thesis and work (that finally allowed me to buy a laptop). So, I took a break from programming and data science for some time. I decided to start from the stable diffusion course (since I had finished the part 1 before. I had a hard time understanding it. As I had focused on simply tabular machine learning from a non-fastai approach for quite some time.
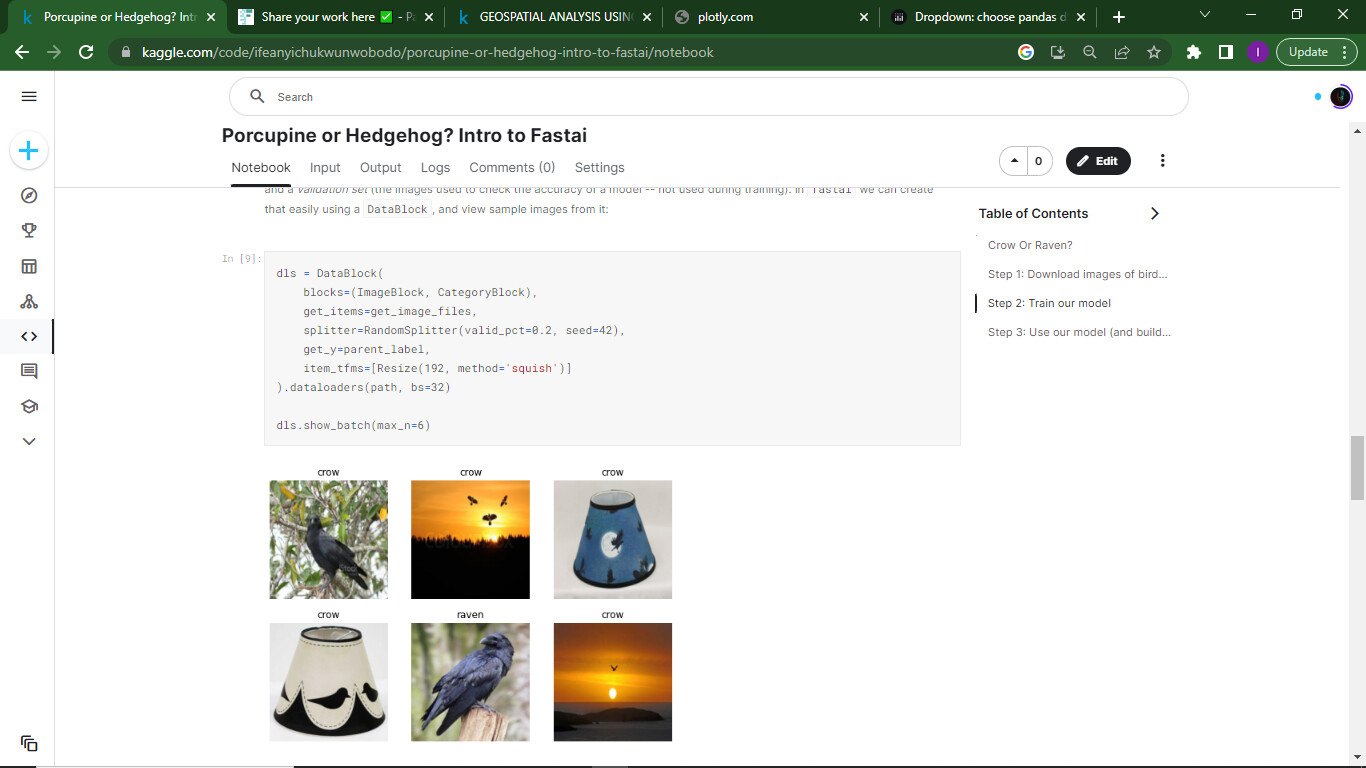
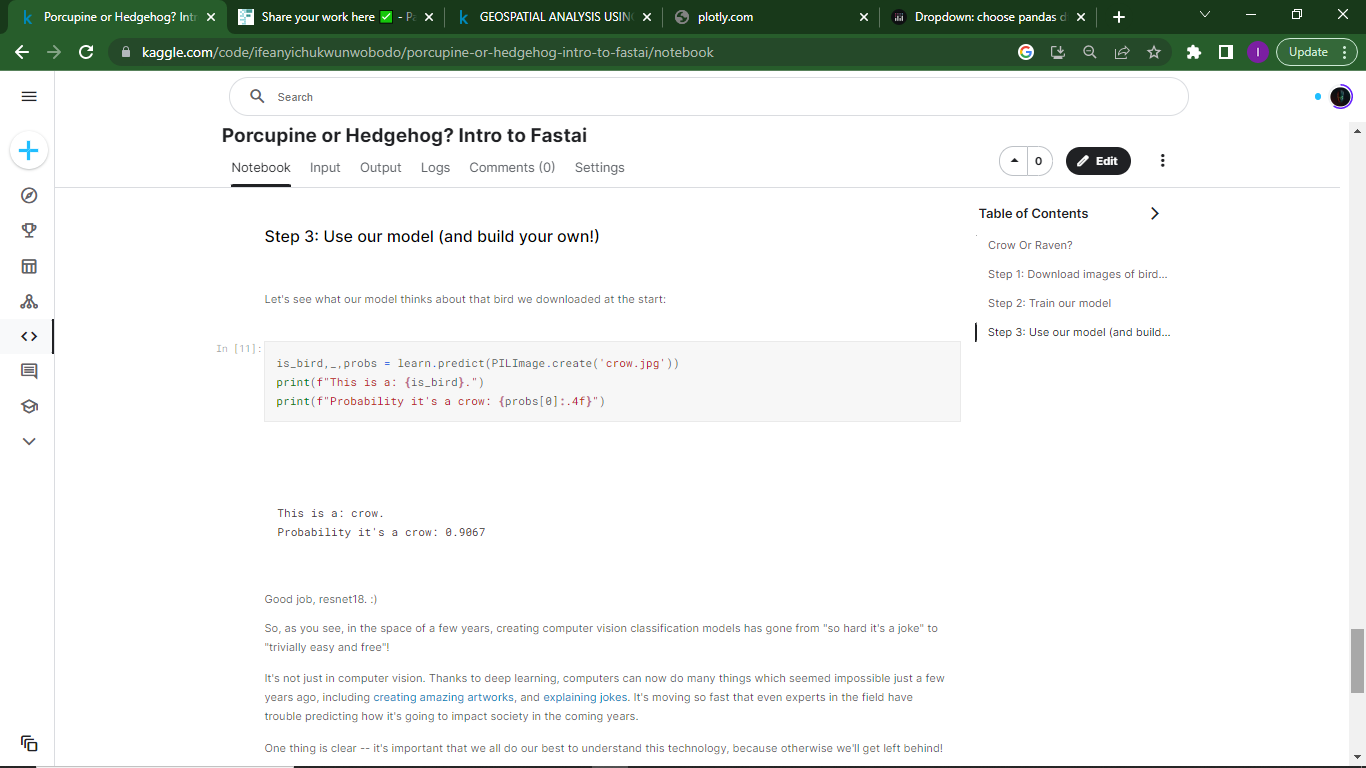
Now, I’ve decided to start from beginning and hopefully I will be able to go for the part 2 later on. With that I edited @jeremy original notebook from the first lesson and made raven/crow classifier.
Hi, I’m currently working on my bachelor’s thesis regarding dog breed identification using fastai. I’m in the final stages of both my thesis and my code, so I thought I might share my code here with you guys. Feel free to look and test the code. Comments and feedback is appreciated.
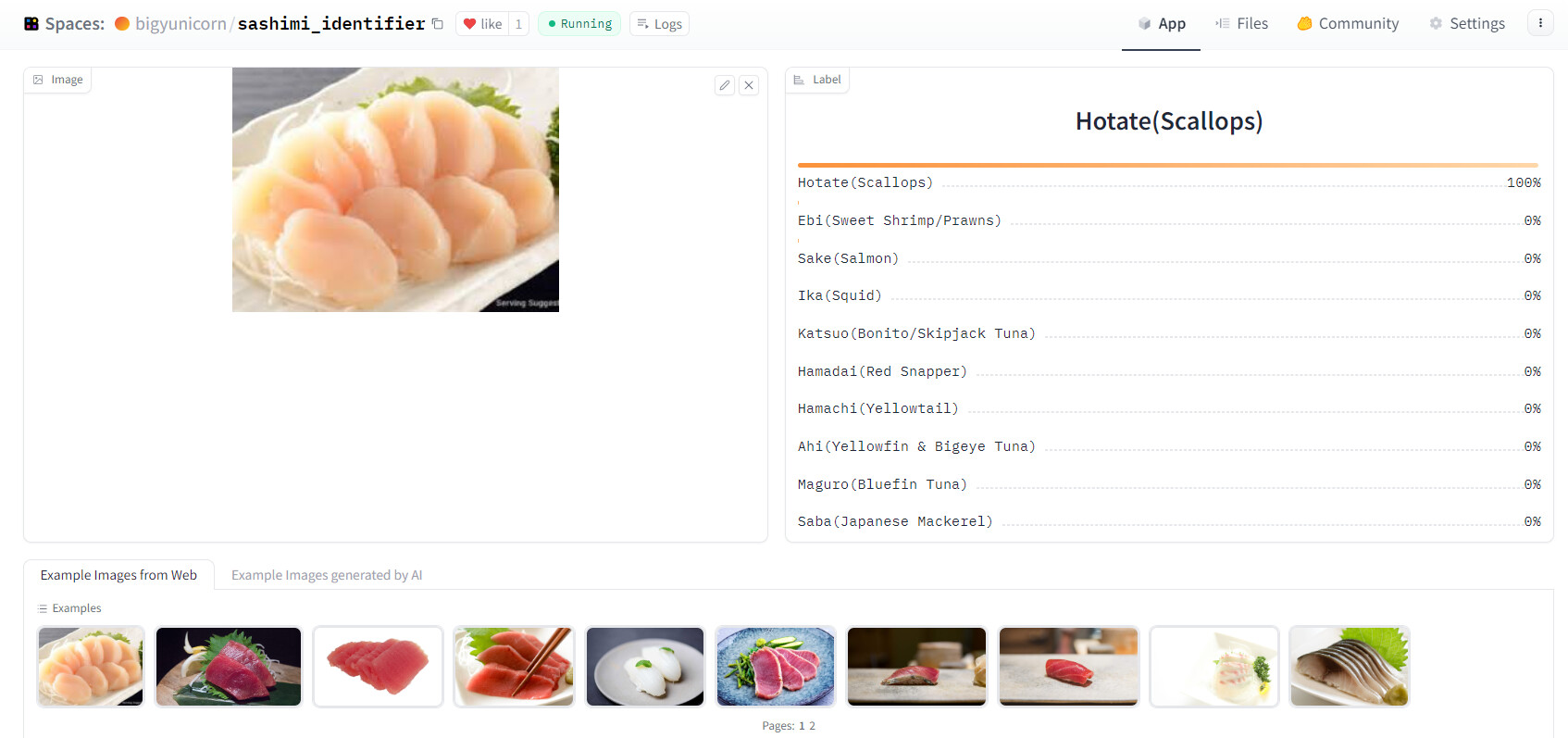
After taking the first two chapters, I created a sashimi identifier!
