thanks for the add to the huggingface study group! currently building a model to identify different running shoe types, will add it here as soon as i’m done ![]()
3 Likes
update: finished building my model (after spending about 5-6h on it)!
In the world of running, there are quite a number of running shoe types - as a volunteer coach, I constantly get questions as to which exact model of shoes to buy - because wearing the wrong types of shoes for different workouts could lead to injuries, or it might burn through the effective mileage of the shoe quicker (therefore needing a new replacement in a shorter time period). In reality, shoes can be classified into several major categories:
- “everyday” running shoes - regular workhorses that you can do most of your easy runs in
- tempo running shoes - shoes for quicker speeds, track workouts, but not to be used for racing
- racing running shoes - shoes that are used purely for racing and nothing else (to prolong livespan)
- stability / maximal cushion running shoes - shoes that are designed to ‘prevent injury’ [although such claims of whether injury is truly prevented are disputed]
So I built a running-shoe type classifier! You can find it it here, with the source code here
1 Like
A very humble customizable “Is a bird or not” exercise where the user can easily customize the image search keywords and number of epochs. Interesting to analyze how error rate changes using different search keywords.
https://www.kaggle.com/code/julio4ai/customizable-is-a-bird-or-not
Not sure about how the last part works, but apparently it does. I thought that the last line should be:
print(f"Probability it is a {keyword1}: {probs[0]:.4f}")
But that does not work as I expected, so I changed to:
print(f"Probability it is NOT a {keyword1}: {probs[0]:.4f}")
Maybe one of the most veteran mates can share some thoughts about it. Thanks in advance!
If you print probs you will see that it’s a size 2 tensor:
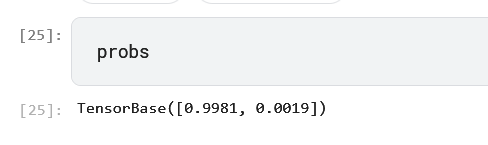
it means that the first value is the probability of the item being in the class 0 and the second value is the probability of it being in the class 1, that’s why if you pick probs[0] you will always have the probability of the item being class 0, but you should remove the “NOT” and use
print(f"Probability it is a {keyword1}: {probs[0]:.4f}")
I just ran your notebook and it works well
That was fast and clear. Many thanks, Kamui!
1 Like
sorry julio I got confused you should drop the “NOT” as probs[0] is the probability that the target is keyword1
so you should remove the “NOT”
1 Like
I got the point. Thanks again!
1 Like
Hello,
my name is frank, i’m from germany, and I realy like this awsome course.
To get an understanding of what happens during backpropagation i have created a small notebook - mainly to understand this delta rule better. I would be interested in feedback from the community - is this correct as I have outlined it or am I wrong here and there.
I made it in colab here is the link - you should open it in colab - in others it looks bad (I use a lot of tables).
then thank you already all who look at this
frank
3 Likes
Hello,
After reading chapter 1 and 2 of the book, I really liked the segmentation example (the one where the neural network has to predict if each pixel in the image is a road, a building, a car, a pedestrian…) so I decided to build a face feature detector.
That was complicated (see below why), but I am really happy with the results.
It can detect the nose, eyes, eyebrows, hair, beard, sunglasses, lips, teeth, ears and the skin.

80% of the work was:
- Cleaning the data (bad folder names, folder merges on image side but not on label side, images without labels, labels without images)
- Figuring out what fastai needs as “codes” parameter when using segmentation (couldn’t find it in the api documentation). After doing this it seems obvious it’s the list of features we want to detect, but having no idea how many there were, and being a total newbie, it was a hurdle to me.
- Figuring out what is the right image format for labels. The label images from the dataset weren’t accepted by fastai because there is yellow, red, etc… but labels must be images having only very dark sides of grey (black): it must be rgb(0,0,0) for feature 0, rgb(1,1,1) for feature 1, etc… And match “codes”. Couldn’t find it in the api documentation so I spent a lot of time figuring this out and converting all the label images from the dataset into that format, by modifying each pixel of each label image using a python script. But I did succeed!
