Thanks, privacy settings updated ![]()
Thanks, this is great Abdullah, keep going.
Thanks Abdullah
I’ve just completed lesson 1 of the course and in the spirit of training a vision model before moving on to the next lesson I tried something different and fun.
There is a proverb - “Don’t judge a book by its cover”. I thought it’d be cool to see if we can use data to validate the literal meaning of this proverb so I found a dataset on kaggle which contains book cover images as well as title and the category.
As expected the model did much better than a random chance with just the book cover images but still way worse to be useful i.e random chance had a probability of being correct at 3.3% while the model was ~24%.
I’ve only looked at top-1 accuracy and will be exploring Top-3,5 accuracy to see if the results improve
significantly.
Next I tried to train a naive bayes model on Book titles only and it gave an accuracy of ~30%. So we can already see that textual information is better than just using the book images i.e content matters.
To summarise - the proverb stands corrected in this instance.
I’m creating a few datasets to explore some ideas on text in images -
- Can a CNN learn to understand text directly from images (without using 1-d conversation-nets)? e.g create a dataset of random page images of different categories(mystery, romance, comedy etc) of books and see if CNNs can actually learn something here. Since the page images will look very similar, the only way the model can do well is to read the text and understand the key words to make informed predictions.
- Include both the book cover image and title to make a prediction.
Here’s the link to the Kaggle notebook -
Note : I can run the notebook just fine but when using save and run all I keep getting assertion error.
Hello All,
I’ve completed the first 3 video lectures and read chapter 4 of the book. Before continuing I wanted to at least publish something to solidify my knowledge.
I have an interest in the stock market and wanted to create some sort of visual learner which lead to me training a model on candlestick charts.
The data is downloaded from polygon IO and is saved into hourly charts for every day. Each chart is placed into an “up” or “down” folder based on the next days closing price. If the next day closes higher than the charts price it is placed in up, and if the opposite happens it is placed in “down”.
Here is a link to a working Kaggle notebook that has graphs already created but also contains the code for fetching the data. The error rate is really high at 50% which means that it’s pretty much a coin flip for guessing the next days closing price. There is also a really high bias for up as well it seems since that is where most of the error comes from.
Let me know if you have any questions or comments. Thanks!
1 Like
My app identifies Film Stars that look like photos that you upload. Apparently Jeremy looks like Geoffrey Rush. I wrote a blog about it here. Eddy goes to Hollywood – Science4Performance
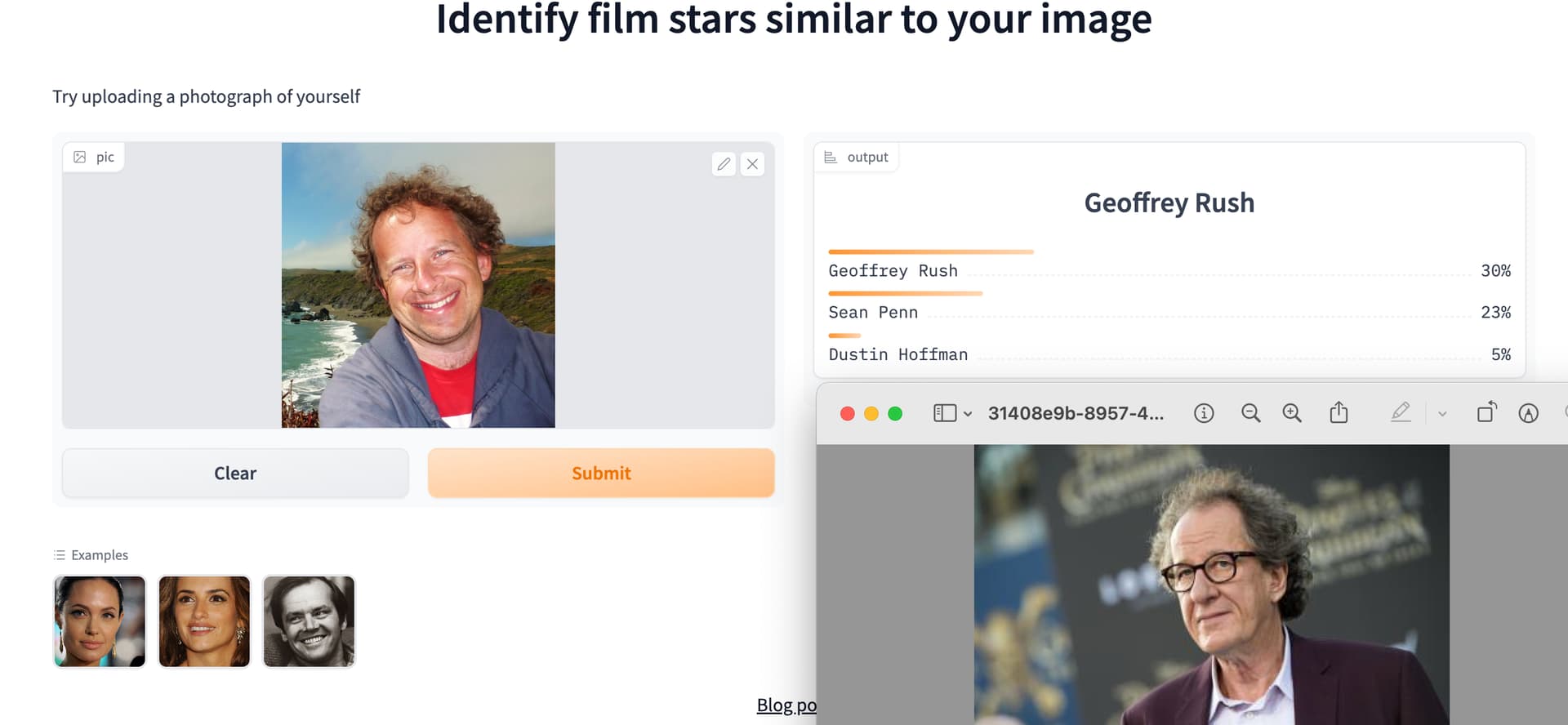
9 Likes
Rather than code a process toward tuning a model for specific object classification, this book may be used for classifying objects that are a subset of a particular base type.
