Fixed ![]()
2 Likes
I created a natty or not classifier. In the bodybuilding community there’s much debate over whether certain bodybuilders use steroids to augment their physiques, or are fully natural - it’s time to put this to rest.
Natty (natural) dataset search: “wnbf bodybuilder physique”. This is the all natural bodybuilding competition.
Not natty (on steroids) dataset search: “mr olympia physique”. This is the no rules bodybuilding competition, which Arnold Schwarzenegger famously won.
In the end, the prediction scores were actually not very confident, but the classification was looking okay. For example, one of my favorite fitness Youtubers Omar Isuf, was classified as natural, which he certainly is!
This is a: wnbf bodybuilder physique.
Probability it’s natty: 0.5695
Then there’s Kai Greene. He’s steroided out of his mind…clearly. And the model agrees
This is a: mr olympia physique.
Probability it’s natty: 0.3422
What was interesting, was that the model insisted that Arnold Schwarzenegger was natty. We know that Arnold is not natty however, because he admitted it himself.

This is a: wnbf bodybuilder physique.
Probability it’s natty: 0.9967
So clearly the model isn’t perfect - and maybe I didn’t quite put this issue to rest. But the line between natty or not isn’t so solid in reality, so one can’t expect the model to be completely accurate. If I were to go deeper on this, I’d make sure to include examples of in-competition and outside-competition photos for both natty and not natty bodybuilders, since competitive bodibuilders spray tan before competitions.
Alright that’s enough looking at bodybuilders. Thanks for reading!
6 Likes
Hello there !
As everyone I tried, after the first lesson, to find some interesting results (or not ^^).
I did the following 3 comparisons separatly :
- white man / white woman
- asian man / asian woman
- black man / black woman
So why this ? I didn’t have a precise hypothesis or anything, but I wanted to see if there would be some biais in the couple gender/ethnicity.
And to be honest, it would not be a surprise to have flagrance of sexism or racism (the subject of ethics in AI interests me).
For each I used the code of the lesson: I downloaded images of duckduckgo, I trained the model and noted the accuracy (3 epochs for each. If I increased it was overfitting immediatly)
Here are the results:
white: 88%
black: 92%
asian: 93%
So I have these results and…I’m not sure if I can make any assumptions.
First I don’t know if a 5% difference is something that is worth investissement with so few images. It might be different with 100k images.
Secondly even this difference is significant, I’m not sure about a possible origin of this difference. Because it could be a biais in the duckduck go results, but also it could be a biais in the resnet model and its weights.
I checked some images for each category, to have an intuition about this.

I found that for asian and black woman, the images were more sexualized (especially for asian). So could it be a biais that make for the model to recognize more easily the difference man/woman ? At least more than the “white” research.
What do you think about this ? Could you see some way to improve the methodology ? Or do you have an idea that I couldn’t think of ?
Thanks ! ![]()
1 Like
Yeezy classifier: Yeezy Classifier
MNIST for all digits (working off of ch 4 of textbook)
1 Like
Hello everyonei
It is 1:40 am I finished my first kinda project in deep learning. (I come here and read other people ideas and get energy how awesome and creative the community is).
Here it goes my first side project and hopefully startup (Smile face)
I use first 3 lessons to create an image classifier to classify laboratory equipment. You upload a lab equipment picture it will tell you what equipment it is ? Awesome hun ?
The model has bigger error rate than Jeremy models however it is working pretty good.