I used this dataset
I really love this course.
Thank you Jeremy and Sylvain!
10 Likes
Good job.
Henry Higgins, in George Bernard Shaw’s Pygmalion, claimed he could locate a Londoner’s address within two streets simply by way of speech patterns.
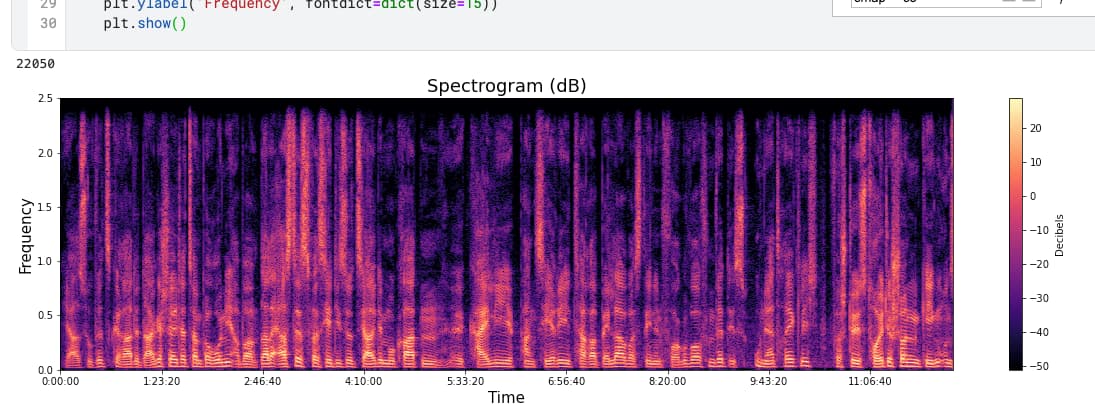
Using a custom dataset scraped from hundreds of audio files, I modified the “is it a bird” notebook (with much additional help from a variety of other blogs and stackoverflow comments) to answer the following question – can a machine learning visual-recognition algorithm differentiate spectrograms of Swedish and German speakers?
A project like this would be of great value to a company that already has thousands of “this call may be recorded for training purposes…” messages in a database, and would like to determine as much as possible (subject to prevailing privacy legislation) about a caller even before he or she fills out a form.
The short answer is that the program does pretty well – around 85% accuracy given a dataset of about 150 distinct 10-second .wav files from each language. Am I certain of this? No, there could be flaws in the design of the dataset as noted in the notebook, but this seems a good start. I have highlighted some takeaways that might be beneficial to others attempting a similar project (e.g., use a MELspectrogram instead of the plain vanilla variety).
Here is my Swedish/German classifier notebook. I have made the dataset public, so if there are problems accessing it with your own ID and Kaggle key, let me know.
7 Likes
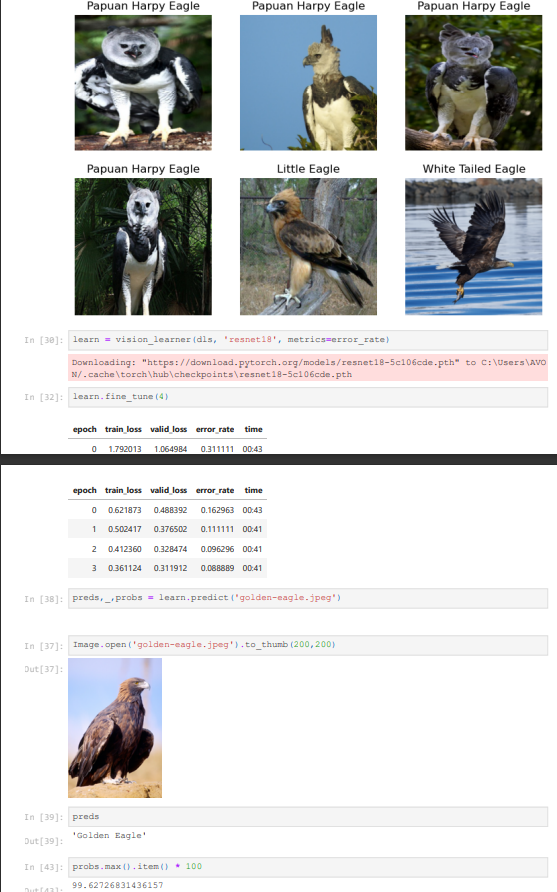
**Made my first classifier after Lesson 1 **
It classifies between 4 different types of eagle (Golden Eagle, Little Eagle,White Tailed Eagle, Papuan Harpy Eagle)
4 Likes
Hey everybody! I just took the first lesson of the Practical Deep Learning course and really enjoyed it. I created an image classifier to differentiate between pictures of cilantro and pictures of parsley (which I personally think look super similar) and was really surprised to see how amazing the pre-trained model and the fast.ai library are! It was able to predict with a cilantro picture with 99.37% accuracy! Here is a link to my Kaggle notebook.