Example of objects that are a subset of a particular base type could be [black cow, white cow, purple cow] or [sail boat, power boat, sunk boat] or [oak tree, pine tree, willow tree], etc…
The premise is that there is a ‘base’ type and its ‘sub’ types are identifiable:
Basic: {concrete noun: [attributive adjectives]}
Advanced: {abstract noun: [attributive adjectives]}
This notebook includes brief explanation on the ImageClassifierCleaner() and jmd_imagescraper.imagecleaner.
1 Like
Wow, I did not expect this to work as well as it did!
For my lesson 1 project I built a classifier that does not just distinguish images of car types, but very similar cars… Ferraris vs Lamborghinis!
For lesson 1 I had gotten good results building a classifier for cars vs trucks so I decided to ramp it up a notch and see if a model could distinguish between my 2 favorite sports car brands… I’m a car nut so doing so is easy for me, but most of my friends would stand no chance at beating the model in this test!
After 10 training epochs it was able to reach a error_rate of .07 on the validation set. That is so impressive to me given that the images it has to work with are seemingly, extremely similar. I wonder what characteristics of the car enabled the model to recognize the difference? Most Ferraris are red, so maybe that helps. Lamborghinis tend to be more pointy and angular looking, so perhaps that plays a role?
Anyway, check out the notebook here to see for yourself!
(also, I enabled a p100 GPU and set the number of epochs to 9 in order to improve the results a little more after toying around for a while)
3 Likes
Hello everyone, I completed lesson 4 and it was amazing. Worked through the lecture notebooks and definitely learnt a ton.
Some of my learnings apart from the course materials:
-
Consistent daily effort is the most important stuff. I read a post which mentioned Jeremy saying that we should always try to focus on daily efforts and try to make incremental progress. I appreciate this much more now.
-
Things can be solved, we just need to give it time and fresh perspective. I got stuck many times and this is the point where I could have given up but just staying on a problem for little longer solved it. This is an age old truth but I understand it much more now.
-
Projects or learning anything requires time. Some can be finished in a day and some take months. We just need to believe. Even if a project fails at the end, we get a ton of learnings everytime.
These are some things which I want to keep in mind through out. Please feel free to let me know if you have had similar experience.
Coming to my work: I applied the learnings from Lesson 4 on classifying stack overflow question in 3 categories based on the quality here. I have tried to incorporate learnings from iterate like a grandmaster and getting started with nlp for absolute beginners . This needs a lot of improvement. Please feel free to go through this notebook and suggest areas of improvement or further analysis. I plan to make a post on this after incorporating any improvements any of you might suggest.