Here is list of categories :
labequip_types = ‘pipette’,‘testtube’,‘erlenmeyerflask’,‘beaker’,‘bunsenburner’,‘alcoholburner’,‘syringe’,‘graduatedcylinder’,‘dropper’,‘tongs’,‘stethoscope’,‘thermometer’,‘friabilitytester’,‘pulley’,‘tape’,‘barometer’,‘indicator’,‘stopwatch’,‘speedometer’,‘protractor’,‘dry-cellbattery’,‘magnet’,‘level’,‘balancescale’,‘microscope’,‘telescope’
Here is the link for to test it
https://45016.gradio.app
Here is my screenshot

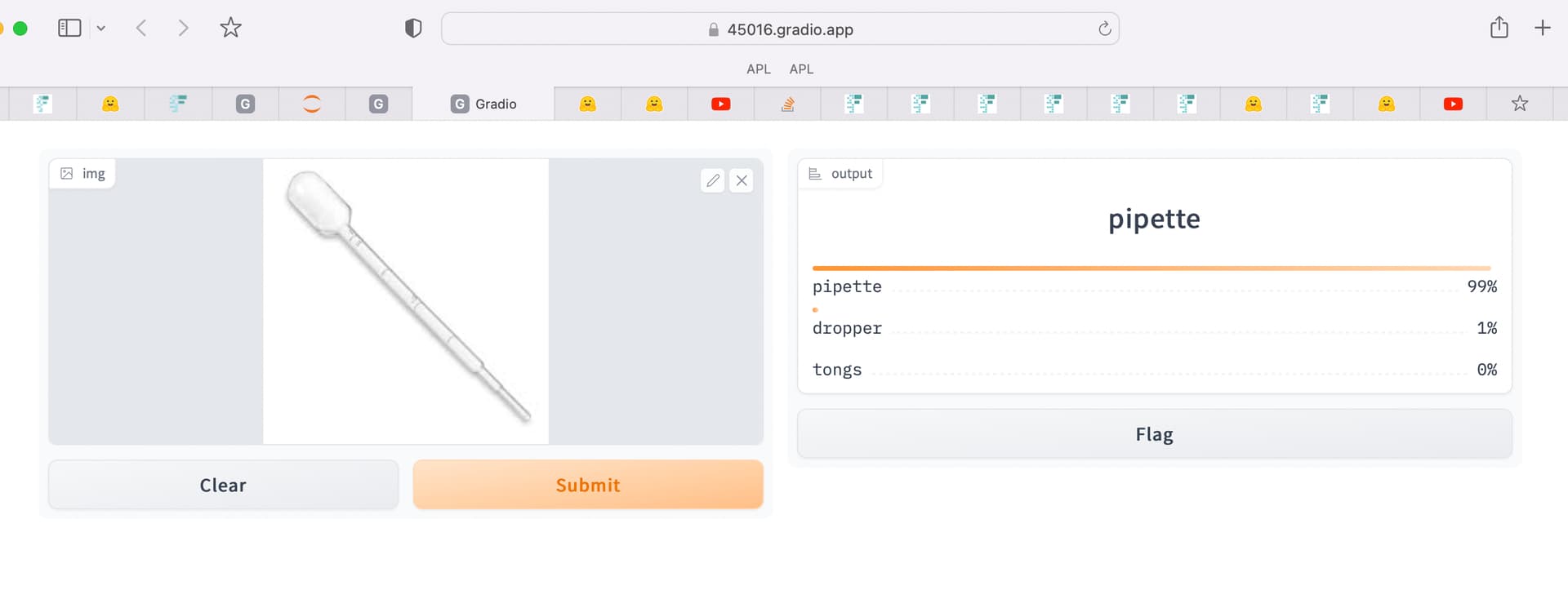
I have to work on the model and cleaning data. The web and mobile application would take time but I am more experienced in web development than deep learning.
If anyone interested in this project and like work with me I love to collaborate and go for VCs. Shot me a message.
I used paperspace and gradio so if anyone need help with one of these I am down to help.
Happy building in public.
My next step3 :
1- Continue the course to learn to improve this model , get familiar with FastAI library and use deep learning to make projects come to my mind (fun or practical one)
1- USE API to make a simple frontend app
2- USE Django restAPI to make web application for this project
3- USE swift to make an iPhone app.