My husband grew up in Japan so he LOVES sashimi. Unlike him, I was never exposed to sushi/sashimi when I grew up so it was really challenging for me to learn all these amazing sashimi for a while.
So I thought it was a great opportunity for me to create an app that can identify different sashimi based on the image, and I hope it can serve anyone who wants to learn more about different type of sashimi in a more interactive way
Unlike dog & cat and other images I played with, the model had a bit higher end error rate (around 5%) for sashimi.
When I created the confusion matrix, the model was mostly confused with different types of tuna (which i can understand as it is super confusing to me too lol).
Ex:
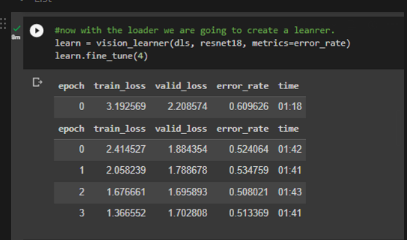
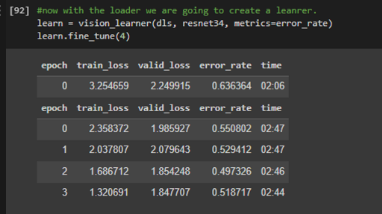
To decrease the error rate, I tried a deeper neural network (resnet34) and/or fine-tuned more, but interestingly the error rate was not significantly better. So I ended up sticking with resnet18 and fine-tuned about 4 times.
ex:
(1) resnet18, fine-tuned 4 times.
(2) resnet34, fine-tuned 4 times.
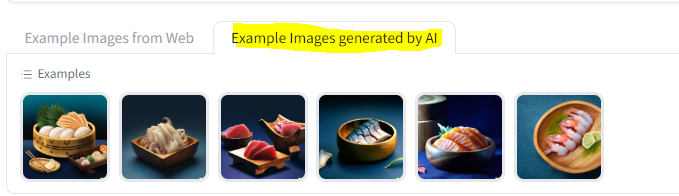
One interesting experiment I did for fun was using ai-generated sashimi images. I used both stable fusion and dalle-2 to create some sashimi images. I feel like my model recognizes the images a bit less accurately but still pretty good. I created a tab for AI-genearted sashimi images on my app so you can easily drag &drop them and play with them.
As I am learning more from the course, I am excited to learn how to improve the results!
Thanks @jeremy for this amazing course, and thank you, Fast ai community, for the support
woah @anthony this is so cool! Thanks for sharing the blog that explains your journey in depth - it was not only helpful but also fun to read. Keep up the good work and cannot wait to read your next post
Hey @Ifeanyi thanks for sharing your work and your story I am so glad you are back and giving it another shot - it is definitely encouraging for me and I am pretty sure it has the same effect on others who are starting this course. Can’t wait to see you other projects along the way!