4 Likes
Hi Dan, I think the kaggle notebook is still private, I just see a 404 error page.
But can see the dataset thanks ![]()
Thank you Allen – it should be publicly visible now (and the linked notebook correctly references the larger second-pass dataset with 150 samples of German and Swedish that gave me better results). I will also note that the dataset contains the raw (mono) .wav files, so anyone has the option of using some other conversion routine (e.g., PCA analysis and/or some other type of frequency decomposition) to see if that works better. I’ll probably do that myself at some point.
Also as noted earlier, please be aware that many of the samples came from the same series of nightly news or interview programs (a list of credits is attached to the dataset). Even though I tried to ensure that all the voices are from different individuals as opposed to random 10-second snippets taken from a given broadcast (which would have resulted in a few recognizable news hosts and reporters being listed multiple times) it is possible that Swedish national services and German national services each prefer to rely on a distinct set of locally manufactured mics and/or other recording gear that adds a recognizable sonic footprint to the voices. If so, the algorithm might simply be picking up on that, as opposed to the actual phonetic quirks and lilts that most humans (at least those speaking linguistically similar languages) recognize as characteristically German and Swedish. (It could also be zeroing in on just a few distinct words specific to one language – e.g. “Bund” – or different pronunciations of hot-button words like Ukraine or COVID that were likely referenced in several snippets, even though I tried to diversify the discussion topics.) In other words, the results would in that case be spurious.
2 Likes
I just finished the assignment for chapter 3 (classifying all digits)
https://www.kaggle.com/code/maxwe000/fastai-digit-classifier-assignment-all-digits
I managed to implement everything on my own, only using Pytorch for the loss function and the gradients. The neural network I implemented is having some problems, but the rest is working fine!
I will continue with the course for now and return to some open questions later. I’m just happy that I finished it and that I did it with my own code, with as little Pytorch as necessary! It was a real learning experience.
If someone has some insights / feedback, I’d be glad to hear!
2 Likes
Going through the course now, and made this Geese vs Mallards classifier. Nothing serious, but it was fun doing it.
2 Likes
Utilizing historical maps in identification of long-term land use changes was accepted for publication in Ambio last week. fastai was used to train an U-net to segment land use and land cover classes from historical printed maps, and the results were first converted to GIS data (either polygons or lines) and then used to evaluate the changes between 1965 and 2022.
U-net was used mostly because of the class Mire which is marked with horizontal lines. While most of the other classes could be detected with simpler methods such as color thresholding, U-net was able to ignore most of the non-relevant markings, such as text, overlaid on these classes.
Edit: Paper out: Utilizing historical maps in identification of long-term land use and land cover changes | SpringerLink
1 Like
Image to Image augmented t-shirts.

This was a project I made back in 2020 following decrappify techniques: https://github.com/aarcosg/fastai-course-v3-notes/blob/master/refactored_by_topics/CNN_L7_gan_feature-loss.md
Here’s a link to a blog post I made explaining all the details of it: Image-to-Image T-Shirts (2020) | Blog
3 Likes