Update 5 am , haha
I thought gradio is first step so I connect to huggingface, it is more accessible now.
link
Lab Equipment Classifier
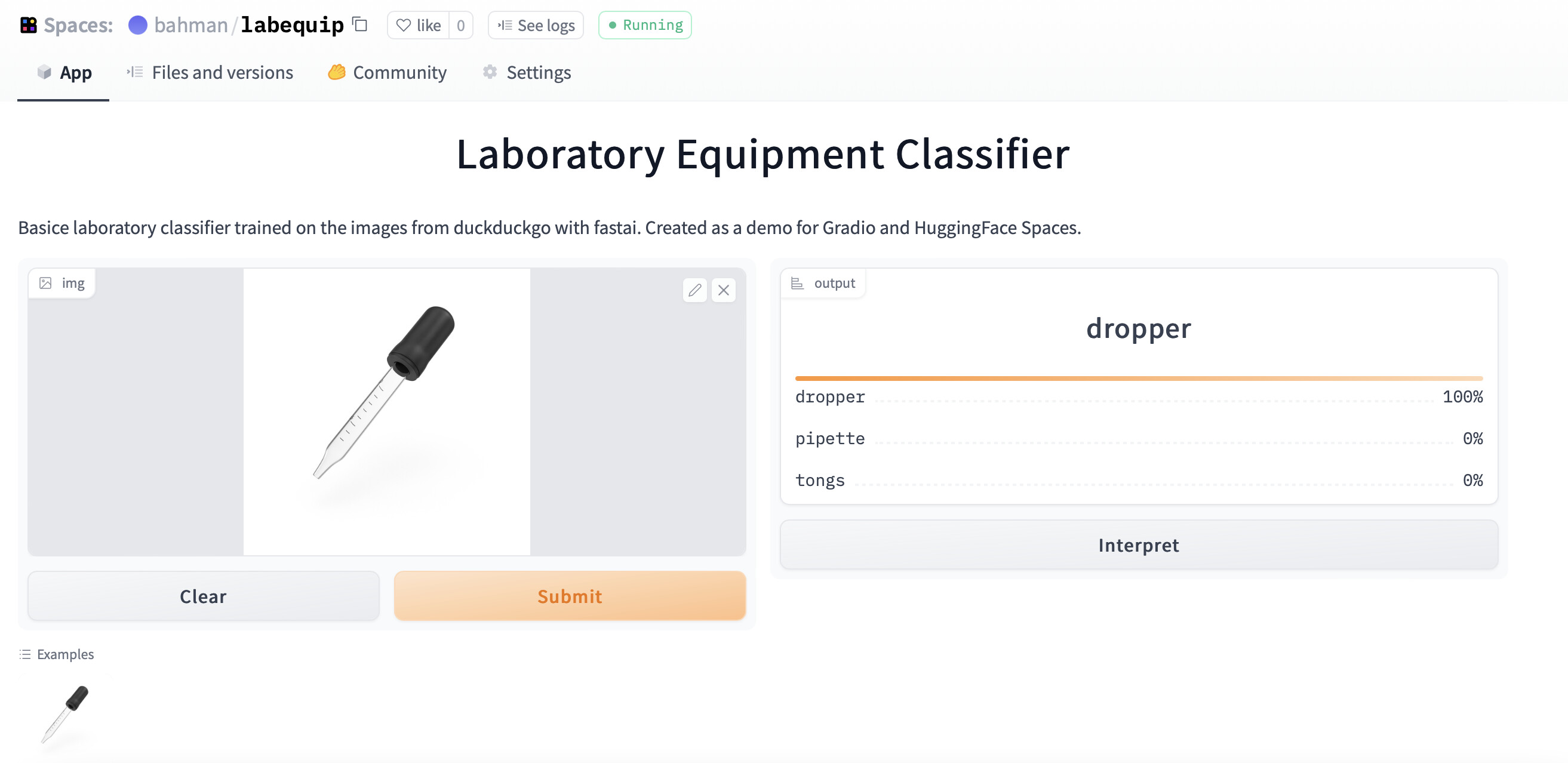
7 Likes
You have more categories than my examples, which makes it a harder problem to solve, so a bigger error rate is expected. Thanks for sharing your work! ![]()
1 Like
As an expat living in New Zealand, the birds here are quite unique and cool. I tweaked the bird/forest binary classifier example to classify a few of my favorite NZ birds: tui, fantail, morepork, kaka, and kereru (also known as the drunken pigeon).