6 Likes
Hello everyone,
I just completed Lesson 1. Here’s my notebook: Identifying Deciduous Trees in Virginia | Kaggle
I tried my hand at a classifier that identifies 10 different deciduous trees in Virginia from their leaves. First I attempted this from DuckDuckGo images, just like in the lesson 1 example. Then I tried with a mixed dataset: half DDG images, half from the UCI Machine Learning Repository (“Plants Data Set”). The accuracy rate on the first attempt is about 60% and the accuracy rate on the second is about 70%. So nothing amazing, but about as well as I can do with identifying the trees after a few hours of studying a plant identification guidebook!
If anyone is a complete beginner to all this like me, they might find it interesting to check out my notebook. Along the way, I ask lots of questions about stuff another complete beginner might also be thinking about. Thanks Jeremy and the fastai team for this course! So exciting to learn about.
2 Likes
Given that C# is my daily drive I created a C# version of the baseline digit classifier from lesson 3 (Chapter 4 of the book)
This is just the non-neural net averaged ideal image version.
Observation: So many loops - broadcasting in PyTorch is a way better approach
Next up I plan to attempt writing a neural net from scratch in C# also.
I will ultimately move over to PyTorch, but this just helps me build the mental models.
Thought maybe this might help someone else too.
1 Like
Might be interesting to try a version with GitHub - dotnet/TorchSharp: A .NET library that provides access to the library that powers PyTorch.
1 Like
Thanks Allen, I’ve never come across that, will have a look
1 Like
Hi everyone,
While the steps Jeremy notes in lesson 2 for deploying a deep learning model app on Binder are correct, I just wanted to note that in order for me to get things working properly, I had to include a requirements.txt file in the GitHub repo.
My GitHub repo which works as of Jan 19, 2023 can be found here for anyone who might be struggling getting their app deployed.
Enjoy!
1 Like
He’s actually my favourite actor ![]()
1 Like
Made two from the first lesson:
-
to show safe vs unsafe bike infrastructure
https://www.kaggle.com/teddyosito/is-it-safe-bike-infrastructure -
Identify whether the sidewalk is good, broken or missing
[URL from above]/good-bad-or-missing-sidewalks
1 Like
Hi. I finished Lesson 1 today and for the first assignment I modified the bird classifier to distinguish between rats and mice. It works well, though I had to use “animal mouse” as a search term to avoid images of computer peripherals. Have I cheated? Is tweaking search terms a normal thing in order to get better data?
As a follow on effort, I tried adding a class for gerbels. This was unsuccessful, with poorer results for images known to be gerbels. I tried adding “side” and “front” to the search terms in order to get a variety of perspectives but no luck. What would be a suggested next step in order to get a better result? Apparently the primary characteristic of gerbels vs. mice is hair on the tails.
SC
1 Like
Hi! I just finished the first lesson of the course. I’m loving it so far. First time using fastai 🫶🏽
My use case for this lesson was differentiating between Latin American cultures. They are so alike in many ways, yet they’re very unique. Many factors make them similar such as their pre-Columbian history, colonization by European cultures, Catholicism, and the mixture of cultural identities! So I wanted to see if we could use neural networks to catch their differences.
Here are my results Kaggle Notebook: What Latin American Culture is it? With Fast.ai. I downloaded images from 5 different LATAM countries, and use the code from the lesson.

The model didn’t do that well ![]() , but it was a great POC that we can use NN to differentiate something so alike as Latin American Cultures (I might experiment with other models in the future).
, but it was a great POC that we can use NN to differentiate something so alike as Latin American Cultures (I might experiment with other models in the future).


At the end of the notebook I tested my thought that dresses are one thing that is very hard to differentiate! Turns out I might be right ![]()
3 Likes
Hi,
It would be better if you created a new post on the forum instead of adding a reply here.
But here are my thoughts on your questions.
First, you have not cheated by using “animal mouse” as a search term. Actually it is a good thing that you did. Why? You will see later when you continue your lessons.
Second, I think gerbels look too similar to mice, and I cannot even tell the difference between the two. This may be too difficult for your model. I would suggest try something easier, like cat vs. mouse. If that doesn’t work either, then you probably made a mistake in your code.
Hopefully this helps.