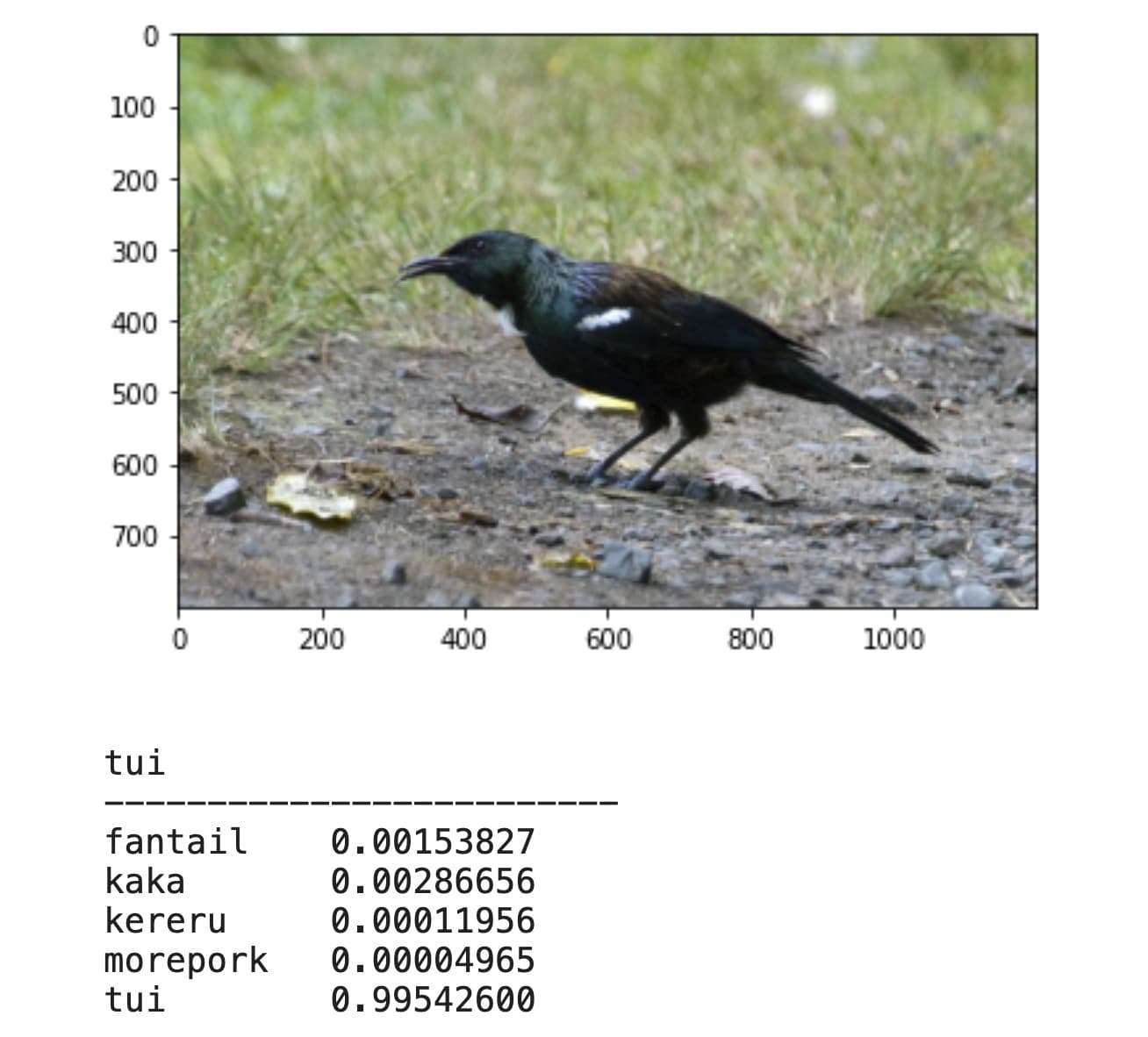
7 Likes
After finishing lesson 2 , I made the legendary Not HotDog app from the T.V show “The Silicon Valley”. I learned a lot about deploying and i’m learning to work with APIs and networking in general so i can turn this and other ideas into mobile Apps using Flutter.

7 Likes
Hello everyone,
This was a fun project that I had tried a few months ago. This project involves Notion API and fastai (for people unfamiliar with Notion, it is a wonderful notes taking tool). I use Notion to journal my thoughts and other ideas, take notes and plan a lot of stuff. I have been journaling in Notion for almost 2 years now. So, when Notion came out with their Notion API, I was too excited to try it out.
After journaling for such a long period of time, I realized that I am just generating a lot of data. Can I put this data to use some how? Then it clicked, I could you this data to finetune a language model which would essentially write like me!
So here are the steps I followed,
- Query the Notion API to get the text
- Use the text to create a dataloader to train the model
- Check the results and move on to the next project

Here is the link to the repository, do check it out, issues and PRs are welcome.
deven367/writes-like-you (github.com)
Thanks for reading!
5 Likes
As a first lession homework I tried to distinguish between Magic: The Gathering, Yugioh!, and Pokémon TCG cards. I got the idea for this notebook from an old project where I and a friend of mine tried to develop a physical classifier of Magic Cards.
Hope you find it interesting.
3 Likes
This is my project following lesson 1 of the new 2022 course. I wondered if I could use image classification to see whether a song would be popular or not using spectrograms.
To gauge popularity I took songs with over 100m listens vs songs that were newly released by new artists that I figured would average as unpopular.
I didn’t have any success initially with small amounts of hand-crafted artisanal spectrograms such as these:

But I seem to have had some joy now that I have over a thousand spectrograms of each category (popular vs unpopular). The model appears to predict a popular track about 75% of the time, I think.
It has worked well on test data I have tried, but I am concerned I might be fooling myself.
Here’s my code and results:

I plan to put this into an app ala lecture 2 and that will make it easier to share.
Be great to get some comments on whether this makes sense and how I might improve the model further.
It’s been fun seeing the top losses. Ed Sheeran’s Nina and One weren’t popular with the model, and neither were Dido’s White Flag and Coldplay’s Clocks.
On the other hand, Jet Plane 5000 by j.flowers.mp3 the model thought was an absolute corker.
So am I fooling myself in some way? That’s my biggest worry.
I would like to increase the resolution beyond 224x224, but I’m not sure how to increase it without breaking the model. The original spectrograms are c2000x2000 (limited to 2mins long to ensure consistency).
Am I using the right architecture? It seems like using a pre-trained model doesn’t make sense for this, so what should I be using?
I’d also like to determine degree of popularity, and I’m wondering how to do that.
Thank you to the people in the community here. It’s been very useful trying to get over blocks. Cheers
6 Likes
What’s your setup to get the popular/unpopular songs?
Hi everyone,
It is amazing to be part of this community! Had a great time reading on the different interesting ideas and getting a lot of help from the forum on many doubts and questions!
I am in the midst of lesson 2 and have built a simple classifier on the aircrafts that are seen during Singapore’s National Day parade happening on 09 August.
Thanks Jeremy for the amazing course!
1 Like
Hi, I’m new here, and I just did the first lesson.
I tried to modify the code from the bird or forest in Kaggle.
My results are pretty hilarious photos xD
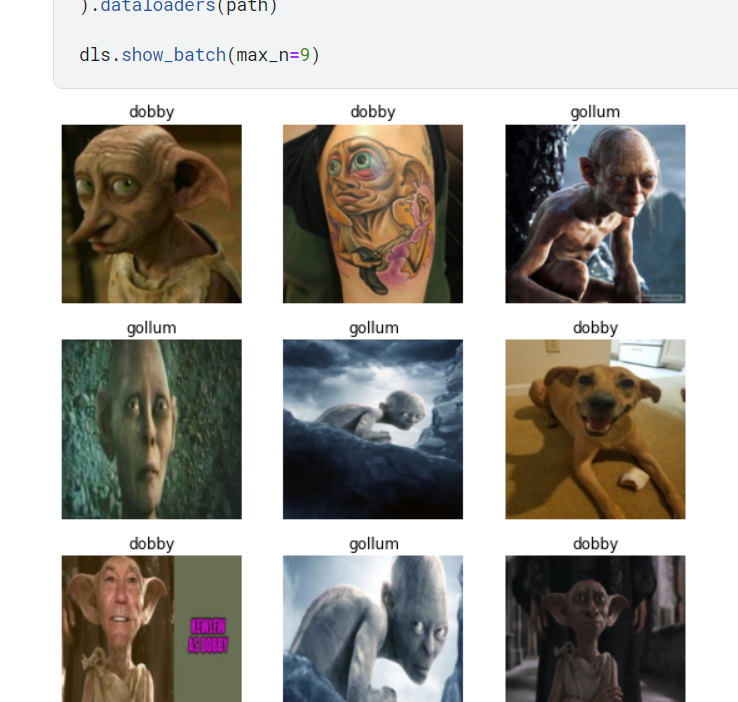
{kind=link}
8 Likes
Haha, it’s curious that a picture of a dog shows up when searching duckduckgo for pictures of Dobby, but I guess that’s a great representation of why we also want to view and verify our data (especially when searching the web).
Nice work!
1 Like
As a lesson 2 homework, I trained an artistic style classifier based on the best-artworks-of-all-time dataset. The model doesn’t perform well in all the cases, mainly due to the non-uniform representation of artistic style for each artist. If you like to draw and want to discover what artist has a style similar to yours, you can check the app on huggingface:
7 Likes
For the homework for lesson 1 I’ve trained two slightly harder classifiers
The cheetah or tiger has has 97% success rate:
The beer or wine glass classifier has 98% success rate:
Considering how many different styles of glasses there are for each category this is particularly impressive.
I’m open to job offers ![]()
1 Like
Attended Lesson:1 of fast.ai course.
For the homework I wanted to experiment on image classes that were very similar to each other to see how accurately the model classifies them.
Therefore I used the keywords “Galaxy Cluster” and “Black Galaxy Granite” (after refining the keywords through trial and error, seeing which search phrase gives the closest results).
Although after each epoch “error_rate” decreases and after the third epoch error is reduced to zero (indicating 100% accuracy)
But when the predict command is given accuracy comes zero.
Am I missing something?
Thank you!
1 Like
I think your model runs successfully and the reason why the output of P(‘galaxy cluster’) = 0 is just because in your last code cell::
print(f"Probability it's galaxy cluster: {probs[0]:.4f}"),
probs[0] is the probability of black galaxy granite and you should change it to probs[1].
Keep coding! ![]()
1 Like
After playing around with Jeremy’s Notebook (Is it a bird?) and reading some posts, I have created my own version image classifier for recognizing 8 different architecture styles commonly in Europe.
For the notebook in Kaggle, I have messed up the Save Versions and I think some images shown are also not nice enough ![]()
Fastai course and the forum it provides are really amazing! Apart from the lesson officially, the living code session is definitely my favorite. ![]()
1 Like